Теорема Байеса
Из Википедии — свободной энциклопедии

Теорема Байеса (или формула Байеса) — одна из основных теорем элементарной теории вероятностей, которая позволяет определить вероятность какого-либо события при условии, что произошло другое статистически взаимозависимое с ним событие. Другими словами, по формуле Байеса можно более точно пересчитать вероятность, взяв в расчёт как ранее известную информацию, так и данные новых наблюдений. Формула Байеса может быть выведена из основных аксиом теории вероятностей, в частности из условной вероятности. Особенность теоремы Байеса заключается в том, что для её практического применения требуется большое количество расчётов, вычислений, поэтому байесовские оценки стали активно использовать только после революции в компьютерных и сетевых технологиях.
При возникновении теоремы Байеса вероятности, используемые в теореме, подвергались целому ряду вероятностных интерпретаций. В одной из таких интерпретаций говорилось, что вывод формулы напрямую связан с применением особого подхода к статистическому анализу. Если использовать байесовскую интерпретацию вероятности, то теорема показывает, как личный уровень доверия может кардинально измениться вследствие количества наступивших событий. В этом заключаются выводы Байеса, которые стали основополагающими для байесовской статистики. Однако теорема не только используется в байесовском анализе, но и активно применяется для большого ряда других расчётов.
Психологические эксперименты [1] показали, что люди часто неверно оценивают реальную (математически верную) вероятность события, основываясь на некоем полученном опыте (апостериорная вероятность), поскольку игнорируют саму вероятность предположения (априорная вероятность). Поэтому правильный результат по формуле Байеса может сильно отличаться от интуитивно ожидаемого.
Как применять теорему Байеса для решения реальных задач

Возможно, вы никогда не слышали про теорему Байеса, но пользовались ей постоянно. Например, изначально вы оценили вероятность получения прибавки к зарплате как 50%. Получив положительные отзывы от менеджера, вы скорректировали оценку в лучшую сторону, и, наоборот, уменьшили ее, если сломали кофеварку на работе. Так происходит уточнение значения вероятности по мере аккумулирования информации.
Основная идея теоремы Байеса состоит в том, чтобы получить большую точность оценки вероятности события путем учета дополнительных данных.
Принцип прост: есть первоначальная основная оценка вероятности, которую уточняют c получением большего количества информации.
Формула Байеса
Интуитивные действия формализуются в простом, но мощном уравнении (формула вероятности Байеса):
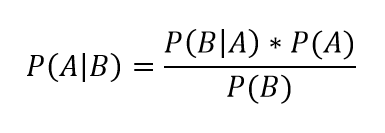
Левая часть уравнения — апостериорная оценка вероятности события А при условии наступления события В (т. н. условная вероятность).
Это короткое уравнение является основой байесовского метода.
Абстрактность событий А и В не позволяет четко осознать смысл этой формулы. Для понимания сути теоремы Байеса рассмотрим реальную задачу.
Пример
Одной из тем, над которой я работаю, является изучение моделей сна. У меня есть данные за два месяца, записанные с помощью моих часов Garmin Vivosmart, показывающие, во сколько я засыпаю и просыпаюсь. Окончательная модель, показывающая наиболее вероятное распределение вероятности сна как функцию времени (MCMC — приблизительный метод), приведена ниже.

На графике приведена вероятность того, что я сплю, в зависимости лишь от времени. Как она изменится, если учесть время, в течение которого включен свет в спальне? Для уточнения оценки и нужна теорема Байеса. Уточненная оценка основана на априорной и имеет вид:
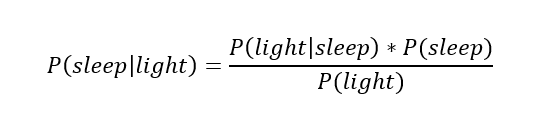
Выражение слева — вероятность того, что я сплю, при условии, что известно, включен ли свет в моей спальне. Априорная оценка в данный момент времени (приведена на графике выше) обозначена как P(sleep). Например, в 10:00 вечера априорная вероятность того, что я сплю, равна 27,34%.
Добавим больше информации, используя вероятность P(bedroom light|sleep), полученную из наблюдаемых данных.
Из собственных наблюдений мне известно следующее: вероятность того, что я сплю, когда свет включен, равна 1%.
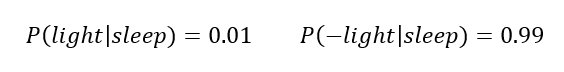
Вероятность того, что свет выключен во время сна, равна 1-0,01 = 0,99 (знак «-» в формуле означает противоположное событие), потому что сумма вероятностей противоположных событий равна 1. Когда я сплю, то свет в спальне либо включен, либо выключен.
Наконец, уравнение также включает в себя константу нормировки P(light) — вероятность того, что свет включен. Свет бывает включен и когда я сплю, и когда бодрствую. Поэтому, зная априорную вероятность сна, вычислим константу нормировки так:
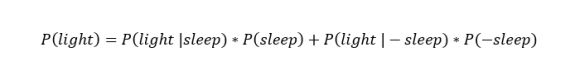
Вероятность того, что свет включен, учтена в обоих вариантах: либо я сплю, либо нет (P (-sleep) = 1 — P (sleep) — это вероятность того, что я не сплю.)
Вероятность того, что свет включен в тот момент, когда я не сплю, равна P(light|-sleep), и определяется путем наблюдения. Мне известно, что свет горит, когда я бодрствую, с вероятностью 80% (это означает, что есть 20% вероятность того, что свет не включен, если я бодрствую).
Окончательное уравнение Байеса принимает вид:
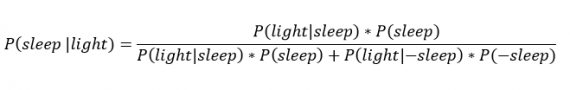
Оно позволяет вычислить вероятность того, что я сплю, при условии, что свет включен. Если нас интересует вероятность того, что свет выключен, нужно каждую конструкцию P(light|… заменить на P(-light|….
Давайте посмотрим, как используют полученные символьные уравнения на практике.
Применим формулу к моменту времени 22:30 и учтем, что свет включен. Мы знаем, вероятность того, что я спал, равна 73,90%. Это число — отправная точка для нашей оценки.
Уточним его, учтя информацию об освещении. Зная, что свет включен, подставим числа в формулу Байеса:
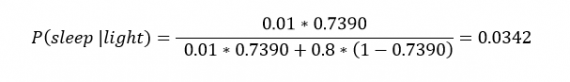
Дополнительные данные резко изменили оценку вероятности: от более 70% до 3,42%. Это показывает силу теоремы Байеса: мы смогли уточнить нашу первоначальную оценку ситуации, включив в нее больше информации. Возможно, мы уже интуитивно делали это раньше, но теперь, рассуждая об этом в терминах формальных уравнений, мы смогли подтвердить наши прогнозы.
Python
Рассмотрим еще один пример. Что если на часах 21:45 и свет выключен? Попытайте рассчитать вероятность самостоятельно, считая априорную оценку равной 0.1206.
Вместо того, чтобы каждый раз считать вручную, я написал простой код на Python для выполнения этих вычислений, который вы можете попробовать в Jupyter Notebook. Вы получите следующий ответ:
The prior probability of sleep: 12.06%
The updated probability of sleep: 40.44%
И снова дополнительная информация меняет нашу оценку. Теперь, если моя сестра захочет позвонить мне в 21:45 зная, что мой свет включен, она может воспользоваться этим уравнением, чтобы определить, смогу ли я взять трубку (предполагая, что я беру трубку только бодрствующим)! Кто говорит, что статистика неприменима повседневной жизни?
Визуализация вероятности
Наблюдение за вычислениями полезно, но визуализация помогает добиться более глубокого понимания результата. Я всегда стараюсь использовать графики, чтобы генерировать идеи, если они сами не приходят при простом изучении уравнений. Мы можем визуализировать априорное и апостериорное распределения вероятности сна с использованием дополнительных данных:
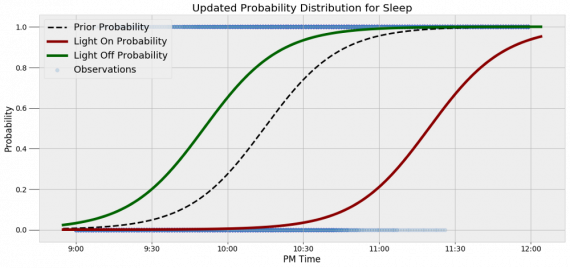
Когда свет включен, график смещается вправо, указывая на то, что я с меньшей вероятностью сплю в данный момент времени. Аналогично, график смещается влево, если мой свет выключен. Понять смысл теоремы Байеса непросто, но эта иллюстрация наглядно демонстрирует, зачем ее нужно использовать. Формула Байеса — инструмент для уточнения прогнозов с помощью дополнительных данных.
Что, если есть еще больше данных?
Зачем останавливаться на освещении в спальне? Мы можем использовать еще больше данных в нашей модели для дальнейшего уточнения оценки (пока данные остаются полезными для рассматриваемого случая). Например, я знаю, что если мой телефон заряжается, то я сплю с вероятностью 95%. Этот факт можно учесть в нашей модели.
Предположим, что вероятность того, что мой телефон заряжается, не зависит от освещения в спальне (независимость событий — это достаточно сильное упрощение, но оно позволит сильно облегчить задачу). Составим новое, еще более точное выражение для вероятности:
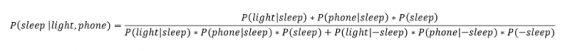
Получившаяся формула выглядит громоздко, но, используя код на Python, мы можем написать функцию, которая будет производить расчет. Для любого момента времени и любой комбинации наличия освещения/зарядки телефона эта функция возвращает уточненную вероятность того, что я сплю.
Пропустим математику (все равно считать будет компьютер) и перейдем к результатам:
Time is 11:00:00 PM Light is ON Phone IS NOT charging.
The prior probability of sleep: 95.52%
The updated probability of sleep: 1.74%
В 23:00 без дополнительной информации мы могли почти с полной вероятностью сказать, что я сплю. Однако, как только у нас будет дополнительная информация о том, что свет включен, а телефон не заряжается, мы заключаем, что вероятность того, что я сплю, практически равна нулю. Вот еще один пример:
Time is 10:15:00 PM Light is OFF Phone IS charging.
The prior probability of sleep: 50.79%
The updated probability of sleep: 95.10%
Вероятность смещается вниз или вверх в зависимости от конкретной ситуации. Чтобы продемонстрировать это, рассмотрим четыре конфигурации дополнительных данных и то, как они изменяют распределение вероятности:
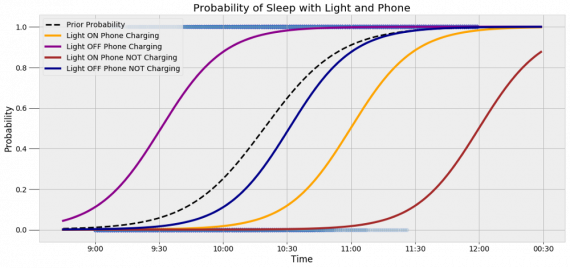
На этом графике представлено много информации, но главный смысл состоит в том, что кривая вероятности изменяется в зависимости от дополнительных факторов. По мере добавления других данных мы будем получать более точную оценку.
Заключение
Теорема Байеса и другие статистические понятия могут быть трудными для понимания, когда они представлены абстрактными уравнениями, использующими только буквы или выдуманные ситуации. Настоящее обучение приходит, когда мы применяем абстрактные понятия в реальных задачах.
Успех в области data science — это непрерывное обучение, добавление новых методов в набор навыков и поиск оптимального метода для решения задач. Теорема Байеса позволяет уточнять наши оценки вероятности с помощью дополнительной информации для более качественного моделирования реальности. Увеличение количества информации позволяет получать более точные прогнозы, и метод Байеса оказывается полезным инструментом для решения этой задачи.
Я приветствую обратную связь, дискуссию и конструктивную критику. Связаться со мной можно в Twitter: @koehrsen_will.
Может быть интересно:
Понимаем теорему Байеса
Перевод статьи подготовлен специально для студентов базового и продвинутого курсов «Математика для Data Science».

Теорема Байеса – одна из самых известных теорем в статистике и теории вероятности. Даже если вы не работаете с расчетами количественных показателей, вероятно, вам в какой-то момент пришлось познакомиться с этой теоремой во время подготовки к экзамену.
Вот так она выглядит, но что это значит и как работает? Сегодня мы это узнаем и углубимся в теорему Байеса.
Основания для подтверждения наших суждений
В чем вообще заключается смысл теории вероятности и статистики? Одно из наиболее важных применений относится к принятию решений в условиях неопределенности. Когда вы принимаете решение совершить какое-либо действие (если, конечно, вы человек разумный), вы делаете ставку на то, что после завершения этого действия оно повлечет за собой результат лучший, чем если бы этого действия не произошло… Но ставки – это вещь ненадежная, как же вы в конечном итоге принимаете решение делать ли тот или иной шаг или нет?
Так или иначе вы оцениваете вероятность успешного исхода, и, если эта вероятность выше определенного порогового значения, вы предпринимаете шаг.
Таким образом, возможность точно оценить вероятность успеха имеет решающее значение для принятия правильных решений. Несмотря на то, что случайность всегда будет играть определенную роль в конечном исходе, вам следует учиться правильно использовать эти случайности и оборачивать их в свою пользу с течением времени.
Именно здесь вступает в силу теорема Байеса – она дает нам количественную основу для сохранения нашей веры в исход действия по мере изменений окружающих факторов, что, в свою очередь, позволяет нам со временем совершенствовать процесс принятия решений.
Разберем формулу
Давайте еще раз посмотрим на формулу:
P(A|B) – это пример апостериорной (условной) вероятности, то есть такой, которая измеряет вероятность какого-то определенного состояния окружающего мира (а именно состояния, при котором произошло событие В). Тогда как P(A) – это пример априорная вероятности, которая может быть измерена при любом состоянии окружающего мира.
Давайте посмотрим на теорему Байеса в действии на примере. Предположим, что недавно вы закончили курс по анализу данных от bootcamp. Вы еще не получили ответа от некоторых компаний, в которых вы проходили собеседование, и начинаете волноваться. Итак, вы хотите рассчитать вероятность того, что конкретная компания сделает вам предложение об устройстве на работу, при условии, что уже прошло три дня, а они вам так и не перезвонили.
Перепишем формулу в терминах нашего примера. В данном случае, исход А (Offer) – это получения предложения о работе, а исход В (NoCall) – «отсутствие телефонного звонка в течение трех дней». Исходя из этого, нашу формулу можно переписать так:
Значение P(Offer|NoCall) — это вероятность получения предложения при условии, что звонка нет в течение трех дней. Эту вероятность оценить крайне сложно.
Однако обратной вероятности, P(NoCall|Offer), то есть отсутствию телефонного звонка в течение трех дней, при учете, что в итоге вы получили предложение о работе от компании, вполне можно привязать какое-то значение. Из разговоров с друзьями, рекрутерами и консультантами вы узнаете, что эта вероятность небольшая, но иногда компания все же может сохранять тишину в течение трех дней, если она все еще планирует пригласить вас на работу. Итак, вы оцениваете:
40% — это неплохо и кажется, еще есть надежда! Но мы еще не закончили. Теперь нам нужно оценить P(Offer), вероятность выхода на работу. Все знают, что поиск работы – это долгий и трудный процесс, и возможно вам придется проходить собеседование несколько раз, прежде чем вы получите это предложение, поэтому вы оцениваете:
Теперь нам осталось оценить P(NoCall), вероятность, что вы не получите звонок от компании в течение трех дней. Существует множество причин, по которым вам могут не перезвонить в течение трех дней – они могут отклонить вашу кандидатуру или до сих пор проводить собеседования с другими кандидатами, или рекрутер просто заболел и поэтому не звонит. Что ж, есть множество причин, по которым вам могли не позвонить, так что эту вероятность вы оцениваете как:
А теперь собрав это все вместе, мы можем рассчитать P(Offer|NoCall):
Это довольно мало, так что, к сожалению, рациональнее оставить надежду на эту компанию (и продолжать отправлять резюме в другие). Если это все еще кажется немного абстрактным, не переживайте. Я чувствовал то же самое, когда впервые узнал про теорему Байеса. Теперь давайте разберемся, как мы пришли к этим 8,9% (имейте в виду, что ваша изначальная оценка в 20% уже была низкой).
Интуиция, стоящая за формулой
Помните, мы говорили о том, что теорема Байеса дает основания для подтверждения наших суждений? Так откуда же они берутся? Они берутся из априорной вероятности P(A), которая в нашем примере зовется P(Offer), по сути, это и есть наше изначальное суждение том, насколько вероятно, что человек получит предложение о работе. В нашем примере вы можете считать, что априорная вероятность – это вероятность того, что вы получите предложение о работе в тот же момент, когда покинете собеседование.
Появляется новая информация – прошло 3 дня, а компания вам так и не перезвонила. Таким образом мы используем другие части уравнения, чтобы скорректировать нашу априорную вероятность нового события.
Давайте рассмотрим вероятность P(B|A), которая в нашем примере называется P(NoCall|Offer). Когда вы впервые видите теорему Байеса, вы задаетесь вопросом: Как понять откуда взять вероятность P(B|A)? Если я не знаю, чему равна вероятность P(A|B), то каким магическом образом я должен узнать, чему равна вероятность P(B|A)? Я вспоминаю фразу, которую однажды сказал Чарльз Мангер:
«Переворачивайте, всегда переворачивайте!»
— Чарльз Мангер
Он имел в виду, что, когда вы пытаетесь решить сложную задачу, ее нужно перевернуть с ног на голову и посмотреть на нее под других углом. Именно это и делает теорема Байеса. Давайте переформулируем теорему Байеса в терминах статистики, чтобы сделать ее более понятной (об это я узнал отсюда):

Для меня, например, такая запись выглядит понятнее. У нас есть априорная гипотеза (Hypothesis) — о том, что мы получили работу, и наблюдаемые факты — доказательства (Evidence) – телефонного звонка нет в течение трех дней. Теперь мы хотим узнать вероятность того, что наша гипотеза верна, с учетом предоставленных фактов. Как бы решили выше, у нас есть вероятность P(A) = 20%.
Время переворачивать все с ног на голову! Мы используем P(Evidence|Hypothesis), чтобы посмотреть на задачу с другой стороны и спрашиваем: «Какова вероятность наступления этих событий-доказательств в мире, где наша гипотеза верна?». Итак, если вернуться к нашему примеру, мы хотим знать, насколько вероятно, что, если нам не звонят в течение трех дней, нас все равно возьмут на работу. В изображении выше я пометил P(Evidence|Hypothesis), как “scaler” (скейлер), потому что это слово хорошо отражает суть значения. Когда мы умножаем его на априорное значение, он уменьшает или увеличивает вероятность события, в зависимости от того «вредит» ли какое-либо событие-доказательство нашей гипотезе. В нашем случае, чем больше дней проходит без звонка, тем меньше вероятность того, что нас позовут на работу. 3 дня тишины – это уже плохо (они сокращают нашу априорную вероятность на 60%), тогда как 20 дней без звонка полностью уничтожат надежду на получение работы. Таким образом, чем больше накапливается событий-доказательств (больше дней проходит без телефонного звонка), тем быстрее скейлер уменьшает вероятность. Скейлер – это механизм, который теорема Байеса использует для корректировки наших суждений.
Есть одна вещь, с которой я боролся в оригинальной версии этой статьи. Это была формулировка того, почему P(Evidence|Hypothesis) легче оценить, чем P(Hypothesis|Evidence). Причина этого заключается в том, что P(Evidence|Hypothesis) – это гораздо более ограниченная область суждений о мире. Сужая область, мы упрощаем задачу. Можно провести аналогию с огнем и дымом, где огонь – это наша гипотеза, а наблюдение дыма – событие, доказывающее наличие огня. P(огонь|дым) оценить сложнее, поскольку много чего может вызвать дым – выхлопные газы автомобилей, фабрики, человек, который жарит гамбургеры на углях. При этом P(дым|огонь) оценить проще, поскольку в мире, где есть огонь, почти наверняка будет и дым.
Значение вероятности уменьшается по мере того, сколько проходит дней без звонка.
Последняя часть формулы, P(B) или же P(Evidence) – это нормализатор. Как следует из названия, его цель – нормализовать произведение априорной вероятности и скейлера. Если бы у на не было нормализатора, мы бы имели следующее выражение:

Заметим, что произведение априорной вероятности и скейлера равно совместной вероятности. И поскольку одно из составляющих в нем P(Evidence), то на совместную вероятность повлияла бы маленькая частота событий.
Это проблема, поскольку совместная вероятность – это значение, включающее в себя все состояния мира. Но нам то не нужны все состояния, нам нужны только те состояния, которые были подтверждены событиями-доказательствами. Другими словами, мы живем в мире, где события – доказательства уже произошли, и их количество уже не имеет значения (поэтому мы не хотим, чтобы они влияли на наши расчеты в принципе). Деление произведения априорной вероятности и скейлера на P(Evidence) меняет его с совместной вероятности на условную(апостериорную). Условная вероятность учитывает только те состояния мира, в которых произошло событие-доказательство, именно этого мы и добиваемся.
Еще одна точка зрения, с которой можно взглянуть на то, почему мы делим скейлер на нормализатор, заключается в том, что они отвечают на два важных вопроса – и их отношение объединяет эту информацию. Давайте возьмем пример из моей недавней статьи про Байеса. Предположим, мы пытаемся выяснить, является ли наблюдаемое животное кошкой, основываясь на единственном признаке – ловкости. Все, что мы знаем, так это то, что животное, о котором мы говорим, проворное.
Подведем итог
Теперь, когда мы знаем, как трактовать каждую часть формулы, мы можем наконец собрать все воедино и посмотреть на то, что получилось:
Введение в Байесовские методы
В качестве введения
В настоящее время Байесовские методы получили достаточно широкое распространение и активно используются в самых различных областях знаний. Однако, к сожалению, не так много людей имеют представление о том, что же это такое и зачем это нужно. Одной из причин является отсутствие большого количества литературы на русском языке. Поэтому здесь попытаюсь изложить их принципы настолько просто, насколько смогу, начав с самых азов (прошу прощения, если кому-то это покажется слишком простым).
В дальнейшем я бы хотел перейти к непосредственно Байесовскому анализу и рассказать об обработке реальных данных и о, на мой взгляд, отличной альтернативе языку R (о нем немного писалось тут) — Python с модулем pymc. Лично мне Python кажется гораздо более понятным и логичным, чем R с пакетами JAGS и BUGS, к тому же Python дает гораздо большую свободу и гибкость (хотя в Python есть и свои трудности, но они преодолимы, да и в простом анализе встречаются нечасто).
Немного истории
В качестве краткой исторической справки скажу, что формула Байеса была опубликована аж в 1763 году спустя 2 года после смерти ее автора, Томаса Байеса. Однако, методы, использующие ее, получили действительно широкое распространение только к концу ХХ века. Это объясняется тем, что расчеты требуют определенных вычислительных затрат, и они стали возможны только с развитием информационных технологий.
О вероятности и теореме Байеса
Формула Байеса и все последующее изложение требует понимания вероятности. Подробнее о вероятности можно почитать на Википедии.
На практике вероятность наступления события есть частота наступления этого события, то есть отношение количества наблюдений события к общему количеству наблюдений при большом (теоретически бесконечном) общем количестве наблюдений.
Рассмотрим следующий эксперимент: мы называем любое число из отрезка [0, 1] и смотрим за тем, что это число будет между, например, 0.1 и 0.4. Как нетрудно догадаться, вероятность этого события будет равна отношению длины отрезка [0.1, 0.4] к общей длине отрезка [0, 1] (другими словами, отношение «количества» возможных равновероятных значений к общему «количеству» значений), то есть (0.4 — 0.1) / (1 — 0) = 0.3, то есть вероятность попадания в отрезок [0.1, 0.4] равна 30%.
Теперь посмотрим на квадрат [0, 1] x [0, 1].
Допустим, мы должны называть пары чисел (x, y), каждое из которых больше нуля и меньше единицы. Вероятность того, что x (первое число) будет в пределах отрезка [0.1, 0.4] (показан на первом рисунке как синяя область, на данный момент для нас второе число y не важно), равна отношению площади синей области к площади всего квадрата, то есть (0.4 — 0.1) * (1 — 0) / (1 * 1) = 0.3, то есть 30%. Таким образом можно записать, что вероятность того, что x принадлежит отрезку [0.1, 0.4] равна p(0.1



