data frame
кадр данных
кадр
Протокольный блок данных уровня звена данных
[ГОСТ 24402-88]
[ГОСТ 29099-91]
[ГОСТ Р 54325-2011 (IEC/TS 61850-2:2003)]
Тематики
Синонимы
кадровый формат данных
—
[Л.Г.Суменко. Англо-русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.]
Тематики
Смотреть что такое «data frame» в других словарях:
Data Frame — [engl.], Datenpaket … Universal-Lexikon
data frame — A unit of information, represented as a page or two of data, including the margin around the frame … IT glossary of terms, acronyms and abbreviations
Data Frame — Datenübertragungsrahmen … Acronyms
Data Frame — Datenübertragungsrahmen … Acronyms von A bis Z
Data compression — Source coding redirects here. For the term in computer programming, see Source code. In computer science and information theory, data compression, source coding or bit rate reduction is the process of encoding information using fewer bits than… … Wikipedia
data header — User defined title for a data frame … IT glossary of terms, acronyms and abbreviations
Data center bridging — (DCB) refers to a set of enhancements to Ethernet local area networks for use in data center environments. Specifically, DCB goals are, for selected traffic, to eliminate loss due to queue overflow and to be able to allocate bandwidth on links.… … Wikipedia
Frame-bursting — is a technique in wireless technology supported by the draft 802.11e Quality of Service specification. Frame Bursting may increase the throughput of any (point to point) 802.11A, B, G or N link connection in certain conditions. This is done by… … Wikipedia
Фрейм дата что это
Сообщение Guido » 28 мар 2011, 22:48
В самом начале хочется сказать, что во фрейм дате нет ничего сложного или непонятного. Все, что нужно чтобы разобраться в ней это запомнить несколько английских терминов, усвоить пару общих принципов и не иметь пробелов в математике за второй класс в школе. Фрейм дата это очень простой и полезный инструмент.
Следующий вопрос: зачем она нужна? Она нужна, чтобы вы лучше понимали что происходит на экране (почему это перебивает то, почему этот чар может наказать это, а этот нет), чтобы вы лучше понимали что может ваш чар.
Фрейм дата очень сильно экономит время. Чтобы понять что и как можно наказать не нужно идти в тренинг и пробовать на кукле все подряд – открыл фрейм дату, посмотрел и все, вы знаете как наказывать подсечку Рю.
Ну, а теперь к сути, что же такое фрейм дата? Frame data в переводе означает «данные о кадрах». О каких же кадрах идет речь и зачем нам данные о них? Это те кадры из которых состоит фильм\игра на экране телевизора\монитора и, в том числе, SSF4, который идет в режиме 60 кадров в секунду.
От этих трех составляющих (стартап, актив,рекавери) зависит быстрота, эффективность и сейфовость(safe, безопасность) удара.
(4-1)+14+(-4)=13.
Как дела обстоят с хитстаном? Также.
(4-1)+14+1=18.
Что же означает минус на блоке? Что это движение могут наказать чары у которых есть движение которое имеет стартап 4 или менее фреймов. Например: Зангиев своим броском (стартап 2), Рю своим драгон панчем (стартап 3, dragon punch, обычно сокращается до дп\dp) или Чан Ли комбой начинающейся с кр лк (стартап 3).
На сегодня это все, спасибо за внимание!
В следующем выпуске мы рассмотрим откуда берутся комбы, на что влияет количество активных кадров, что произойдет если два удара сделать одновременно или почти одновременно, что такое реверсал(reversal) и… да пожалуй и все, я же говорил, что фрейм дата это не трудно.
Дополнения\иллюстрации:
Миксап Акумы на противнике в блокстане:
Работа с табличными данными в R. Часть 1
Data Frame
Data Frame используются для хранения табличных данных. Они представляют собой особый тип списков (lists), матрицу данных. Это – именованный список векторов одной и той же длины, в которых элементы отвечают за переменные. В отличие от матриц, таблица данных содержит элементы разных классов, т.е. допускаются столбцы с числовыми, текстовыми и логическими значениями.
Создать Data Frame
Для создания таблицы данных применяется функция data.frame()
Определение таблицы данных на основе векторов
Определим сначала два вектора, а после введем величину d, которая является таблицей данных, включающей эти два вектора:
Еще один пример по созданию таблицы данных
Пусть требуется изменить названия столбцов. Тогда
Кроме того, вывод значений 1-го столбца (переменной) осуществляется следующим образом
Изложенная процедура создания таблицы данных с изменением названий столбцов имеет аналог
Выбор числа, строк и столбцов
[1] 5260 5470 5640 6180 6390 6515 6805 7515 7515 8230 8770
Если нужно взять определенные элементы из вектора, пользуемся записью вида
Здесь с(…) запись, которая определяет вектор, состоящий из чисел под указанными порядковыми номерами.
Это же можно делать следующим образом
Кроме того, применяются логические условия для выбора чисел из вектора
intake.post[intake.pre > 7000 & intake.pre
Индексирование с data frame происходит так
В квадратных скобках первый параметр указывает на номер строки, а второй – столбца. То же самое получаем, если вместо номера указывается наименование переменной
Если нужна конкретная строка целиком, например, 5-я, то записываем
Следует подчеркнуть, что запятая нужна.
По аналогии получаем все значения по конкретному столбцу
[1] 3910 4220 3885 5160 5645 4680 5265 5975 6790 6900 7335
Пусть необходимо вывести значения по заданным строкам и столбцам. Для этого следует выполнить
Выбор по условию
Если нужна выборка записей (строк), которые соответствуют выполнению условия по одной переменной, то команда имеет такой вид
Данную выборку можно получить несколько другим способом
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
Шапка – head ()
Работая над большим массивом данных, часто есть потребность посмотреть несколько первых строк. В таком случае можно выбрать один из двух способов.
Конец – tail()
Сведения о таблице: количество строк и столбцов, их названия
Чтобы узнать, сколько строк и столбцов насчитывается в таблице, воспользуемся функцией dim()
Благодаря dimnames() можно увидеть названия строк и столбцов
Как видим, Data Frame имеет особый атрибут raw.names
Чтобы узнать и применять в дальнейших расчетах количество строк, вводим функцию nrow(). А количество столбцов определяется через ncol().
Полезной функцией для получения информации о таблице данных является str()
При создании таблицы можно указать, что переменная типа “Factor” является “Character”
‘data.frame’: 5 obs. of 3 variables:
Должен ли я использовать data.frame или матрицу?
Оба хранят данные в прямоугольном формате, поэтому иногда это неясно.
Существуют ли общие правила, когда следует использовать какой тип данных?
Часть ответа уже содержится в вашем вопросе: вы используете фреймы данных, если можно ожидать, что столбцы (переменные) будут разных типов (числовые / символьные / логические и т. Д.). Матрицы предназначены для данных одного типа.
Следовательно, выбор matrix / data.frame проблематичен только в том случае, если у вас есть данные одного типа.
Ответ зависит от того, что вы собираетесь делать с данными в data.frame / matrix. Если оно будет передано другим функциям, то ожидаемый тип аргументов этих функций определяет выбор.
Матрицы более эффективны по памяти:
Матрицы необходимы, если вы планируете выполнять операции типа линейной алгебры.
Фреймы данных также ИМХО лучше подходят для представления (печати) табличной информации, поскольку вы можете применять форматирование к каждому столбцу отдельно.
@Michal не упомянул о том, что матрица не только меньше, чем эквивалентный фрейм данных, но использование матриц может сделать ваш код намного более эффективным, чем использование фреймов данных, часто значительно. Это одна из причин, почему внутренне многие функции R будут приводить к данным матриц, которые находятся во фреймах данных.
Фреймы данных часто намного удобнее; не всегда есть только атомарные порции данных.
Обратите внимание, что у вас может быть матрица символов; Вам не нужно просто иметь числовые данные для построения матрицы в R.
При преобразовании фрейма данных в матрицу обратите внимание, что есть data.matrix() функция, которая обрабатывает факторы соответствующим образом, преобразовывая их в числовые значения на основе внутренних уровней. Принуждение через as.matrix() приведет к матрице символов, если любая из меток фактора не является числовой. Для сравнения:
Я почти всегда использую фрейм данных для своих задач анализа данных, поскольку у меня часто есть больше, чем просто числовые переменные. Когда я кодирую функции для пакетов, я почти всегда приводю к матрице, а затем форматирую результаты как фрейм данных. Это потому, что фреймы данных удобны.
@Michal: матрицы на самом деле не более эффективны для памяти:
. если у вас нет большого количества столбцов:
Я не могу больше подчеркнуть разницу в эффективности между ними! Хотя это правда, что DF более удобны в некоторых случаях анализа данных, они также допускают разнородные данные, и некоторые библиотеки принимают их только, но все это действительно вторично, если вы не пишете одноразовый код для конкретной задачи.
Затем в какой-то момент из любопытства я решил изменить функцию, чтобы собирать путь в матрице. С радостью синтаксис DF и матриц схож, все, что я сделал, это изменил строку, указав df как data.frame, на строку, инициализировав ее как матрицу. Здесь я также должен упомянуть, что в исходном коде DF был инициализирован, чтобы иметь окончательный размер, поэтому позже в коде функции были записаны только новые значения в уже выделенные пробелы, и не было никаких затрат на добавление новых строк в DF. Это делает сравнение еще более справедливым, а также упрощает мою работу, поскольку мне не нужно было ничего переписывать в функции. Изменение только одной строки от первоначального размещения data.frame требуемого размера к матрице того же размера. Чтобы адаптировать новую версию функции к ggplot (), я преобразовал теперь возвращенную матрицу в данные.
После повторного запуска кода я не мог поверить в результат. Код запускается за доли секунды! Вместо примерно 12 секунд. И снова, функция в течение 10 000 итераций считывает и записывает значения только в уже выделенные пространства в DF (и теперь в матрице). И эта разница также для разумного (или скорее небольшого) размера 10000×3.
Или другое более практичное правило: если у вас есть вопрос, такой как в OP, используйте матрицы, поэтому вы будете использовать DF только тогда, когда у вас нет такого вопроса (потому что вы уже знаете, что должны использовать DF, или потому что вы делаете не очень важно, так как код разовый и т. д.).
Но в целом всегда помните об этой эффективности как о приоритете.
Структуры данных в pandas / pd 2
Ядром pandas являются две структуры данных, в которых происходят все операции:
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
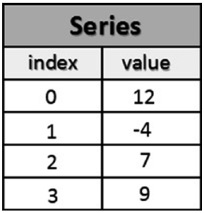
Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
Или же можно выбрать метку, соответствующую положению индекса.
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
Создание Series из массивов NumPy
Фильтрация значений
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
Операции и математические функции
Для операторов можно написать простое арифметическое уравнение.
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Значения NaN
Функции isnull() и notnull() очень полезны для определения индексов без значения.
Series из словарей
Операции с сериями
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
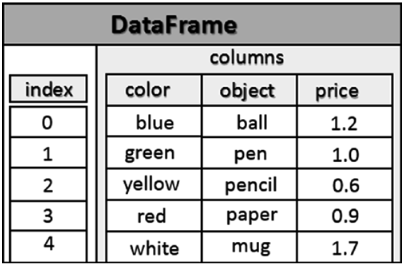
Создание Dataframe
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Выбор элементов
То же можно проделать и для получения списка индексов.
Указав в квадратных скобках название колонки, можно получить значений в ней.
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
Для выбора нескольких строк можно указать массив с их последовательностью.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
Присваивание и замена значений
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
Вхождение значений
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Dataframe из вложенного словаря
В Python часто используется вложенный dict :
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
В отличие от других элементов в структурах данных pandas ( Series и Dataframe ) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
Операции между структурами данных
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Операции между Dataframe и Series
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |



