Горизонтальное масштабирование: разнесение серверов

При выборе платформы для корпоративной системы у крупных компаний есть как минимум один общий критерий — производительность. Если система может выдержать максимум 5000 одновременных пользовательских сессий, а у компании их 20 000, то вряд ли такой программный продукт подойдёт. В этом случае начинает играть роль масштабируемость системы.
Масштабируемость — возможность системы увеличивать свою производительность при увеличении количества выделяемых ей ресурсов.
Виды масштабирования
Существует два вида масштабирования: вертикальное и горизонтальное.
Вертикальное масштабирование— увеличение производительности приложения при добавлении ресурсов в рамках имеющегося оборудования. Например, увеличение оперативной памяти или замена процессора на более мощный. В этом случае масштабируемость ограничена, очень легко достигнуть потолка.
Горизонтальное масштабирование— увеличение производительности приложения за счёт распределения нагрузки между имеющимся и новым оборудованием. До тех пор, пока есть возможность увеличивать количество серверов, есть возможность увеличивать производительность и обеспечивать комфортную работу большего количества пользователей.
Для того чтобы приложение могло поддержать горизонтальное масштабирование, код приложения должен поддерживать механизм взаимодействия и синхронизации серверов между собой. Мы предусмотрели возможности для горизонтального масштабирования, поэтому платформа SimpleOne может использоваться для реализации проекта практически любого уровня нагруженности.
Горизонтальное масштабирование серверов осуществляется на двух уровнях:
В этой статье мы расскажем про то, как в SimpleOne осуществляется горизонтальное масштабирование на первом уровне, — про разнесение серверов.
Разнесение серверов
Система SimpleOne разделена по функциям на четыре группы: клиентский сервер, сервер приложений, сервер БД и сервер файлового хранилища.
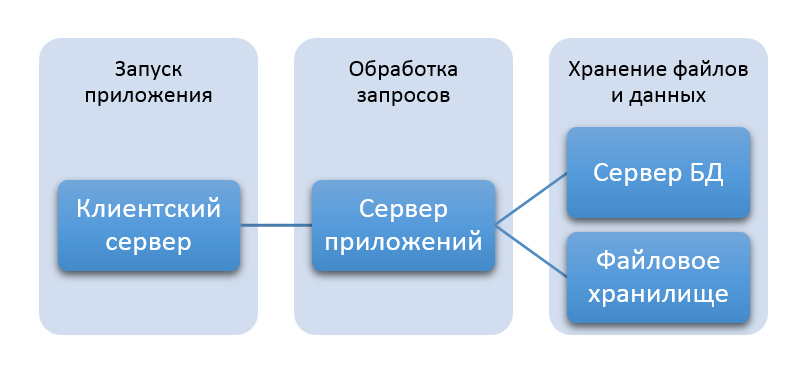 Разбиение системы SimpleOne по функциям
Разбиение системы SimpleOne по функциям
Клиентский сервер
Клиентский сервер отвечает за первичную коммуникацию пользователя с приложением. Этот сервер позволяет запустить приложение, загружая необходимый для работы код: CSS, JS, ReactJS, ConfigJS.
Сервер приложений
После первичного взаимодействия с клиентским сервером все запросы пользователя идут на сервер приложений. Например, пользователь хочет получить лист или список кнопок. Сервер приложений обрабатывает запрос, запрашивает данные и направляет их пользователю.
Сервер баз данных
Сервер БД обслуживает и управляет БД, отвечает за целостность и сохранность данных.
Сервер БД является «узким» местом производительности. Чтобы снизить нагрузку на него, в SimpleOne файлы хранятся на отдельном сервере.
Сервер файлового хранилища
Файлы хранятся в хранилище, доступном по протоколу S3.
Amazon Simple Storage Service (Amazon S3) — это сервис хранения объектов, предлагаемый поставщиками облачных услуг. Основное преимущество решения — возможность хранить файлы любого типа, любого объёма, с высоким уровнем надёжности и доступности.
При запросе файла сервер приложений обращается к файловому хранилищу, которое формирует токен и передаёт его браузеру. Через токен пользователь получает доступ к объекту в файловом хранилище.
В основном компании-разработчики не выносят объёмные файлы (видео, картинки и т. д) на отдельный сервер, а хранят их на сервере баз данных. Разнесение хранения данных и файлов по разным серверам даёт преимущества:
Заключение
Масштабируемость системы играет важную роль для крупных компаний. Горизонтальное масштабирование даёт практически бесконечные возможности для увеличения производительности ESM-платформы SimpleOne, что делает её подходящей для реализации высоконагруженных проектов любого уровня.
Монолитная архитектура. Традиционный метод разработки приложений

Выражение «монолитная архитектура» сразу ассоциируется со словом «монолит». А монолитом еще с давних пор называют большой единый блок из камня или бетона. Монолит — это что-то большое и единое, имеющее общую и мощную структуру. Монолит — это сила и на века.
В программировании «монолитная архитектура» также подразумевает наличие общей и единой платформы, где сконцентрированы все компоненты одной программы. Сколько бы н и насчитывалось подобных компонентов, все они унифицированы и при этом управляются из одного места. В этом и определяется сила «монолитных» приложений.
Монолитная архитектура
Многие современные стартапы выбирают именно монолитную архитектуру приложения, потому что она комфортна при работе небольшими группами разработчиков. При ее использовании все компоненты программы взаимосвязываются и взаимозаменяются — это помогает развивать программу автономной и самодостаточной. Монолитная архитектура считается традиционной и проверенной при разработке приложений, но в то же время многие разработчики считают такой подход в реализации приложений старомодным и уже никуда не годным.
Чтобы понимать, подойдет ли вам такой способ разработки или нет, нужно рассмотреть достоинства и недостатки монолитной архитектуры.
Д остоинства монолитной архитектуры
Простая разработка и простой запуск программы. Из-за того, что вся разработка сконцентрирована в одном месте, легче интегрировать инструменты для облегченной разработки, те же каталоги или библиотеки. Плюс при необходимости изменить элементы программы не нужно вносить изменения по отдельности в разных местах — все делается в одном месте.
Сквозные проблемы практически отсутствуют. Большое количество приложений имеют зависимость от задач, которые совершаются между компонентами программы: логи, ограничения скорости, контрольные журналы и т. д. При монолитной архитектуре эти проблемы практически отсутствуют, так как все сконцентрировано в одном коде и все работает в одном приложении.
Недостатки монолитной архитектуры
Большой объем кода. Если разрабатываемый продукт довольно большой и постоянно масштабируется, то со временем его код разрастается до огромных размеров. Это утяжеляет его понимание и дальнейшее обслуживание. Плюс может наступить момент, когда код будет «перегружен» и потеряет от этого свое качество.
Сложно модернизируется. Иногда нужно добавить в приложение какую-то новую «фишку». При монолитной архитектуре можно столкнуться со множеством препятствий, чтобы это реализовать. Потому что в некоторых случаях добавить какую-то «фишку» означает полностью переписать приложение. А это долго и дорого.
Заключение
Монолитная архитектура хоть и «старая» по своему происхождению, но до сих пор актуальн а и используется многими компаниями. Такая архитектура идеально подходит для стартапов и разработок:
когда нужно быстро развернуть небольшое приложение;
когда создается непроверенный продукт и нужно его быстро создать, чтобы протестировать;
когда просто нет опыта работы с микросервисами;
если изначально известно, что приложение не будет разрастаться до колоссальных масштабов;
если в приоритете разработки программного обеспечения наход я тся именно скорость его работы и производительность.
Поэтому перед использованием монолитной архитектуры нужно все тщательно взвесить. Иногда продумывают такой ход: запуск приложения осуществляют при использовании монолитной архитектуры, а чуть позже, если оно «зашло» пользователю, дробят приложения на микросервисы для удобного масштабирования, тем самым меняя его архитектуру.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Горизонтальное масштабирование команд разработчиков

Еще совсем недавно для расширения своего бизнеса компания покупала более мощный компьютер, а теперь компании покупают много компьютеров прежней производительности. Аналогично происходит и при масштабировании коллективов разработчиков.
Еще недавно переход от вертикального к горизонтальному масштабированию казался непозволительно дорогим, но со временем были разработаны специальные методы, затраты стали меньше, и хотя не все команды разработчиков справляются с горизонтальным масштабированием, те, кому это удается, находятся в авангарде индустрии разработки ПО.
Сегодня компании, достигшие успеха, все реже прибегают к вертикальному масштабированию для расширения возможностей своих информационных систем. Они предпочитают горизонтальное масштабирование, покупая большое количество компьютеров прежней производительности. Добавляя очередной компьютер к ЦОД, мы увеличиваем его мощность, а чтобы увеличить «мощность» команды, приглашаем в нее нового инженера. И если он впоследствии покидает компанию, это не должно вызвать кризиса. Здесь уместно вспомнить закон Фредерика Брукса, согласно которому увеличение численности исполнителей на проекте, отстающем от графика, вызывает еще большее отставание. Так ли это при горизонтальном масштабировании? Вернемся к вопросу позже, а пока обсудим успешные примеры самоорганизации команд. Возможно, истинное горизонтальное масштабирование и недостижимо, но в большинстве случаев можно приблизиться к идеалу путем оптимизации принципов написания кода и планирования.
Вертикальное и горизонтальное масштабирование команды
Несколько лет назад мне довелось участвовать в обычном селекторном совещании в конференц-зале нью-йоркского офиса, когда к нему подключился мой коллега по команде, который в это время был с семьей на свадьбе в Италии. То, что его пришлось отвлечь от отпуска, означало, что у нас было что-то явно не так с организацией работы. Отдыхающему пришлось подключиться к конференции, поскольку больше не к кому было обратиться для решения важного вопроса. Скорее всего, это типичная ситуация. С одной стороны, вы обретаете чувство гордости за то, что так важны для команды. С другой, хотелось бы все-таки насладиться отдыхом. Почему нельзя было найти кого-то еще?
Причина в том, что этот специалист располагал информацией, которой больше ни у кого не было. Когда кто-то держит в голове критически важные сведения, горизонтальное масштабирование команды разработчиков не поможет. В общем случае подобные ситуации неизбежны, но вместе с тем в раздробленности информации обычно виноваты сами участники команд, использующие общепринятые, но порочные практики.
Задайтесь вопросом, сколько времени потребуется новому разработчику на то, чтобы освоиться в группе. Если вам нужно горизонтальное масштабирование, то у новичков должна быть возможность быстро войти в курс дела, чтобы начать приносить пользу сообразно своим способностям, а не времени, проведенному за изучением кодовой базы.
Как именно этого добиться? Основной фактор, определяющий возможность подключения к работе нового участника, — это состояние кода. Если вам досталась безупречная кодовая база, авторы которой сделали все, чтобы изложить в ней свои знания, вы легко ее поймете и начнете дорабатывать. Если код даже качественный, но беспорядочный или лишен важных комментариев, то дорабатывать его будет непросто.
Улучшение принципов написания кода
Два десятка лет тому назад я входил в состав объединения Catalysis [1], которое пропагандировало среди разработчиков преимущества объектно-ориентированного программирования, архитектурного планирования ПО и составления точных спецификаций. Разработчиков тогда непросто было убеждать менять привычные методы. Но перенесемся в наши дни: сегодня широко применяются методы функционального программирования, требующие еще более строгой дисциплины и точности, чем мы пропагандировали в свое время.
Сегодня принципы написания кода полностью изменились, включая языки, инструменты и общепринятые нормы. Идеи, казавшиеся раньше труднореализуемыми, теперь легко воплотить в жизнь. Разработчики воспринимают как должное наглядный граф исходного кода, контракты, которые можно просматривать по щелчку, языки с развитыми системами типов, облегчающими написание самодокументированного кода, а также сопроводительные файлы ReadMe, в которых текст и изображения поясняют то, что нельзя выразить в коде, — например, мотивацию принятия того или иного архитектурного решения. Двадцать лет назад всего этого еще не было. Сегодня, если кодовая база поддерживается в идеальном состоянии, горизонтально масштабировать команду гораздо проще — архитектуру системы можно понять, просто читая код. Что именно требуется для обеспечения идеальной чистоты кода? Четкие, согласованные концепции, связывающие предметную область, архитектуру и код; иерархическая «история», описывающая все уровни системы; стиль кодирования, позволяющий легко выяснить архитектуру; повсеместное применение шаблонов проектирования. Допустим, все это есть и код идеально чист. Как поддерживать его в таком состоянии?
Для этого понадобятся командные процессы, служащие двум целям, одна из которых — дать разработчикам возможность вносить вклад в проект, соответствующий их способностям, а не времени, проведенному в команде. В этом помогут принципы коллективного владения кодом и архитектурой, а также согласованные стандарты качества. Вторая цель — сделать саму концепцию проекта достаточно компактной, чтобы ее могли держать в голове все участники. Выберите базовую архитектуру и набор шаблонов проектирования, чтобы на их основе принимать решения для частных случаев. Также необходимы непрерывный рефакторинг, внимание к требованиям, не касающимся функциональности (в этом поможет журнал пожеланий с цветовой маркировкой), ограничение архитектурных абстракций и усилия по обеспечению консистентности кода. Все эти процессы позволят поддерживать код в хорошей форме, избегая типичной ситуации, когда соответствие запросам пользователей чудесным, но неведомым образом обеспечивает мешанина архитектурных решений и противоречивых решений.
Все перечисленное служит минимизации технического долга. «Со временем мы накопили знания о приложении, модифицируя программу, чтобы она выглядела так, словно мы на протяжении всего проекта понимали, что делаем, и так, будто добиться этого было легко» — так можно описать процеcc рефакторинга, поясняя метафору долга [2]. Понятие «технический долг» можно использовать в качестве синонима безобразного кода, но мне больше по душе версия, которая звучит так: это «то, что происходит, когда вы позволяете коду со временем портиться, лишая его способности выражать концепции предметной области и ценные архитектурные решения» [2].
Улучшение принципов планирования
Еще один путь улучшения горизонтальной масштабируемости команды — изменение принципов планирования, в частности, отказ от таких порочных подходов, как наличие единственного планировщика или архитектора, отсутствие четкого планирования или размытость планов. В 1990-х годах распространенной практикой была разработка большого проекта и распределение фрагментов между группами разработчиков. Если архитектор в какой-то момент был недоступен, то в группе могло не оказаться тех, кто внесет необходимые изменения, хотя сам проект зачастую мог быть слишком подробным в одних отношениях и лишенным должной четкости и продуманности в других. Архитектор мог гордиться своим могуществом и незаменимостью, но в его отсутствие страдала вся группа, и заканчивалось это тем, что приходилось звонить в Италию.
Времена меняются, и сегодня подобные ситуации менее вероятны. Человек, отвечающий за планирование, может не быть техническим специалистом, а сам план строится как описание внешнего поведения (сценариев применения). Риска технической негибкости уже нет, планирование происходит циклично, раз в неделю-две сообразно актуальным требованиям. Но такая свобода таит в себе опасность. Когда все разработчики имеют возможность писать код, необходимый для реализации нужного поведения, а архитектора, отвечающего за контроль над техническими деталями, нет, это может легко привести к резкому усложнению проекта ввиду отсутствия координации усилий.
Действенной может быть практика, когда архитектор все-таки есть (хотя должность может называться и по-другому), он задает первоначальную структуру проекта и шаблоны проектирования, а затем вмешивается по мере необходимости, чтобы поддерживать нужное направление. Современные инструменты и языки характеризуются широтой возможностей, и нередко достаточно сделать разумный первоначальный выбор, чтобы избежать последующих конфликтов. Вместе с тем понимание предметной области разработчиками постоянно расширяется, и лучше, чтобы архитектор за ними приглядывал.
Горизонтальную масштабируемость группы можно обеспечить, если у каждого будет некоторое представление о картине в целом, чтобы все участники в индивидуальном порядке могли принимать оптимальные решения. Но что такое «картина в целом»? Существует рекомендация включать в планы работы команды четыре составляющие: функции, дефекты, архитектурную инфраструктуру и технический долг [3]. Все участники группы должны быть в курсе этих планов, при этом вопросы компромиссов при распределении работы над элементами стоит решать сообща. Таким образом, даже при возникновении помех у всех разработчиков будет представление об общих целях, ближайших задачах и компромиссах. Планирование, осуществляемое подобным образом, может быть весьма эффективным. И даже если с этим справляются не все участники команды, со временем ситуация улучшается. А самое лучшее то, что даже в отсутствие архитектора все может идти гладко. Архитектор вносит свою лепту, направляя проект в целом, но в отдельно взятые периоды времени команда справляется самостоятельно.
Переход от вертикального к горизонтальному масштабированию когда-то казался непозволительно дорогим, но со временем были разработаны специальные методы, и затраты стали меньше — так же как сегодня благодаря развитию инструментов сократились затраты на рефакторинг и менее затратным стало контрактное программирование за счет совершенствования функциональных языков. И хотя я не готов поспорить с законом об увеличении численности участников проекта, отстающего от графика, но сегодня, когда разработчики имеют дело с чистой кодовой базой, параллельно кодированию в группах может выполняться большой объем работы, в том числе благодаря развитию средств, помогающих улучшить координацию. Когда все идет гладко, это значит, что архитектура в целом согласована, шаблоны проектирования содержат решения для большинства возможных проблем, а сам код (и файлы ReadMe) дает разработчикам ответы на возникающие у них вопросы.
Брукс в книге «Мифический человеко-месяц» выражал беспокойство по поводу цены координации: «Так как создание программного продукта является по сути системным проектом, практикой сложных взаимосвязей, то затраты на обмен данными велики и быстро начинают преобладать над сокращением сроков, достигаемым в результате разбиения задачи на более мелкие. В этом случае привлечение дополнительных работников не сокращает, а удлиняет график работ» [4]. Однако Брукс не давал рекомендаций оставить одного человека на проекте, чтобы устранить затраты на координацию. То есть, если благодаря инструментам и специальным методам удается поддерживать координационные расходы на низком уровне, значит, возможность горизонтального масштабирования достигнута. Все технические методы и процессы, упомянутые в статье, уже применяются, хотя и недостаточно широко. Не все команды справляются с горизонтальным масштабированием, но те, кому это удается лучше других, находятся в авангарде индустрии разработки ПО.
Литература
1. D. D’Souza, A. C. Wills. Objects, Components, and Frameworks wit UML: The Catalysis Approach. Boston: Addison-Wesley, 1998.
2. W. Cunningham. Ward explains debt metaphor. Feb. 14, 2009. URL: http://wiki.c2.com/?WardExplainsDebtMetaphor (дата обращения: 03.09.2019).
3. P. Kruchten, R. Nord, I. Ozkaya. Managing Technical Debt: Reducing Friction in Software Development, 1st ed. Boston: Addison-Wesley Professional, 2019. — P. 62–63.
4. F. Brooks. The Mythical Man-Month. Boston: Addison-Wesley, 1995.
Джордж Фэрбенкс ( gf@georgefairbanks.com ) — инженер программного обеспечения, компания Google.
George Fairbanks, Scale Your Team Horizontally. IEEE Software, July/August 2019, IEEE Computer Society. All rights reserved. Reprinted with permission.
Вертикальное и горизонтальное масштабирование, scaling для web
Для примера можно рассмотреть сервера баз данных. Для больших приложений это всегда самый нагруженный компонент системы.
Возможности для масштабирования для серверов баз данных определяются применяемыми программными решениями: чаще всего это реляционные базы данных (MySQL, Postgresql) или NoSQL (MongoDB, Cassandra и др).
Горизонтальное масштабирование для серверов баз данных при больших нагрузках значительно дешевле
Веб-проект обычно начинают на одном сервере, ресурсы которого при росте заканчиваются. В такой ситуации возможны 2 варианта:
MySQL является самой популярной RDBMS и, как и любая из них, требует для работы под нагрузкой много серверных ресурсов. Масштабирование возможно, в основном, вверх. Есть шардинг (для его настройки требуется вносить изменения в код) и репликация, которая может быть сложной в поддержке.
Вертикальное масштабирование 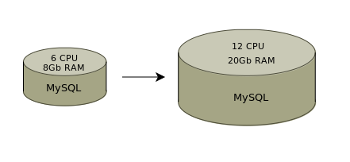
NoSQL масштабируется легко и второй вариант с, например, MongoDB будет значительно выгоднее материально, при этом не потребует трудозатратных настроек и поддержки получившегося решения. Шардинг осуществляется автоматически.
Таким образом с MySQL нужен будет сервер с большим количеством CPU и оперативной памяти, такие сервера имеют значительную стоимость.
Горизонтальное масштабирование
С MongoDB можно добавить еще один средний сервер и полученное решение будет стабильно работать давая дополнительно отказоустойчивость. 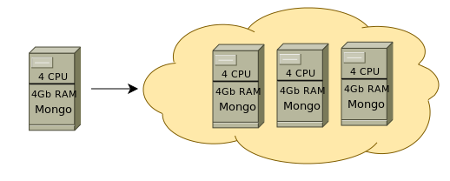
Scale-out или горизонтальное масштабирование является закономерным этапом развития инфраструктуры. Любой сервер имеет ограничения и когда они достигнуты или когда стоимость более мощного сервера оказывается неоправданно высокой добавляются новые машины. Нагрузка распределяется между ними. Также это дает отказоустойчивость.
Добавлять средние сервера и настраивать кластеры нужно начинать когда возможности для увеличения ресурсов одной машины исчерпаны или когда приобретение сервера мощнее оказывается невыгодно
Приведенный пример с реляционными базами данных и NoSQL является ситуацией, которая имеет место чаще всего. Масштабируются также фронтэнд и бэкенд сервера.
H Microservices. Как правильно делать и когда применять? в черновиках

Автор: Вячеслав Михайлов
Монолитные приложения и их проблемы
Все прекрасно знают, что такое монолитное приложение: все мы делали такие двух- или трехслойные приложения с классической архитектурой:

Для маленьких и простых приложений такая архитектура работает прекрасно, но, допустим, вы хотите улучшить приложение, добавляя в него новые сервисы и логику. Возможно, у вас даже есть другое приложение, которое работает с теми же данными (например, мобильный клиент), тогда архитектура приложения немного поменяется:

Так или иначе, по мере роста и развития приложения, вы сталкиваетесь с проблемами монолитных архитектур:
Рано или поздно вы понимаете, что уже ничего не можете сделать со своей монолитной системой. Заказчик, конечно, разочарован: он не понимает, почему добавление простейшей функции требует нескольких недель разработки, а затем стабилизации, тестирования и т. д. Наверняка многие знакомы с этими проблемами.
Развитие системы
Предположим, что вы каким-то образом смогли избежать вышеозначенных проблем и все еще справляетесь со своей системой, но ведь вам наверняка нужно развивать и масштабировать ее, особенно если она приносит в компанию серьезные деньги. Как это сделать?
Три измерения масштабирования
В книге “The Art of Scalability” есть понятие «куб масштабирования» (scale cube) — из книги “The Art of Scalability”. По этому кубу мы видим, что существует три ортогональных способа увеличения производительности приложения: sharding, mirrorring и microservices.

Теорема CAP
Вообще говоря, если мы хотим развивать систему, придется решать следующие вопросы:
Эти вопросы приводят нас к CAP-теореме, сформулированной Брюером в 2000 г.

Теорема это состоит в том, что вы, теоретически, не можете обеспечить системе одновременно и согласованность (consistency), и доступность (availability), и разделяемость (partitioning). Поэтому приходится жертвовать одним из трех свойств в пользу двух других. Так же, как при выборе из «быстро, дешево и качественно» приходится выбирать только два варианта. Теперь рассмотрим разные варианты, которые у нас есть согласно теореме CAP.
CA — consistency + availability
При таком раскладе данные во всех узлах у нас согласованы и доступны. Доступность здесь означает, что вы гарантируете отклик за предсказуемое время. Это время не обязательно маленькое (это может быть минута или больше), но мы это гарантируем. Увы, при этом мы жертвуем разделением на секции — не можем развернуть 300 таких хостов и распределить всех пользователей по этим хостам. Так работать система не будет, потому что не будет согласованности транзакций.
Яркий пример CA — ACID-транзакции, присутствующие в классических монолитах.
CP – consistency + partitioning
Следующий вариант — когда данные во всех узлах согласованы и распределены на независимые секции. При этом мы готовы пожертвовать временем, которое требуется на согласование всех транзакций — отклик будет очень долгим. Это значит, что, если два пользователя последовательно будут запрашивать одни и те же данные, неизвестно, как долго будут согласовываться данные для второго пользователя.
Такое поведение характерно для тех монолитов, которым пришлось масштабироваться, несмотря на древность.
AP — availability + partitioning
Последний вариант — когда система доступна с предсказуемым временем отклика и распределена. При этом нам придется отказаться от целостности результата — наши данные больше не консистентны в каждый момент времени, и среди них появляются устаревшие (от микросекунд до дней). Но, на самом деле, мы всегда оперируем старыми данными. Даже если у вас трехзвенная монолитная архитектура с веб-приложением, когда веб-сервер отдал вам пакет с теми данными, которые вы отобразили для пользователя, они уже устарели. Ведь вы никоим образом не знаете, не пришел ли в этот момент кто-то другой и не поменял эти данные. Так что то, что данные у нас согласованные в конечном счете(eventually consistent) — нормально. «Согласованные в конечном счете» означает, что, если на систему перестанет влиять внешнее воздействие, она придет в согласованное состояние.
Яркий пример — классические DNS-системы, которые синхронизируются с задержкой до дней (во всяком случае, раньше).
Теперь, ознакомившись с теорией CAP, мы понимаем, как можем развивать систему так, чтобы она была быстрой, доступной и распределенной. Да никак! Придется выбрать только два свойства из трех.
Микросервисная архитектура
Что же выбрать? Чтобы сделать правильный выбор, нужно, прежде всего, задуматься, зачем все это нужно, — необходимо четко понимать бизнес-задачи. Ведь решение в пользу микросервисов — очень ответственный шаг. Дело в том, что в микросервисах все значительно сложнее, чем обычно, т. ч. мы можем столкнуться с такой ситуацией:
Вот нельзя просто взять и распилить все на какие-то куски и сказать, что это теперь — микросервисы. Иначе вам придется очень несладко.
Microservices & SOA
А теперь поговорим еще немного о теории. Вы все прекрасно знаете, что такое SOA — сервисно-ориентированная архитектура. И тут у вас наверняка возникнет вопрос, как же SOA соотносится с микросервисной архитектурой? Ведь, казалось бы, SOA — то же самое, о это не совсем так. На самом деле, микросервисная архитектура — частный случай SOA:

Другими словами, микросервисная архитектура — всего лишь набор более строгих правил и соглашений, как писать все те же сервисы SOA.
Что такое микросервисы?
Это архитектурный шаблон, в котором сервисы:
Теперь разберем эти понятия по отдельности.
Что значит «маленький» сервис? Это значит, что сервис в микросервисной архитектуре не может разрабатываться больше чем одной командой. Обычно одна команда разрабатывает где-то 5 – 6 сервисов. При это каждый сервис решает одну бизнес-задачу, и его способен понять один человек. Если же не способен, сервис пора пилить. Потому что, если один человек способен поддерживать всю бизнес-логику одного сервиса, он построит действительно эффективное решение. Ведь бывает так, что зачастую люди, принимая решения в процессе написания кода, просто-напросто не понимают, что именно делают — не знают, как ведет себя система в целом. А если сервис маленький, все намного проще. Этот подход, кстати, мы можем применять отдельно, даже не следуя микросервисной архитектуре в целом.
Что значит «сфокусированный» сервис? Это значит, что сервис решает только одну бизнес-задачу, и решает ее хорошо. Такой сервис имеет смысл в отрыве от остальных сервисов. Другими словами, вы его можете выложить в интернет, дописав security-обертку, и он будет приносить людям пользу.
Что такое «слабосвязанный» сервис? Это когда изменение одного сервиса не требует изменений в другом. Вы связаны посредством интерфейсов, у вас есть решение через DI и IoC — это сейчас стандартная практика, применять которую нужно обязательно. Обычно разработчики знают, почему 🙂
Что такое «высокосогласованный» сервис? Это значит, что класс или компонент содержит все нужные методы решения поставленной задачи. Однако тут часто возникает вопрос, чем высокая согласованность (high cohesion) отличается от SRP? Допустим, у нас есть класс, отвечающий за управление кухней. В случае SRP такой класс работает только с кухней и больше ни с чем, но при этом он может содержать не все методы по управлению кухней. В случае же высокой согласованности, все методы по управлению кухней содержатся только в этом классе, и больше нигде. Это важное различие.
Характеристики микросервисов
Разделение на компоненты (сервисы)
Компоненты бывают двух видов: библиотеки и сервисы, которые взаимодействуют по сети. Мартин Фаулер определяет компоненты как независимо заменяемые и независимо развертываемые. Т. е., если вы можете взять что-то и спокойно заменить на новую версию, — это компонент. А если что-то связано с другим и их независимо заменить нельзя (нужно учитывать контракты, сборки, версии…) —- они вместе образуют один компонент. Если что-то нельзя развернуть независимо, и требуется логика откуда-то еще, это тоже не компонент.
Группировка по бизнес-задачам (сервисы имеют бизнес-смысл)
Вот стандартная компоновка монолита:

Для повышения эффективности разработки вы также зачастую вынуждены делить по этим слоям и команды: есть команда, которая занимается UI, есть команда, которая занимается ядром, и есть команда, которая разбирается в БД.
Если же вы переходите к микросервисной архитектуре, сервисы и команды делятся по бизнес-задачам:

Например, может быть группа, которая занимается управлением заказами, — она группа может обрабатывать транзакции, делать по ним отчеты и т. д. Такая группа будет заниматься и соответствующими БД, и соответствующей логикой, и, может быть, даже UI. Впрочем, в моем опыте UI распиливать пока не удавалось — его приходилось оставлять монолитным. Может быть, нам удастся сделать это в будущем, тогда обязательно расскажите остальным как вы этого добились. Как бы то ни было, даже если UI остается монолитным, все равно гораздо лучше, когда остальное разбито на компоненты. Тем не менее, повторюсь, очень важно понимать, ЗАЧЕМ вы это делаете — иначе однажды придется все переделывать обратно.
Умные сервисы и простые коммуникации
Есть разные варианты взаимодействия сервисов. Бывает, что берут очень умную шину, которая знает и про роутинг, и про бизнес-правила (допустим, какой-нибудь BizTalk), и к сервисам прилетают уже готовые объекты. Тогда получается очень умный middleware и глупые endpoint’ы. Это, на самом деле, — антишаблон. Как показало время (на примере того же интернета), у нас очень простая и незатейливая среда передачи данных — ей абсолютно все равно, что вы передаете, она ничего не знает про ваш бизнес. Все мозги же сидят в сервисах. Это важно понимать. Если же вы будете все складывать в среду передачи, у вас получится умный монолит и тупые сервисы-обертки баз данных.
Децентрализованное хранение
С точки зрения сервисно-ориентированных архитектур и, в частности, микросервисов, децентрализованное хранение — очень важный момент. Децентрализованное хранение значит, что каждый сервис имеет свою и только свою БД. Единственный случай, когда разные службы могут использовать одно хранилище, — если эти службы представляют собой точные копии друг друга. Базы данных друг с другом не взаимодействуют:

Единственный вариант взаимодействия — сетевое взаимодействие между сервисами:

Middleware здесь может быть разный — мы об этом еще поговорим. Обнаружение сервисов и взаимодействие между ними может происходить просто напрямую, через вызов RPC, а может и через какой-нибудь ESB.
Автоматизация развертывания и мониторинга
Автоматизация развертывания и мониторинга — то, без чего к микросервисной архитектуре лучше даже не подходить. Т. ч. вы должны быть готовы в это инвестировать и нанять DevOps-инженера. Вам обязательно понадобится автоматическое развертывание, непрерывная интеграция и поставка. Также вам понадобится непрерывный мониторинг, иначе вы просто не сможете уследить за всеми многочисленными сервисами, и все превратится в какой-то ад. Здесь полезно использовать всякие полезные штуки, которые помогают централизовать логгирование, — их можно не писать, т. к. есть хорошие готовые решения вроде ELK или Amazon CloudWatch.
Design for Failure (Chaos Monkey)
С самого первого этапа, начиная строить микросервисную архитектуру, вы должны исходить из предположения, что ваши сервисы не работают. Другими словами, ваш сервис должен понимать, что ему могут не ответить никогда, если он ожидает каких-то данных. Таким образом, вы сразу должны исходить из ситуации, что что-то у вас может не работать.
Например, для этого компания Netflix разработала Chaos Monkey — инструмент, который ломает сервисы, хаотически их выключает и рвет соединения. Этот нужно, чтобы оценить надежность системы.
Как сервисы будут друг с другом взаимодействовать?
Возьмем пример простого приложения. Картинки, приведенные ниже, я взял из блога Криса Ричардсона на NGINX — там детально рассказывается, что такое микросервисы.
Итак, допустим, у нас есть какой-то клиент (необязательно даже UI-ный), который, чтобы предоставить кому-то нужные данные, взаимодействует с совокупностью других сервисов.

Казалось бы, все просто — клиент может обращаться ко всем этим сервисам. Но на деле это выливается в то, что конфигурация клиента становится очень большой. Поэтому существует очень простой шаблон API Gateway:

API Gateway — первое, что нужно рассматривать, когда вы делаете микросервисную архитектуру. Если у вас в бэкенде некоторое количество сервисов, поставьте перед ними простейший сервис, задача которого — собирать бизнес-вызовы к целевым сервисам. Тогда вы сможете осуществлять маппинг транспорта (транспорт будет не обязательно REST API, как на картинке, а каким угодно). API Gateway предоставляет данные в том виде, в каком они нужны конкретно именно этому типу пользователей. Например, если будет веб- и мобильное приложение, у вас будет два API Gateway, которые будут собирать данные из сервисов и предоставлять их немного по-разному. API Gateway не должен ни в коем случае содержать никакой серьезной бизнес-логики, иначе бы эта логика везде дублировалась, и ее сложно было бы поддерживать. API Gateway только передает данные, и все.
Разные типы микросервисной архитектуры
Итак, допустим, у нас есть UI, API Gateway и десяток сервисов за ним, но этого мало — так нормальное приложение не построишь. Ведь обычно сервисы как-то взаимосвязаны. Я вижу три способа связать сервисы:
Service Discovery
Service Discovery (RPC Style)
Вот простейший вариант Service Discovery:

Здесь у нас есть клиент, который обращается к различным сервисам. Однако, если в конфигурации клиента будет зашит адрес конкретного сервиса, мы будем связаны по рукам и ногам, ведь нам может захотеться развернуть все заново, или же может быть еще один экземпляр сервиса. И тут нам поможет Server-Side Service Discovery.
Server-Side Service Discovery
При Server-Side Service Discovery ваш клиент взаимодействует не напрямую с конкретным сервисом, а с выравнивателем нагрузки (load balancer):

Load balancer существует очень много: они есть у Amazon, у Azure и т. д. Load balancer на основании собственных правил решает, кому отдать вызов, если сервисов больше одного и неясно, где находится сервис.
Тут есть еще один дополнительный сервис, service registry, который также бывает разных типов — в зависимости от того, кто, как и где у него регистрируется. Можно сделать так, чтобы service registry регистрировал все типы сервисов. Load balancer берет все данные у service registry. Таким образом, задача load balancer — просто брать данные о местоположении сервисов из service registry и раскидывать запросы к ним. А задача service registry — хранить регистрационные данные сервисов, и он это делает по-разному: может опрашивать сервисы сам, брать данные из внешнего конфига и т. д. Пространство для маневров здесь видится очень широким.
Client-Side Service Discovery
Client-Side Service Discovery — другой, радикально отличающийся способ взаимодействия.

Здесь нет load balancer, и сервис обращается напрямую к service registry, откуда берет адрес сервиса. Чем это лучше? Тем, что на один запрос меньше — так все работает быстрее. Этот подход лучше предыдущего — но при условии, что у вас доверительная система, в которой клиент — внутренний и не будет использовать информацию, которую принимает от сервисов, во вред (например, для DDoS).
В целом в Service Discovery все достаточно просто — используются достаточно известные технологии. Однако тут возникает сложность — как реализовать более-менее серьезный бизнес-процесс? Все равно сервисы при таком подходе слишком сильно связаны, хотя проблему с точки зрения разворачивания и масштабирования мы решаем. Service instance A знает, что за данными нужно идти к service instance B, а если завтра у вас поменяется половина приложения и функцию service instance B будет выполнять другой сервис, вам придется многое переписывать.
Кроме того, когда возникает транзакционная ситуация и нужно согласовать действия нескольких сервисов, понадобится брокер (дополнительный сервис), который должен все согласовать.
Message Bus
Message Bus нужно уметь готовить и нужно действительно знать, что это такое. Message Bus используется для вполне определенных задач, например, не надо делать по Message Bus запросы request–reply или передавать большие объемы данных. Message Bus (и в принципе паттерн Publish/Subscribe) разрывает поставщиков и потребителей информации: поставщики не знают, кому нужна информация, а потребители не знают, откуда она берется — у одной информации теоретически могут быть разные поставщики и потребители.
И, как ни старайся, в такой системе у вас должен быть дополнительный сетевой вызов — брокеру, который собирает сообщения, и еще один вызов, когда эти сообщения нужно доставить. По моему опыту, передавать большие объемы данных (например, мегабайты) через Message Bus не стоит. Message Bus — шаблон командный; он нужен, чтобы один сервис мог сообщить другому, что у него что-то поменялось, чтобы другие сервисы могли на это среагировать.
В такой ситуации нам очень помогла бы гибридная архитектура. Тогда вы берете и кидаете по Message Bus сообщение, что какие-то данные поменялись. После этого подписчики реагируют на эти данные, идут в registry, забирают по идентификатору отправителя место, куда надо сходить за данными, и уже идут напрямую. Так вы очень многое экономите и разгрузите вашу шину.
Message Bus: «за» и «против»

Достоинства Message Bus:
Недостатки Message Bus:
Event Driven Architecture — архитектура, управляемая событиями
Когда наши сервисы взаимодействуют в стиле RPC, все понятно: у нас есть сервис, который связывает всю бизнес-логику, собирает данные из других сервисов и возвращает их, но что делать в случае архитектуры, управляемой событиями? Мы не знаем, куда идти, — у нас есть только сообщения.
В силу того, что сервисы работают только со своими хранилищами, у нас часто возникает ситуация, когда изменения в одном сервисе требуют изменений в другом. Например, у нас есть какой-то заказ (order), и нам нужно проверить лимиты, хранящиеся в другом сервисе (customer service):

У этой проблемы есть два решения.
Решение 1
Когда вы инициируете процесс создания заказа, посылаете в шину сообщение о создании сущности:

Сервис, который заинтересован в этих событиях, подписывается на них и получает идентификацию:

Затем он выполняет какое-то внутреннее действие и возвращает ответ, который потом прилетает в сервис заказов, в шину:

Все это называется конечной согласованностью (eventual consistency). Происходит это не атомарно, а за счет технологии гарантированной доставки Message Bus. При этом взаимодействие сервисов с шиной — транзакционное, и шина обеспечивает доставку всех сообщений. Поэтому мы можем быть уверены, что в конце концов до наших сервисов все долетит (если, конечно, не решим почистить сообщения брокера через консоль администрирования).
Если стандартная модель называется ACID, такая транзакционная модель называется BASE — Basically Available, Soft state, Eventual consistency, что расшифровывается примерно так: состояние, которое вы в итоге получаете, называется “soft state”, потому что вы не до конца уверены, что это состояние действительно актуально.
Решение 2
Есть и второй способ. Может оказаться, что для принятия решений в этой системе вам не хочется (или вы не можете в силу каких-то требований) каждый раз отправлять сообщение в другой сервис, ведь время отклика здесь будет большим. В такой ситуации сервис, который владеет некой информацией, — по кредитному лимиту, как в нашем примере, — в момент изменения кредитного лимита оповещает всех заинтересованных, что информация по данному клиенту поменялась. Сервис, которому нужно проверять кредитный лимит, его проверяет и сохраняет себе проекцию нужных данных, т. е. только те поля, которые ему нужны. Конечно, это будет дубликат данных, но позволит сервису никуда не обращаться, когда будет заказ.
Здесь снова срабатывает конечная согласованность: вы можете получить заказ, проверить его кредитный лимит и учесть его как выполненный. Но т. к. в этот момент кредитный лимит мог поменяться, может оказаться, что он не соответствует заказу, и вам придется выстраивать блоки компенсации — писать дополнительный код, который будет реагировать на такие внештатные ситуации. В этом вся сложность сервисных архитектур — нужно заранее понимать, что данные, которыми вы оперируете, могут оказаться устаревшими, что может привести к неправильным действиям.
Есть еще и третий, очень серьезный подход — Event Sourcing. Это большая тема, требующая отдельного обсуждения. В Event Sourcing вы не храните состояния объектов — вы их строите в реальном времени, а храните только изменения объектов (фактически, намерения пользователей что-то поменять). Допустим, происходит что-то в UI, например, пользователь хочет сделать заказ. Тогда вы сохраняете не изменение заказа, не новое состояние, а отдельно сохраняете внешние запросы: от пользователя, от других сервисов и вообще откуда угодно. Зачем это нужно? Это нужно для ситуации компенсации — тогда вы можете откатить состояние системы назад и действовать иначе.
Вообще, Message Bus — очень большая тема, в рамках которой очень многое можно рассказать о согласовании событий. Например, можно упомянуть Saga — маленький воркфлоу, который сейчас реализуют, по крайней мере, NServiceBus и MassTransit. Saga — по сути, машина состояний, которая реагирует на внешние изменения, благодаря которой вы знаете, что происходит с системой. При этом из любого состояния вы можете сделать блок компенсации. Т. ч. Saga — хороший инструмент реализации конечной согласованности.
Переход от монолита к микросервисам
Теперь хочется поговорить, как переходить от монолита к микросервисам, если вы решили, что это действительно то, что нужно. Итак, у вас есть большой монолит. Как теперь делить его на части?
Вы вынимаете нечто, ограниченное по бизнес-логике (то, что называется ограниченным контекстом в DDD). Конечно, для этого придется понять монолит. Например, хороший кандидат на выделение в отдельный сервис — часть монолита, которая требует частых изменений. Благодаря этому, вы получаете незамедлительную выгоду от выделения сервсиа — не придется тестировать монолит часто. Также хорошо выделять в отдельный сервис то, что доставляет наибольшее количество проблем и плохо работает.
Когда вы разделяете монолит на сервисы, обращайте внимание, как у вас структурированы команды. Ведь есть эмпирический закон Конвея (Conway’s law), который говорит, что структура вашего приложения повторяет структуру вашей организации. Если ваша организация построена на технологических иерархиях, построить микросервисную архитектуру будет очень трудно. Поэтому нужно выделить feature-команды, которые будут иметь все необходимые навыки, чтобы написать нужную логику от начала до конца.
На самом деле, редко бывает, что у нас чистая микросервисная архитектура. Чаще всего мы имеем нечто среднее между монолитом и микросервисами. Обычно есть какой-то большой исторически сложившийся код, и мы понемногу стараемся распутывать его и отделять от него части.
Если же мы делаем проект с нуля, нужно выбрать — монолит или микросервисы?
Монолит лучше выбирать в следующих случаях:
Микросервисы лучше выбрать, если:
Микросервисы: «за» и «против»
Немного о мониторинге и тестировании мироксервисной системы
Есть инструменты, которые позволяют развертывать такую систему и следить за ней, например, ZooKeeper, который решает проблему конфигурирования за нас. Также есть такие инструменты типа Logstash, Kibana, Elastic, Serilog, Amazon Cloud Watch. Все они следят за вашими сервисами.
Как тестировать микросервисную систему? Я вижу это следующим образом. У вас есть сервис, который решает какую-то бизнес-задачу. Ваша цель — протестировать его бизнес-контракты. Большинство тестов, которые вы делаете — модульные, которые для кода, написанного в рамках этого сервиса. Это — низ пирамиды тестирования. Следующий уровень — интеграционное тестирование, которое проверяет, как этот сервис отвечает на стандартные запросы. Тут у вас огромное пространство для интеграционного тестирования кода, написанного изолированно. Следующий этап — использование разных инструментов, чтобы гарантировать, что контракт не поменялся. В нашем проекте мы использовали Swagger, который позволяет зафиксировать контракт.
Манифест Джеффа Безоса (Amazon CEO)
Напоследок приведу хороший пример крайне успешного применения микросервисной архитектуры — Amazon.
Все началось с того, что в 2000 г. Джефф Безос, глава Amazon, написал для всех отделов своей компании следующий манифест:
Вкратце, суть манифеста такова: «Вся функциональность выставляется наружу только посредством интерфейсов сервисов. Команды (на самом деле — сервисы и их команды) взаимодействуют только посредством сетевых интерфейсов: никакого взаимодействия с базами данных, никакой общей памяти и т. д. — вне зависимости от технологий и без исключений.
Таким образом, Джефф обязал все сервисы быть готовыми, что их выставят в публичный доступ. Это привело к уровню, когда можно предлагать услугу как сервис. Это стало залогом успеха компании. Мы знаем, к чему в итоге привел этот манифест — к целой индустрии Amazon и частичное выросшей из этого индустрии AWS.



