Иллюстрированный самоучитель по работе в Internet
Сетевые приложения
Существует два типа сетевых приложений: чисто сетевые (pure) и обособленные (standalone). Чисто сетевые приложения разработаны для применения в сетях. Использование их на отдельных компьютерах не имеет смысла. Наоборот, обособленные приложения призваны работать на отдельном компьютере. Для расширения возможностей они перестроены для работы в сетях. Примерами обособленных приложений могут служить текстовый процессор и редактор электронных таблиц.
Чисто сетевые приложения
Эти приложения были созданы для использования возможностей сетей. Каждое из них имеет свой отдельный пользовательский интерфейс и требует выполнения некоторой последовательности «сетевых» команд, индивидуальных для каждого приложения.
Ниже приведены некоторые примеры чисто сетевых приложений:
Эмуляция терминала была одним из первых чисто сетевых приложений. До появления сетей терминалы использовались для доступа к прикладным программам на больших ЭВМ и миникомпьютерах. Когда на смену терминалам пришли ПК, потребовался метод доступа к прикладным программам на существующих больших ЭВМ и миникомпьютерах. Программа эмуляции терминала позволяет представить ПК для большой ЭВМ как подключенный к ней терминал. Функции центрального процессора (ЦП) ПК становятся прозрачными для пользователя, и ему кажется, что он работает с ЦП большой ЭВМ, к которой данный ПК подсоединен. Эмуляция терминала предоставляет пользователю преимущества двух сред компьютерного мира. Приложения больших ЭВМ и миникомпьютеров могут выполняться на ПК наряду с обычными обособленными приложениями типа текстовых процессоров и электронных таблиц.
Передача файла является основным приложением практически во всех сетях. В некоторых случаях файлы, передаваемые от ПК одного типа к ПК другого типа, требуют перевода из одного формата данных в другой.
Электронная почта дает возможность пользователю ввести сообщение на ПК или локальной рабочей станции и оправить его к кому-нибудь по сети. Электронная почта является, возможно, одним из наиболее важных сетевых приложений. Она предоставляет путь, по которому сеть может улучшить межкорпоративные коммуникации.
Групповые приложения используют сети для электронной автоматизации административных функций современного офиса. Большинству крупных офисов присущи бесконечные попытки администраторов скоординировать работу. Групповые приложения позволяют пользователям координировать календарь, встречи, телефонные звонки и другие задачи электронным путем. Они могут предлагать чисто сетевые либо обособленные административные функции. Например, групповые приложения могут включать электронную почту как средство отправления и получения сообщений между сотрудниками. Так же может использоваться календарь для координации расписания работы сотрудников. Групповые приложения стремятся интегрировать эти функции без потерь для каждой из них.
Обособленные приложения
Все приложения, описанные выше, являются чисто сетевыми приложениями, разработанными для функционирования в сетевой среде. В последнее время многие известные обособленные приложения были адаптированы для функционирования в среде клиент-сервер.
Примерами могут служить текстовые процессоры, редакторы электронных таблиц, базы данных, презентационная графика и управление проектами.
Когда обособленные приложения адаптируются для работы в сетевой среде, они разбиваются на две части.
Первая часть приложения включает пользовательский интерфейс и связующую обработку и работает на станции-клиенте. Вторая часть приложения, работающая на сервере, включает операции, требующие значительных процессорных затрат.
Поводом к переводу традиционных обособленных приложений в сетевую среду послужили следующие соображения:
В сетевых версиях приложений используется тот же пользовательский интерфейс, включая команды оператора, что и в предыдущих обособленных версиях. В отличие от чисто сетевых приложений пользователям нет необходимости изучать новые команды для обеспечения нормальной работы.
Пользователи могут получать доступ к важным файлам, таким, как большие базы данных, сохраняемым в общем разделяемом пространстве. Поскольку только одна копия файла существует на сервере, то исчезает опасность дублирования файлов с различными датами модификации.
Некоторые ПК с ограниченными ресурсами (медленный ЦП, малая память) не могут обрабатывать целиком современные большие приложения. Однако если приложение разбивается на две части, то ПК может обрабатывать одну из этих частей, что известно как архитектура «клиент-сервер». Персональный компьютер («клиент») в общем случае обрабатывает часть пользовательского интерфейса от всего приложения, а более мощный компьютер («сервер») обрабатывает интенсивную процессорную часть и ввод/вывод (В/В) информации.
Новое серверное приложение не требуется для каждого пользователя. Если приложение уже существует на сервере, то новая часть пользовательского интерфейса для клиента – это все, что необходимо. Это обычно более дешево, чем использование всей программы для каждого пользователя.
Как работают веб-приложения
1. Чем веб-приложения отличаются от сайтов
Для меня сайт это в первую очередь что-то информационное и статичное: визитка компании, сайт рецептов, городской портал или вики. Набор подготовленных заранее HTML-файлов, которые лежат на удаленном сервере и отдаются браузеру по запросу.
Сайты содержат различную статику, которая как и HTML-файл не генерируется на лету. Чаще всего это картинки, CSS-файлы, JS-скрипты, но могут быть и любые другие файлы: mp3, mov, csv, pdf.
Блоги, визитки с формой для контакта, лендинги с кучей эффектов я тоже отношу для простоты к сайтам. Хотя в отличие от совсем статических сайтов, они уже включают в себя какую-то бизнес-логику.
А веб-приложение — это что-то технически более сложное. Тут HTML-страницы генерируются на лету в зависимости от запроса пользователя. Почтовые клиенты, соцсети, поисковики, интернет-магазины, онлайн-программы для бизнеса, это все веб-приложения.
2. Какие бывают веб-приложения
Веб-приложения можно разделить на несколько типов, в зависимости от разных сочетаний его основных составляющих:
3. Pyhon-фреймворк Django aka бэкенд

В разработке фреймворк — это набор готовых библиотек и инструментов, которые помогают создавать веб-приложения. Для примера опишу принцип работы фреймворка Django, написанного на языке программирования Python.
Первым этапом запрос от пользователя попадает в роутер (URL dispatcher), который решает какую функцию для обработки запроса надо вызвать. Решение принимается на основе списка правил, состоящих из регулярного выражения и названия функции: если такой-то урл, то вот такая функция.
Функция, которая вызывается роутером, называется вью (view). Внутри может содержаться любая бизнес-логика, но чаще всего это одно из двух: либо из базы берутся данные, подготавливаются и возвращаются на фронт; либо пришел запрос с данными из какой-то формы, эти данные проверяются и сохраняются в базу.
Данные приложения хранятся в базе данных (БД). Чаще всего используются реляционные БД. Это когда есть таблицы с заранее заданными колонками и эти таблицы связаны между собой через одну из колонок.
Данные в БД можно создавать, читать, изменять и удалять. Иногда для обозначения этих действий можно встретить аббревиатуру CRUD (Create Read Update Delete). Для запроса к данным в БД используется специальный язык SQL (structured query language).
В Джанго для работы с БД используются модели (model). Они позволяют описывать таблицы и делать запросы на привычном разработчику питоне, что гораздо удобнее. За это удобство приходится платить: такие запросы медленнее и ограничены в возможностях по сравнению с использованием чистого SQL.
Полученные из БД данные подготавливаются во вью к отправке на фронт. Они могут быть подставлены в шаблон (template) и отправлены в виде HTML-файла. Но в случае одностраничного приложения это происходит всего один раз, когда генерируется HTML-страница, на который подключаются все JS-скрипты. В остальных случаях данные сериализуются и отправляются в JSON-формате.
4. Javascript-фреймворки aka фронтенд
Клиентская часть приложения — это скрипты, написанные на языке программирования Javascript (JS) и исполняемые в браузере пользователя. Раньше вся клиентская логика основывалась на использовании библиотеки JQuery, которая позволяет работать с DOM, анимацией на странице и делать AJAX запросы.
DOM (document object model) — это структура HTML-страницы. Работа с DOM — это поиск, добавление, изменение, перемещеие и удаление HTML-тегов.
AJAX (asynchronous javascript and XML) — это общее название для технологий, которые позволяют делать асинхронные (без перезагрузки страницы) запросы к серверу и обмениваться данными. Так как клиентская и серверная части веб-приложения написаны на разных языках программирования, то для обмена информацией необходимо преобразовывать структуры данных (например, списки и словари), в которых она хранится, в JSON-формат.
JSON (JavaScript Object Notation) — это универсальный формат для обмена данными между клиентом и сервером. Он представляет собой простую строку, которая может быть использована в любом языке программирования.
Сериализация — это преобразование списка или словаря в JSON-строку. Для примера:
Десериализация — это обратное преобразование строки в список или словарь.
С помощью манипуляций с DOM можно полностью управлять содержимым страниц. С помощью AJAX можно обмениваться данными между клиентом и сервером. С этими технологиями уже можно создать SPA. Но при создании сложного приложения код фронтенда, основанного на JQuery, быстро становится запутанным и трудно поддерживаемым.
К счастью, на смену JQuery пришли Javascript-фреймворки: Backbone Marionette, Angular, React, Vue и другие. У них разная философия и синтаксис, но все они позволяют с гораздо большим удобством управлять данными на фронтенде, имеют шаблонизаторы и инструменты для создания навигации между страницами.
HTML-шаблон — это «умная» HTML-страница, в которой вместо конкретных значений используются переменные и доступны различные операторы: if, цикл for и другие. Процесс получения HTML-страницы из шаблона, когда подставляются переменные и применяются операторы, называется рендерингом шаблона.
Полученная в результате рендеринга страница показывается пользователю. Переход в другой раздел в SPA это применение другого шаблона. Если необходимо использовать в шаблоне другие данные, то они запрашиваются у сервера. Все отправки форм с данными это AJAX запросы на сервер.
5. Как клиент и сервер общаются между собой
Общение клиента с сервером происходит по протоколу HTTP. Основа этого протокола — это запрос от клиента к серверу и ответ сервера клиенту.
Для запросов обычно используют методы GET, если мы хотим получить данные, и POST, если мы хотим изменить данные. Еще в запросе указывается Host (домен сайта), тело запроса (если это POST-запрос) и много дополнительной технической информации.
Современные веб-приложения используют протокол HTTPS, расширенную версию HTTP с поддержкой шифрования SSL/TLS. Использование шифрованного канала передачи данных, независимо от важности этих данных, стало хорошим тоном в интернете.
Есть еще один запрос, который делается перед HTTP. Это DNS (domain name system) запроc. Он нужен для получения ip-адреса, к которому привязан запрашиваемый домен. Эта информация сохраняется в браузере и мы больше не тратим на это время.
Когда запрос от браузера доходит до сервера, он не сразу попадает в Джанго. Сначала его обрабатывает веб-сервер Nginx. Если запрашивается статический файл (например, картинка), то сам Nginx его отправляет в ответ клиенту. Если запрос не к статике, то Nginx должен проксировать (передать) его в Джанго.
К сожалению, он этого не умеет. Поэтому используется еще одна программа-прослойка — сервер приложений. Например для приложений на питоне, это могут быть uWSGI или Gunicorn. И вот уже они передают запрос в Джанго.
После того как Джанго обработал запрос, он возвращает ответ c HTML-страницей или данными, и код ответа. Если все хорошо, то код ответа — 200; если страница не найдена, то — 404; если произошла ошибка и сервер не смог обработать запрос, то — 500. Это самые часто встречающиеся коды.
6. Кэширование в веб-приложениях

Еще одна технология, с которой мы постоянно сталкиваемся, которая присутствует как веб-приложениях и программном обеспечении, так и на уровне процессора в наших компьютерах и смартфонах.
Cache — это концепция в разработке, когда часто используемые данные, вместо того чтобы их каждый раз доставать из БД, вычислять или подготавливать иным способом, сохраняются в быстро доступном месте. Несколько примеров использования кэша:
Начинающему сетевому программисту
В общем, посмотрев на всё это, я решил написать базовую статью по созданию простейшего клиент-сервер приложения на С++ под Windows с детальным описанием всех используемых функций. Это приложение будет использовать Win32API и делать незамысловатую вещь, а именно: передавать сообщения от клиента к серверу и обратно, или, иначе говоря – напишем программу по реализации чата для двух пользователей.
Сразу оговорюсь, что статья рассчитана на начинающих программистов, которые только входят в сетевое программирование под Windows. Необходимые навыки – базовое знание С++, а также теоретическая подготовка по теме сетевых сокетов и стека технологии TCP/IP.
Теория сокетов за 30 секунд для «dummies»
Начну всё-таки немного с теории в стиле «for dummies». В любой современной операционной системе, все процессы инкапсулируются, т.е. скрываются друг от друга, и не имеют доступа к ресурсам друг друга. Однако существуют специальные разрешенные способы взаимодействия процессов между собой. Все эти способы взаимодействия процессов можно разделить на 3 группы: (1) сигнальные, (2) канальные и (3) разделяемая память.
Для того, чтобы сокеты заработали под Windows, необходимо при написании программы пройти следующие Этапы:
Инициализация сокетных интерфейсов Win32API.
Инициализация сокета, т.е. создание специальной структуры данных и её инициализация вызовом функции.
«Привязка» созданного сокета к конкретной паре IP-адрес/Порт – с этого момента данный сокет (его имя) будет ассоциироваться с конкретным процессом, который «висит» по указанному адресу и порту.
Для серверной части приложения: запуск процедуры «прослушки» подключений на привязанный сокет.
Для клиентской части приложения: запуск процедуры подключения к серверному сокету (должны знать его IP-адрес/Порт).
Акцепт / Подтверждение подключения (обычно на стороне сервера).
Обмен данными между процессами через установленное сокетное соединение.
Закрытие сокетного соединения.
Итак, попытаемся реализовать последовательность Этапов, указанных выше, для организации простейшего чата между клиентом и сервером. Запускаем Visual Studio, выбираем создание консольного проекта на С++ и поехали.
Этап 0: Подключение всех необходимых библиотек Win32API для работы с сокетами
Сокеты не являются «стандартными» инструментами разработки, поэтому для их активизации необходимо подключить ряд библиотек через заголовочные файлы, а именно:
WinSock2.h – заголовочный файл, содержащий актуальные реализации функций для работы с сокетами.
WS2tcpip.h – заголовочный файл, который содержит различные программные интерфейсы, связанные с работой протокола TCP/IP (переводы различных данных в формат, понимаемый протоколом и т.д.).
Также нам потребуется прилинковать к приложению динамическую библиотеку ядра ОС: ws2_32.dll. Делаем это через директиву компилятору: #pragma comment(lib, “ws2_32.lib”)
Ну и в конце Этапа 0 подключаем стандартные заголовочные файлы iostream и stdio.h
Итого по завершению Этапа 0 в Серверной и Клиентской частях приложения имеем:
Обратите внимание: имя системной библиотеки ws2_32.lib именно такое, как это указано выше. В Сети есть различные варианты написания имени данной библиотеки, что, возможно, связано иным написанием в более ранних версиях ОС Windows. Если вы используете Windows 10, то данная библиотека называется именно ws2_32.lib и находится в стандартной папке ОС: C:/Windows/System32 (проверьте наличие библиотеки у себя, заменив расширение с “lib” на “dll”).
Этап 1: Инициализация сокетных интерфейсов Win32API
Прежде чем непосредственно создать объект сокет, необходимо «запустить» программные интерфейсы для работы с ними. Под Windows это делается в два шага следующим образом:
Нужно определить с какой версией сокетов мы работаем (какую версию понимает наша ОС) и
Запустить программный интерфейс сокетов в Win32API. Ну либо расстроить пользователя тем, что ему не удастся поработать с сокетами до обновления системных библиотек
Итого код Этапа 1 следующий:
Да, кода мало, а описания много. Так обычно и бывает, когда хочешь глубоко в чем-то разобраться. Так что на лабе будешь в первых рядах.
Этап 2: Создание сокета и его инициализация
Тип сокета: обычно задается тип транспортного протокола TCP ( SOCK_STREAM ) или UDP ( SOCK_DGRAM ). Но бывают и так называемые «сырые» сокеты, функционал которых сам программист определяет в процессе использования. Тип обозначается SOCK_RAW
Тип протокола: необязательный параметр, если тип сокета указан как TCP или UDP – можно передать значение 0. Тут более детально останавливаться не будем, т.к. в 95% случаев используются типы сокетов TCP/UDP.
При необходимости подробно почитать про функцию socket() можно здесь.
Код Этапа 2 будет выглядеть так:
Этап 3: Привязка сокета к паре IP-адрес/Порт
Сокет уже существует, но еще неполноценный, т.к. ему не назначен внешний адрес, по которому его будут находить транспортные протоколы по заданию подключающихся процессов, а также не назначен порт, по которому эти подключающиеся процессы будут идентифицировать процесс-получатель.
В ней уже более понятные пользователю поля, а именно:
Технический массив на 8 байт ( sin_zero[8] )
Соответственно, ввод данных для структуры типа sockaddr_in выглядит следующим образом:
Создание структуры типа sockaddr_in : sockaddr_in servInfo;
Заполнение полей созданной структуры servInfo
В случае ошибки функция возвращает значение меньше 0.
Соответственно, если мы хотим привязать сокет к локальному серверу, то наш код по преобразованию IPv4 адреса будет выглядеть так:
erStat = inet_pton(AF_INET, “127.0.0.1”, &ip_to_num);
Результат перевода IP-адреса содержится в структуре ip_to_num. И далее мы передаем уже в нашу переменную типа sockaddr_in значение преобразованного адреса:
Этап 4 (для сервера): «Прослушивание» привязанного порта для идентификации подключений
После вызова данной функции исполнение программы приостанавливается до тех пор, пока не будет соединения с Клиентом, либо пока не будет возвращена ошибка прослушивания порта. Код Этапа 4 для Сервера:
Этап 4 (для Клиента). Организация подключения к серверу
Функция возвращает 0 в случае успешного подключения и код ошибки в ином случае.
Этап 5 (только для Сервера). Подтверждение подключения
Всё, соединение между Клиентом и Сервером установлено! Самое время попробовать передать информацию от Клиента к Серверу и обратно. Как мы в начале и договорились, мы будет реализовывать простейший чат между ними.
Этап 6: Передача данных между Клиентом и Сервером
Рассмотрим прототипы функций recv() и send() :
Флаги в большинстве случаев игнорируются – передается значение 0.
Функции возвращают количество переданных/полученных по факту байт.
Как видно из прототипов, по своей структуре и параметрам эти функции совершенно одинаковые. Что важно знать:
и та, и другая функции не гарантируют целостности отправленной/полученной информации. Это значит, что при реализации прикладных задач по взаимодействию Клиента и Сервера с их использованием требуется принимать дополнительные меры для контроля того, что все посланные байты действительно посланы и, что еще более важно, получены в том же объеме на другой стороне
предельно внимательно надо относиться к параметру «размер буфера». Он должен в точности равняться реальному количеству передаваемых байт. Если он будет отличаться, то есть риск потери части информации или «замусориванию» отправляемой порции данных, что ведет к автоматической поломке данных в процессе отправки/приёма. И совсем замечательно будет, если размер буфера по итогу работы функции равен возвращаемому значению функции – размеру принятых/отправленных байт.
В качестве буфера рекомендую использовать не классические массивы в С-стиле, а стандартный класс С++ типа char, т.к. он показал себя как более надежный и гибкий механизм при передаче данных, в особенности при передаче текстовых строк, где важен терминальный символ и «чистота» передаваемого массива.
Процесс непрерывного перехода от send() к recv() и обратно реализуется через бесконечный цикл, из которого совершается выход по вводу особой комбинации клавиш. Пример блока кода для Серверной части:
Пришло время показать итоговый рабочий код для Сервера и Клиента. Чтобы не загромождать и так большой текст дополнительным кодом, даю ссылки на код на GitHub:
Несколько важных финальных замечаний:
В итоговом коде я не использую проверку на точное получение отосланной информации, т.к. при единичной (не циклической) отсылке небольшого пакета информации накладные расходы на проверку его получения и отправку ответа будут выше, чем выгоды от такой проверки. Иными словами – такие пакеты теряются редко, а проверять их целостность и факт доставки очень долго.
При тестировании примера также видно, что чат рабочий, но очень уж несовершенный. Наиболее проблемное место – невозможность отправить сообщение пока другая сторона не ответила на твоё предыдущее сообщение. Суть проблемы в том, что после отсылки сообщения сторона-отправитель вызывает функцию recv(), которая, как я писал выше, блокирует исполнение последующего кода, в том числе блокирует вызов прерываний для осуществления ввода. Это приводит к тому, что набирать сообщение и что-то отправлять невозможно до тех пор, пока процесс не получит ответ от другой стороны, и вызов функции recv() не будет завершен. Благо введенная информация с клавиатуры не будет потеряна, а, накапливаясь в системном буфере ввода/вывода, будет выведена на экран как только блокировка со стороны recv() будет снята. Таким образом, мы реализовали так называемый прямой полудуплексный канал связи. Сделать его полностью дуплексным в голой сокетной архитектуре достаточно нетривиальная задача, частично решаемая за счет создания нескольких параллельно работающих потоков или нитей (threads) исполнения. Один поток будет принимать информацию, а второй – отправлять.
В последующих статьях я покажу реализацию полноценного чата между двумя сторонами (поможет разобраться в понятии «нити процесса»), а также покажу полноценную реализацию прикладного протокола по копированию файлов с Сервера на Клиент.
Основы функционирования веб-приложений
Как работают веб-приложения
Цель лекции: сформировать концептуальное представление о функционировании веб-приложений.
Давайте разберемся в том, как функционирует любое веб-приложение. Необходимые компоненты для работы пользователя с веб-приложением – браузер (тонкий клиент), веб-сервер (серверная часть), протокол взаимодействия клиента и сервера (HTTP) и язык разметки для создания документов (HTML). Основу функционирования веб-сервера и протокола HTTP мы подробнее рассмотрим в следующих лекциях, а пока остановимся на концептуальном представлении. Для того, чтобы веб-приложение стало доступно, его необходимо разместить в рамках веб-сервера (специальная программа, которая обрабатывает запросы из сети). После этого приложение получит свой уникальный адрес в рамках протокола HTTP (например, http://www.myapplication.com/page1.html). Используя этот адрес пользователь может обратиться к приложению. Для этого он должен запустить браузер (клиентское приложение) и ввести в адресной строке адрес приложения. В этот момент браузер сгенерирует запрос к серверу и отправит его, используя протокол HTTP. В момент, когда сервер примет этот запрос, он сможет распознать, что именно требуется от него на основе полученного запроса. Используя эти данные он сгенерирует ответ и отправит его обратно клиенту также используя протокол HTTP. Обычно ответ содержит гипертекстовую разметку HTML, содержащую структуру документа, который передается пользователю. После того, как браузер получит ответ в виде HTML-документа, он немедленно отобразит его пользователю. Таким образом, было совершено взаимодействие клиента и сервера. Зачастую документ HTML содержит ссылки на изображение, другие медиа-файлы, таблицы стилей или клиентские сценарии. В этом случае браузер генерирует еще несколько аналогичных запросов к веб-серверу. Однако, в этом случае веб-сервер передает клиенту уже не HTML-документ, а соответствующие запрашиваемые ресурсы (изображения, таблицы стилей, клиентские сценарии и т.д.).
В самом простейшем случае на сервере может быть сохранен готовый документ HTML, который по запросу будет передаваться пользователю. Это – так называемый, статический документ. В этом случае он просто считывается с жесткого диска и передается клиенту. Однако, такой сценарий работы в глобальной сети становится все более редким. Другой подход – генерация кода HTML в процессе обработки запроса от клиента. Этот подход позволяет сделать веб-приложение более интерактивным, отзывчивым на действия клиента и создающее впечатления настоящего приложения, а не простой загрузки HTML-документов. Таким образом, мы, имея возможность генерировать HTML-код страницы, можем влиять на ту информацию, элементы управления и другие аспекты интерфейса, которые увидит пользователь. По сути, задача веб-приложения и заключается в том, чтобы генерировать нужный HTML-код, в зависимости от действий пользователя. Однако, возможности веб-приложений могут не ограничиваться только генерацией разметки HTML – они могут генерировать изображения, клиентские сценарии, таблицы стилей и другие ресурсы, которые могут быть загружены пользователем. Тем не менее, основным сценарием является все-таки генерация конечного документа HTML.
Как уже говорилось ранее, для взаимодействия клиента и сервера используется протокол HTTP (который более детально будет рассмотрен в последующих лекциях). Сейчас важно понять, что этот протокол работает по схеме «запрос-ответ». В момент, когда клиент хочет обратиться к серверу, он генерирует запрос, который отправляется серверу. Сервер обрабатывает этот запрос и подготавливает ресурсы, которые будут отправлены клиенту. После этого сервер генерирует ответ, в котором содержатся все необходимые данные и отправляет клиенту. Работа веб-приложений заключается в формировании необходимых данных как раз в момент подготовки ресурсов на сервере. Обычно в этот момент запускается некоторый программный код, который содержит определенную бизнес логику. Схему работы типичного веб-приложения схематически можно представить следующим образом (зеленым цветом обозначены действия, которые выполняются на клиентской стороне, а синие – на серверной).
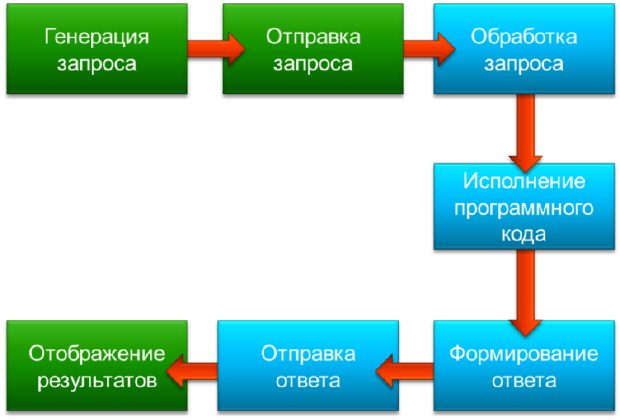
Веб-приложения существенно отличаются от настольных приложений. Последние запускаются на компьютере клиента и выполняют свой код именно там. Поэтому настольные приложения зачастую обладают более богатым и отзывчивым пользовательским интерфейсом и позволяют реализовывать более богатые сценарии. По сравнению с настольными приложениями, веб-приложения обладают более ограниченными возможностями по формированию пользовательского интерфейса и клиентской функциональности. По этой причине за последнее время сложился стереотип о том, что серьезные приложения (например, бизнес-приложения) – это, как правило, настольные приложения. Однако, развитие веб-технологий доказало, что веб-приложения также могут реализовывать богатые сценарии и успешно конкурировать с настольными приложениями. Кроме того, за последние несколько лет очень активно развиваются технологии, позволяющие сделать веб-приложения еще более интерактивными. К ним относятся технология AJAX (будет рассмотрена в рамках курса), которая на основе клиентских сценариев JavaScript может сделать взаимодействие более интерактивным. Также существует ряд технологий, которые добавляют интерактивности приложению за счет внедрения в браузер специальных модулей (плагинов), которые могут отображать специальные типы файлов с более богатыми возможностями. К таким технологиям в первую очередь относятся технологии Silverlight и Flash.
Однако, несмотря на то, что существует ряд технологий, упрощающих создание динамичных веб-приложений, их разработка по прежднему остается довольно трудоемкой задачей. Разработка веб-приложений существенно отличается от разработки настольных систем. Этому есть две главные причины:
Оба этих фактора существенно влияют на процесс разработки веб-приложений. Из-за этого при построении любого веб-приложения приходится решать типичные задачи – способы хранения информации о пользователе, организация сеансов работы пользователя, способы переходов от страницы к странице, механизмы оптимизации эффективности (например, кэширование) и др. При реализации каждого веб-приложения разработчику придется столкнуться с этими проблемами и решить их. Поскольку набор этих задач является достаточно стандартным и одинаково решается для большинства веб-приложений, то его реализация вынесена в отдельные технологии, которые называются технологиями для разработки веб-приложений. К таким технологиям относятся технология Microsoft ASP.NET, PHP, Ruby on Rails и др. В них, фактически, содержатся все компоненты, необходимые для реализации веб-приложений и учитывающие их специфику. Далее в рамках данного курса мы будем рассматривать разработку веб-приложений с позиции платформы Microsoft ASP.NET.
Однако, несмотря на те преимущества настольных приложений, которые мы рассмотрели ранее, веб-приложения также обладают своими преимуществами. Основное преимущество веб-приложений заключается в процессе развертывания приложения, т.е. установке приложения конечному клиенту. Если настольное приложение необходимо установить на каждое рабочее место где оно будет использоваться, то веб-приложение нужно разместить на сервере и дать ссылку на него всем пользователям. Особенно актуален данный аспект там, где присутствует большое количество рабочих мест. Кроме того, в случае обновления программного кода, веб-приложения также имеют преимущество – для их обновления требуется только обновить код на сервере. При этом настольное приложение потребовалось бы обновлять на каждом рабочем месте.
Краткие итоги
Веб-приложения работают на сервере и исполняются в рамках веб-сервера (специальной программы, обрабатывающей запросы). Взаимодействие клиента и сервера осуществляется про протоколу HTTP в рамках схемы «запрос-ответ». Вся логика веб-приложения размещается на сервере. Из-за этого появляются дополнительные проблемы при разработке веб-приложений. Настольные приложения имеют более богатый пользовательский интерфейс, но веб-приложения легче разворачивать и обновлять (особенно, если имеется большое количество рабочих мест). Пользовательский интерфейс веб-приложений может стать более интерактивным, если использовать дополнительные инструменты – клиентские сценарии JavaScript, а также приложения Silverlight, Flash и др.



