Формат ORC в фабрике данных Azure и синапсе Analytics
применимо к:  Azure синапсе Analytics фабрика данных Azure
Azure синапсе Analytics фабрика данных Azure
Если вам требуется анализировать файлы ORC или записывать данные в формате ORC, следуйте инструкциям, приведенным в этой статье.
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе приведен список свойств, поддерживаемых набором данных ORC.
Ниже приведен пример набора данных ORC в хранилище BLOB-объектов Azure:
Обратите внимание на следующие моменты:
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе приведен список свойств, поддерживаемых источником и приемником ORC.
ORC в качестве источника
ORC в качестве приемника
Поддерживаемые Параметры записи ORC в :
Свойства потока данных для сопоставления
при сопоставлении потоков данных можно читать и записывать данные в формат ORC в следующих хранилищах данных: служба хранилища больших двоичных объектов Azure, Azure Data Lake Storage 1-го поколения и Azure Data Lake Storage 2-го поколения, а также читать формат ORC в Amazon S3.
Указывать на файлы ORC можно либо с помощью набора данных ORC, либо с помощью встроенного набора данных.
Свойства источника
В приведенной ниже таблице перечислены свойства, поддерживаемые источником данных ORC. Эти свойства можно изменить на вкладке Параметры источника.
При использовании встроенного набора данных будут отображаться дополнительные параметры, совпадающие со свойствами, описанными в разделе Свойства набора данных.
Пример источника данных
Связанный сценарий потока данных конфигурации источника ORC:
Свойства приемника
В приведенной ниже таблице перечислены свойства, поддерживаемые приемником ORC. Изменить эти свойства можно на вкладке Параметры.
При использовании встроенного набора данных будут отображаться дополнительные параметры, совпадающие со свойствами, описанными в разделе Свойства набора данных.
| Имя | Описание | Обязательно | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Формат | Формат должен быть orc | yes | orc | format |
| Очистить папку | Указывает, очищается ли конечная папка перед записью | Нет | true или false | truncate |
| File name option (Параметр имени файла) | Формат именования записываемого файла данных. По умолчанию — по одному файлу на секцию в формате part-#####-tid- | Нет | Шаблон: String По одному на секцию: String[] Как данные в столбце: String Вывод в один файл: [‘ ‘] | filePattern partitionFileNames rowUrlColumn partitionFileNames |
Пример приемника
Связанный сценарий потока данных конфигурации приемника ORC:
Использование локальной среды выполнения интеграции
Для копирования посредством локальной среды выполнения интеграции (IR), то есть между локальным и облачным хранилищами данных, если вы не копируете файлы ORC как есть, на компьютере среды выполнения интеграции необходимо установить 64-разрядную JRE 8 (среду выполнения Java) или OpenJDK и Распространяемый пакет Microsoft Visual C++ 2010. Подробные сведения приведены в следующем абзаце.
Для копирования, выполняемой на автономной среде IR с ORC File Serialization/десериализацией, служба находит среду выполнения Java, предварительно проверяя реестр (SOFTWARE\JavaSoft\Java Runtime Environment\
При копировании данных в формат ORC или из него с помощью автономного Integration Runtime и при возникновении ошибки «произошла ошибка при вызове Java, сообщение: Java. lang. OutOfMemoryError: пространство кучи Java«, можно добавить переменную среды на компьютере, где размещена ЛОКАЛЬная среда IR, чтобы настроить минимальный или максимальный размер кучи для виртуальной машины Java, чтобы предоставить такую копию, а затем повторно запустить конвейер.
Русские Блоги
Большие данные: формат хранения файлов Hive-ORC
1. Структура файла ORC
Хранение колонки
Из-за особенностей запроса OLAP, столбчатое хранилище может улучшить производительность запроса, но как это сделать? Это начинается с принципа столбцового хранения.Как видно из рисунка 1, относительно хранения строк, обычно используемого в реляционных базах данных, все элементы каждого столбца сохраняются последовательно при использовании столбцового хранения. Эта функция может привести к следующей оптимизации запроса:

Следует отметить, что ORC необходимо использовать дополнительные ресурсы ЦП для сжатия и распаковки при чтении и записи. Конечно, эта часть потребления ЦП очень мала.
Модель данных
В отличие от Parquet, ORC изначально не поддерживает вложенные форматы данных, но реализует поддержку вложенных форматов посредством специальной обработки сложных типов данных, таких как следующие таблицы кустов:
Файловая структура
Как и в Parquet, ORC-файлы также хранятся в двоичном режиме, поэтому они не могут быть непосредственно прочитаны, ORC-файлы также самоанализируются, они содержат много метаданных, эти метаданные сериализуются изоморфным ProtoBuffer. Файловая структура ORC показана на следующем рисунке, который включает следующие понятия:

В файле ORC хранятся три уровня статистической информации: уровень файла, уровень чередования и уровень группы строк, и все они могут использоваться для определения возможности пропуска определенных данных на основе поисковых ARGuments (условия предиката при нажатии). Статистическая информация включает в себя количество членов и наличие нулевого значения, а некоторая конкретная статистическая информация устанавливается для различных типов данных.
(1)file level
В конце файла ORC будет записана статистика на уровне файлов и статистика столбцов во всем файле. Эта информация в основном используется для оптимизации запросов, а также может выводить результаты для некоторых простых агрегатных запросов, таких как max, min и sum.
(2)stripe level
Файлы ORC будут хранить статистику уровня полосы для каждого поля. Считыватель ORC использует эту статистику, чтобы определить, какие записи полосы необходимо прочитать для запроса. Например, если полоса имеет поля max (a) = 10 и min (a) = 3, то когда условие where равно> 10 или = 1000)
whether to create row indexes
Три, операция Java ORC
Перейдите на официальный сайт https://orc.apache.org, чтобы загрузить исходный пакет orc, затем скомпилируйте и получите orc-core-1.3.0.jar, orc-mapreduce-1.3.0.jar, orc-tools-1.3.0.jar Добавьте его в проект
В большинстве случаев все еще рекомендуется преобразовывать текстовые файлы в формат ORC в Hive. Этот тип генерации файлов ORC локально с помощью JAVA относится к сценариям особых потребностей.
Форматы файлов в Big Data: ORC
Optimized Row Columnar (ORC) — это оптимизированный строково-столбчатый файловый формат, предлагающий эффективный способ хранения данных. Целью его разработки было преодоление ограничения других форматов. ORC хранит данные в максимально компактном виде, пропуская ненужные детали. При этом формат не требует построения сложных и больших индексов, обслуживаемых вручную.
Давайте посмотрим, какие существуют преимущества у этого формата: 1. Один файл на выходе любой задачи — это снижает нагрузку на узел имен (NameNode). 2. Поддерживается тип данных Hive, включая DateTime. Также поддерживаются сложные и десятичные типы данных (list, map, struct, union). 3. Возможно одновременное считывание того же файла различными процессами RecordReader. 4. Можно разделить файлы без сканирования этих файлов на предмет наличия маркеров. 5. Оценивается максимально возможное выделение памяти кучи на процессы чтения и записи в футере файла. 6. Сохранение метаданных осуществляется в бинарном формате сериализации Protocol Buffers, а этот формат, как известно, позволяет добавлять/удалять поля.
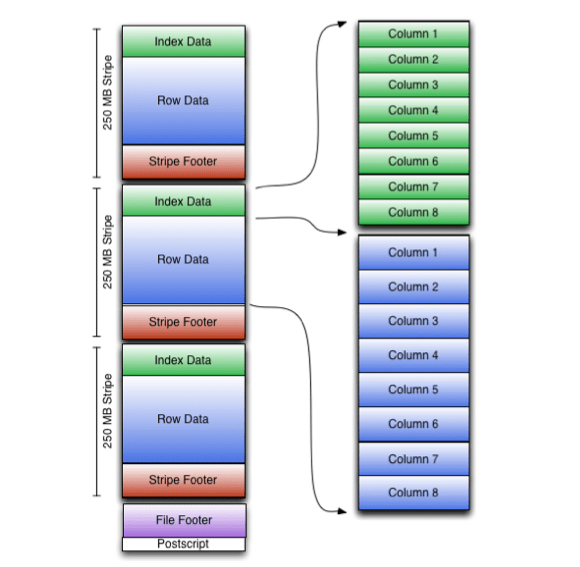
Формат ORC осуществляет хранение коллекции строк в одном файле, причем внутри коллекции хранение строчных данных реализуется в столбчатом формате.
Также ORC-файл хранит группы строк, называемых полосами (stripes), плюс он хранит дополнительную информацию в футере. В конце файла есть postscript, содержащий параметры сжатия, а также размер сжатого футера.
Размер полосы по дефолту — 250 Мб. Благодаря этому, чтение из HDFS производится эффективнее, т. к. осуществляется это чтение большими непрерывными блоками.
Что касается футера файла, то в нем записан список файловых полос, число строк на полосу, а также тип данных по каждому столбцу. Кроме этого, там же отмечено результирующее значение count, max, min и sum, причем по каждому столбцу.
Каталог местоположений потока находится в футере полосы. Строчные данные применяются в процессе сканирования таблиц.
Еще существуют индексные данные, включающие минимальные и максимальные значения как для каждой позиции строк в столбце, так и для каждого столбца. На практике ORC-индексы применяются лишь для выбора полос и групп строк и не применяются для ответов на запросы.
О сравнении форматов хранения в Hadoop: начнем с ORC
В Hadoop входят продукты, которые могут работать с файлами разных форматов. Я неоднократно искал, читал и думал над тем — какой же формат лучше. Относительно случайно столкнувшись с форматом ORC, заинтересовался, почитал (и даже чуть покодил) и вот что понял — сравнивать форматы как таковые некорректно. Точнее, их обычно сравнивают, на мой взгляд, некорректным образом. Собственно, статья об этом, а также о формате Apache ORC (в техническом плане) и предоставляемых им возможностях.
Начну с вопроса: каким может быть размер реляционной таблицы (в байтах и очень примерно), состоящей из 10 тысяч строк (по два целых поля в строке)? Обычно здесь ставят кат, а ответ помещают под катом — я отвечу здесь: 628 байт. А детали и историю перенесу под кат.
Как все началось: собрал я библиотеку для работы с Apache ORC (см. заглавную страницу проекта — https://orc.apache.org) и скомпилировал их же пример про запись в ORC (что голову ломать — начинаем с того, что работает), это в нем было 2 поля и 10 тысяч строк. Запустил — получил orc-файл, поскольку делал я это где-то не в офисе — на всякий случай переписал библиотеку и файл на флэшку (торопился — не стал смотреть размер, думаю, флэшка-то выдержит).
Но как-то быстро переписалось… Посмотрел на размер — 628 байт. Подумал — ошибка, сел и начал разбираться. Запустил утилиту для просмотра ORC из той же собранной библиотеки — содержимое файла показывает, все честно — 10 тысяч строк. Вот после этого я и призадумался — как может 10 тысяч строк влезть в 628 байт (я к тому времени уже немного знал про ORC и понимал, что там есть еще и метаданные — формат же самодостаточный). Разобрался, делюсь.
О формате ORC

Не буду повторять здесь общие слова про формат — см. ссылку выше, там хорошо написано. Сфокусируюсь на двух прилагательных в превосходной форме с картинки выше (картинка взята с заглавной страницы проекта): давайте попробуем разобраться — почему ORC «самый быстрый» и «самый компактный».
Скорость
Скорость бывает разная, применительно к данным — как минимум скорость чтения или записи (можно углубляться и дальше, но давайте пока остановимся). Поскольку в лозунге выше явно упоминается Hadoop, то рассматривать будем прежде всего скорость чтения.
Процитирую еще немного из документации ORC:
It is optimized for large streaming reads, but with integrated support for finding required rows quickly. Storing data in a columnar format lets the reader read, decompress, and process only the values that are required for the current query.
Размер
Тут цитаты не нашлось, скажу своими словами
Предоставление возможностей
Хочу обратить Ваше внимание на формулировки из цитат выше: «оптимизирован под. «, «содержит поддержку. «, «позволяет производить чтение. » — формат файла, как язык программирования, является средством (в данном случае, обеспечения эффективного хранения и доступа к данным). Будет ли хранение и доступ к данным действительно эффективными зависит не только от средства, но и от того, кто и как этим средством пользуется.
Давайте посмотрим — какие возможности для обеспечения скорости и компактности предоставляет формат.
Колончатое хранение и страйпы
Данные в ORC хранятся в виде колонок, прежде всего это влияет на размер. Для обеспечения скорости потокового чтения файл разбит на так называемые «страйпы» (stripes), каждый страйп является самодостаточным, т.е. может быть прочитан отдельно (а, следовательно, параллельно). Из-за страйпов размер файла увеличится (не уникальные значения колонок будут храниться несколько раз — в тех страйпах, где такие значения встречаются) — тот самый баланс «скорость — размер» (он же компромисс).
Индексы
Формат ORC подразумевает индексы, позволяющие определить — содержит ли страйп (а точнее — части страйпа по 10 тысяч строк, так называемые «row group») искомые данные или нет. Индексы строятся по каждой из колонок. Это влияет на скорость чтения, увеличивая размер. При потоковом чтении индексы, кстати, можно и не читать.
Сжатие
Все метаданные хранятся в сжатом виде, а это
(ниже мы увидим, что метаданные составляют существенную часть файла)
Значения колонок также хранятся в сжатом виде. При этом обеспечивается возможность чтения и распаковки только того блока данных, который нужен (т.е. сжимается не файл и не страйп целиком). Сжатие влияет и на размер, и на скорость чтения.
Кодирование
Значения колонок — а файл хранит именно эти значения — хранятся в кодированном виде (encoded). В текущей версии формата (ORC v1) для целых чисел, например, доступно 4 варианта кодирования. При этом кодируется не вся колонка целиком, кодируются части колонки, каждая часть может быть закодирована оптимальным для этой части образом (такие части в спецификации называют «run»-ом). Таким образом достигается минимизация суммарной длины хранимых данных. Опять же влияние на размер и на скорость.
Посмотрим ORC файл
Давайте очень кратко посмотрим — что внутри ORC файла (того самого — 628 байт). Для тех, кого не очень интересуют технические детали — пролистайте до следующего раздела (про сравнение форматов).
Вот так определялась наша таблица в примере записи в ORC:
Метаданные
Информация о длинах (я привожу скриншоты jupyter notebook, думаю, достаточно понятно)
Что мы здесь видим:
Обратим внимание здесь на соотношение объема данных и метаданных (276 к 352 байт). Но эти 276 байт данных — тоже не только данные, данные содержат немного «лишнего» (здесь для краткости не привожу скриншоты — с ними длинно получается, обойдусь только своими комментариями), что входит в данные:
Потоки PRESENT — это битовые строки, позволяющие понять — где в колонках стоят NULL. Для нашего примера их присутствие выглядит странно (в статистике нашего файла явно написано, что NULL-ов в данных нет — зачем тогда включать PRESENT? Похоже на недоработку. )
Итого собственно данные занимают 216 байт, метаданные — 352.
Также из метаданных видно, что обе колонки закодированы с помощью DIRECT_V2 метода (для целых он допускает 4 вида представления, за деталями отсылаю к спецификации — она есть на сайте проекта).
Данные
Посмотрим (опять без скриншотов для краткости), как же 10 тысяч чисел поместилось в 103 байта (для колонки «x»):
Завершая обзор представления нашей простой таблицы в файле скажу, что индексы в этом примере вырождены — указывают на начало потока данных. С индексами я разберусь на реальных примерах, возможно, опишу в отдельной статье.
Для интересующихся: по ссылке можно найти jupyter notebook, в котором я «разбирался» во внутренностях формата. Можно им воспользоваться и повторить (ORC файл там тоже приложен).
Уверен, что многие читатели «потерялись» — да, формат ORC не является простым (как в плане понимания деталей, так и в плане использования предоставляемых возможностей).
О сравнении форматов
Теперь перейдем к главному — некорректности сравнения форматов.
Как часто сравнивают форматы: давайте сравним размер файлов в формате А и Б, скорость чтения (разных видов чтения — случайное, потоковое и т.п.) в формате А и Б. Сравнили, сделали вывод — формат А лучше формата Б.
На примере последнего из перечисленных выше средств обеспечения компактности (кодирования): можно ли в ORC закодировать данные оптимальным образом? Да, возможности есть — см. выше. Но точно также можно этого и не делать! Это зависит от «писателя» (writer в терминологии ORC): в приведенном выше примере писатель это смог сделать. Но он мог бы просто записать 2 раза по 10 тысяч чисел и это тоже было бы корректно с точки зрения формата. Сравнивая форматы «на размер» мы сравниваем не только и не столько форматы, сколько алгоритмическое качество использующих эти форматы прикладных систем.
Кто есть «писатель» в Hadoop? Их много — например, Hive, который создает таблицу, хранящую свои данные в файлах в формате ORC. Сравнивая, к примеру, ORC с Parquet-ом в Hadoop, мы на самом деле оцениваем качество реализации алгоритма преобразования данных, реализованного в Hive. Мы не сравниваем форматы (как таковые).
Важная особенность Hadoop
В классическом реляционном мире у нас не было никакой возможности повлиять на размер таблицы в Oracle — она как-то хранилась и только Oracle знал — как. В Hadoop ситуация чуть другая: мы можем посмотреть — как хранится та или иная таблица (насколько хорошо у Hive, например, получилось ее «закодировать»). И, если мы видим, что это можно улучшить, — у нас есть для этого реальная возможность: создать свой более оптимальный ORC файл и дать его Hive-у в качестве внешней таблицы.
Сравним ORC и QVD
Я недавно описал формат QVD, который активно используется QlikVew/QlikSense. Давайте для иллюстрации очень кратко сравим эти два формата с точки зрения возможностей, которые они предоставляют для достижения максимальной скорости чтения и минимизации размера. Возможности ORC описаны выше, что у QVD:
Колончатое хранение
QVD может считаться «колончатым» форматом, в нем нет дублирования значений колонок — уникальные значения хранятся один раз. НО он не допускает параллельной обработки — сначала необходимо полностью считать значения всех колонок, потом можно параллельно читать строки.
А дублирование есть на уровне строк — строки хранят повторяющиеся значения индекса в таблице символов.
Сжатие
Не сталкивался со сжатыми QVD файлами — не довелось — тэг такой в метаданных есть, возможно, каждая из частей, про которую в метаданных есть смещение и длина (а это — каждая таблица символов и вся таблица строк), может быть сжата. В этом случае параллельное чтение строк — «давай до свиданья».
Индексы
В QVD файле нет возможности понять — какую его часть необходимо читать. На практике приходится побайтово разбирать таблицу символов (каждую!), не очень эффективный способ.
Кодирование
Кодирование в QVD не применяется, можно провести аналогию битового индекса в таблице строк с кодированием, но эта аналогия «компенсируется» дублированием чисел строками в таблицах символов (детали — см. в статье, кратко — значение колонки часто представлено числом И строкой).
Вывод по этому краткому сравнению у меня лично получился такой — формат QVD практически не содержит возможностей, позволяющих компактно хранить и быстро читать содержащиеся в файлах этого формата данные.
(Прозвучало как-то обидно для QVD, чуть дополню — формат был создан очень давно, используется только QlikView/QlikSense, а они «хранят» все данные в памяти. Я думаю, что QVD файл просто читается весь «как есть» в память, а далее эти замечательные во всех отношениях BI продукты очень быстро работают с этим представлением — тут они мастера. )
Вместо заключения
Покритиковал и ничего пока не предложил… — предлагаю.
Мне представляется, что сравнивать форматы нужно не на примере их конкретной реализации, сравнивать форматы нужно с точки зрения входящих в них инструментальных средств и возможности использовать эти средства для решения наших конкретных задач. Скорость работы работы процессоров постоянно растет, сейчас мы можем себе позволить практически любые алгоритмы преобразования данных после того, как они считаны — все равно чтение с диска будет медленнее. Именно поэтому «выразительные средства» форматов важны.
Выше я кратко перечислил интересные, на мой взгляд, возможности формата ORC. У меня еще нет статистики по тому, как обстоит дело на практике (какие из этих возможностей и в какой мере используются Hive-ом, например). Когда появится — напишу. В ближайших планах сделать подобный обзор другого популярного формата хранения — Parquet.
Ну и — совсем в заключение — в современном мире очень много информации, к сожалению, часть этой информации является слишком поверхностной. Не будем поддаваться, будем смотреть в суть.
Русские Блоги
csv, parquet, orc чтение и запись производительность и методы
Недавно я работал над проектом платформы для анализа больших данных. В процессе разработки проекта для расчета каждого шага расчета в проекте рабочего процесса использовалась искра. Многократная отправка вычислений с отправкой в виде искры представляла собой работу. Расчет процесса. Среди них csv используется в качестве промежуточного файла хранения результатов между несколькими этапами вычислений, но csv как метод хранения несжатого текста, очевидно, имеет некоторую производительность, поэтому я хочу найти формат файла, который хранит файлы более эффективно или работает более эффективно. Как альтернатива.
Способ хранения
csv
Файл данных csv относится к режиму хранения текста. Spark поддерживает его по умолчанию и записывает его в файл в соответствии с текстом. Каждая строка имеет одну запись. Вообще говоря, метод хранения текста несжатый, а производительность относительно высокая. разница.
Первоначально паркет был вдохновлен статьей Dremel, опубликованной Google в 2010 году. В статье представлен формат хранения, который поддерживает вложенные структуры и использует столбцовое хранилище для повышения производительности запросов. В статье Dremel также рассказывается, как Google использует это. Один вид формата хранения реализует параллельный запрос, если вы заинтересованы в этом, вы можете обратиться к статье и реализации с открытым исходным кодом Drill.
Файлы паркета хранятся в двоичном формате и не могут быть непосредственно прочитаны и изменены. Файлы паркета разбираются автоматически, а данные и метаданные файла включаются в файл. В файловой системе HDFS и файлах Parquet существуют следующие концепции:
Блок HDFS (Блок): это самая маленькая единица копирования в HDFS. HDFS будет хранить блок в локальном файле и поддерживать несколько копий, разбросанных по разным машинам. Обычно размер блока составляет 256 МБ. 512M и т. Д.
Файл HDFS (Файл). Файл HDFS, включая данные и метаданные, данные распределяются и хранятся в нескольких блоках.
Группа строк: данные физически разделены на несколько блоков в соответствии со строками. Каждая группа строк содержит определенное количество строк. По крайней мере одна группа строк хранится в файле HDFS, Parquet При чтении и записи вся группа строк кэшируется в памяти, поэтому, если размер каждой группы строк определяется размером памяти.
Блок столбцов: каждый столбец в группе строк хранится в блоке столбцов, а все столбцы в группе строк постоянно хранятся в этом файле группы строк. Различные блоки столбцов могут использовать разные алгоритмы сжатия.
Страница (Страница): каждый блок столбца разделен на несколько страниц, одна страница является наименьшей единицей кодирования, и разные методы кодирования могут использоваться на разных страницах одного и того же блока столбца.
При нормальных обстоятельствах при хранении данных Parquet размер группы строк будет установлен в соответствии с размером блока HDFS, поскольку в общем случае наименьшая единица данных, обрабатываемая каждой задачей Mapper, представляет собой блок, поэтому Каждая группа строк может быть обработана задачей Mapper для увеличения параллелизма выполнения задачи. Формат файла Parquet показан на рисунке ниже.
Можно видеть, что информация об индексе метаданных в формате хранения сохраняется в конце, поэтому при чтении строки данных вам нужно найти последнюю информацию об индексе, и, наконец, вы можете прочитать соответствующие данные строки.
Файл ORC: обычный двоичный файл, хранящийся в файловой системе. Файл ORC может содержать несколько полос, и каждая полоса содержит несколько записей. Эти записи хранятся независимо в соответствии со столбцами, что соответствует концепции группы строк в Parquet.
Метаданные на уровне файлов: включая информацию описания файла PostScript, метаинформацию файла (включая статистическую информацию всего файла), всю информацию о полосах и информацию о схеме файлов.
Полоса : группа строк образует полосу. Каждый раз, когда файл читается, блок представляет собой группу строк, которая обычно представляет собой размер блока HDFS, в котором хранятся индекс и данные каждого столбца.
метаданные полосы: сохраните положение полосы, статистику каждого столбца в полосе и все типы и позиции потока.
Группа строк : наименьшая единица индекса, полоса содержит несколько групп строк, значение по умолчанию состоит из 10000 значений.
Поток : поток представляет собой часть допустимых данных в файле, включая индекс и данные. Индексный поток хранит положение и статистическую информацию каждой группы строк. Поток данных включает в себя несколько типов данных, и конкретный тип зависит от типа столбца и метода кодирования.
Разница с паркетом заключается в том, что в начале каждой строки данных будет указана информация об индексе данных индекса.По сравнению с паркетом, который помещает информацию об индексе в конце, теоретическая скорость чтения в восходящем направлении немного выше.
Размер хранилища (эффективность хранения)
Операционная среда кластера:
5 комплектов / память: 24G / ядро: 16 ядер
Данные одинаковы, преобразованы из CSV в следующие различные форматы, эффективность чтения и записи выглядит следующим образом:
| формат | размер | Время чтения и записи | отсчет времени работы |
| csv | 36G | 3.6min | 59s |
| parquet | 6G | 1.1min | 5s |
| orc | 5.9G | 1.2min | 5s |
| avro | 13G | 1.3min | 25s |
Размер: видно, что по сравнению с csv, parque и orc напрямую уменьшают размер в 6 раз. Теоретически он может достичь 6-10-кратной эффективности сжатия. В этот раз использовался метод сжатия gzip по умолчанию для паркета.
время: стоит отметить, что для метода работы со столбцами count, parquet, orc и avro достигли довольно хороших результатов. Можно предположить, что этот набор данных не нужен для расчета, а используются только некоторые столбцы. Можно рассчитать, уменьшив масштаб расчета.
Читать и писать код
1. csv слишком распространен и здесь будет опущен
Но, конечно, avro использует блоки данных для чтения, а не забывает добавить зависимость maven для блоков данных.
вывод
csv широко используется, большинство систем ввода имеет формат csv, кроме того, файл csv можно понимать и читать напрямую, а файл csv также поддерживает добавление данных в конце, но файл csv Поскольку сжатие отсутствует, объем большой, а некоторые операции не так хороши, как хранение в столбцах.
Паркет также широко используется. По умолчанию используется сжатие gzip, которое является более громоздким и более эффективным. Однако паркет не может быть понят и прочитан, потому что он использует двоичное хранилище. Когда в системе нет особых требований, файлы данных должны быть открыты. В погоне за эффективностью, вы можете рассмотреть.
orc также представляет собой список сохраненных двоичных файлов, которые не могут быть непосредственно поняты и поняты при открытии, но потому что в формате файлов каждый блок строк имеет легкий индекс в начале, поэтому по сравнению с паркетом, при поиске строк, orc Скорость относительно быстрее,
Другие форматы
Существуют и другие форматы: indexR / ya100
Цитируемая статья выглядит следующим образом:



