Урок по оптимизации серверной части веб-приложений

Привет, Хабр! Меня зовут Алексей Приставко, я директор по веб-проектам в компании DataLine. Моя сегодняшняя статья посвящена тому, как исправить или предотвратить проблемы с производительностью бэк-энда веб-приложений.
Речь пойдет о том, как оптимизировать веб-приложения, которые страдают от хронических проблем с масштабируемостью, производительностью или надежностью.
Всем заинтересовавшимся – добро пожаловать под кат!
Терминология
Давайте для начала разберемся в терминологии. Говоря о производительности веб-проектов или веб-систем, я в первую очередь имею в виду back-end и серверную составляющую. То, что происходит при загрузке страниц в браузере – это совершенно другая история, которой, скорее всего, посвящу отдельную статью.
Теперь, когда мы разобрались с ключевыми понятиями и освежили актуальную терминологию, пора переходить непосредственно к азам оптимизации и лайфхакам.
С чего начать оптимизацию
Как понять, с чего начать оптимизацию? Прежде, чем вы броситесь оптимизировать, сделайте глубокий вдох и потратьте время на исследование работы приложения.
Обязательно нарисуйте подробную схему. Отобразите на ней все компоненты приложения и их взаимосвязи. Изучив эту схему, вы сможете обнаружить ранее неприметные уязвимости и потенциальные точки отказа.
«Что? Где? Когда?» — оптимизируем запросы
Особое внимание уделите синхронным запросам. Напомню, это такие запросы, когда в одном и том же потоке мы отправляем запрос и ждем по нему ответа. Тут как раз кроются причины серьезных тормозов, когда на другой стороне что-то идет не так. Поэтому, если можете сократить число синхронных запросов или заменить их на асинхронные, сделайте это.
Вот маленькие хитрости, которые помогут вам отследить запросы:
Совет: Если какая-либо точка «собирает» множество мелких запросов, попробуйте объединить их в один большой запрос для сокращения накладных расходов. Результаты долгих запросов часто имеет смысл сохранить в кэш.
Кэшируем с умом
Существуют общие правила кеширования, на которые стоит опираться при оптимизации:
Совет 1: Делайте компонентное кеширование готовой странички на стороне Nginx с помощью Edge Side Includes. Оно хорошо ложится на микросервисную/SOA архитектуру и разгружает систему в целом, значительно улучшая скорость отклика.
Совет 2: Следите за размером объектов в кэше, показателем hit ratio и объемами записи/чтения. Чем больше объект, тем дольше он будет обрабатываться. Если вы пишете в кэш чаще или больше, чем читаете, такой кэш — вам не товарищ. Его стоит или убрать, или подумать над повышением его эффективности.
Совет 3: Используйте собственные кэши баз данных там, где это возможно. Их правильное конфигурирование может качественно ускорить работу.
Профили нагрузки
Переходим к профилям нагрузки. Как вы знаете, есть два основных типа: OLAP и OLTP.
Совет: Запросы на чтение из админки, как правило, обрабатываются по типу OLAP. Создайте под эту задачу отдельную копию БД и веб-сервер, чтобы разгрузить основную систему.
Базы данных
Итак, мы закономерно подошли к одному из самых сложных этапов оптимизации — а именно, к оптимизации базы данных.
Напомню вам общее правило: чем меньше объем базы, тем быстрее она работает. Сама организация базы данных имеет решающее значение, когда дело касается скорости.
По возможности храните исторические данные, логи приложения и часто используемые данные в разных базах данных. Еще лучше — разнесите их на разные сервера. Это не только облегчит жизнь основной БД, но и даст больше пространства для дальнейшей оптимизации, к примеру в ряде случаев позволит использовать разные индексы под разную нагрузку. Также «однотипность» нагрузки упрощает жизнь планировщику и оптимизатору запросов сервера БД.
И снова о важности планирования
Чтобы не ломать голову над оптимизацией там, где она не сильно нужна, выбирайте железо, исходя из задач.
Масштабирование
Выше я описал ключевые механики повышения производительности приложения без увеличения его физических ресурсов.
Теперь мы поговорим о том, как выбрать стратегию масштабирования и повысить отказоустойчивость.
Существует два вида масштабирования системы:
Растём в высоту
Начнем с выбора стратегии вертикального масштабирования.
Для начала рассмотрим увеличение мощности системы. Если ваша система работает в рамках одного сервера, придется сделать выбор между повышением мощности текущего сервера или покупкой еще одного.
Может показаться, что первый вариант проще и безопаснее. Но дальновиднее будет докупить еще один сервер и бонусом к производительности получить большую отказоустойчивость. Об этом я говорил в начале статьи.
Если в вашей системе несколько серверов и стоит выбор — увеличить мощность существующих или докупить еще несколько, обратите внимание на финансовую сторону. Например, один мощный сервер может оказаться дороже, чем два на 50% «слабее». Поэтому резонно будет остановиться на втором компромиссном варианте. В то же время, при большом количестве серверов решающее значение имеет соотношение производительности, энергопотребления и стоимости полной стойки.
Растём в ширину
Горизонтальное масштабирование системы — это история про отказоустойчивость и кластеризацию. В общем случае, чем больше экземпляров одной сущности мы имеем, тем выше отказоустойчивость целого решения.
Вероятно, первое, что вам захочется масштабировать – это серверы приложений. Первое препятствие на этом пути – организация работы с централизованными источниками данных. Помимо баз данных, это еще и сессионные данные, и статический контент. Вот что я советую сделать:
«Подтягиваем» базы данных
Сложнее всего масштабировать базы данных. Для этого есть две основные техники: шардирование и тиражирование. Рассмотрим их.
При тиражировании мы добавляем в систему полностью идентичные копии базы данных, при шардировании – логически разделенные части, шарды. При этом, шардирование крайне желательно проводить параллельно с репликацией (тиражированием) каждого шарда, чтобы не потерять отказоустойчивость.
Помните: зачастую кластер БД состоит из одной master-ноды, принимающей на себя поток записи, и нескольких slave-нод, используемых для чтения. С точки зрения отказоустойчивости, это немногим лучше одиночного сервера, так как общая отказоустойчивость определяется наименее устойчивым элементом системы.
Схемы с более, чем двумя мастерами баз данных (топология «кольцо») без подтверждения записи на каждом из серверов, очень часто страдают от неконсистентности. В случае сбоя одного из серверов восстановить логическую целостность данных в кластере будет крайне затруднительно.
Совет: Если в вашем случае не рационально иметь несколько мастер-серверов, предусмотрите архитектурную возможность работы системы без мастера хотя бы в течение часа. В случае аварии это даст вам время на замену сервера без простоя всей системы.
Совет: Если есть необходимость держать более 2-х мастеров баз данных, рекомендую вам рассмотреть NoSQL-решения, так как многие из них имеют встроенные механизмы приведения данных в консистентное состояние.
В погоне за отказоустойчивостью ни в коем случае не забывайте, что репликация страхует вас только от физического отказа сервера. Она не спасет от логической порчи данных из-за ошибки пользователя.
Помните: Любые важные данные необходимо бэкапить и хранить в виде независимой не редактируемой копии.
Вместо заключения
Напоследок — пара советов про производительность при создании резервных копий:
Совет 1: Снимайте данные с отдельной реплики базы данных, чтобы не нагружать активный сервер сверх меры.
Совет 2: Имейте под рукой дополнительную, слегка «отстающую» по времени реплику базы данных. В случае аварии это поможет уменьшить количество потерянных данных.
Приведенные в этой статье методы и техники ни в коем случае нельзя применять вслепую, без анализа текущей ситуации и понимания, чего бы вам хотелось достичь. Вы можете столкнуться с «переоптимизацией», и полученная система окажется лишь на 10% более быстрой, но на 50% – более уязвимой к авариям.
На этом всё. Если у вас остались какие-то вопросы, я с удовольствием отвечу на них в комментариях.
Пять способов оптимизации кода для Android 5.0 Lollipop
Как сделать программы быстрее? Один из эффективных способов – оптимизация кода. Зная особенности платформы, для которой создаётся приложение, можно найти эффективные способы его ускорения.

Предварительные сведения
ART (Android RunTime) – это новая среда исполнения Android-приложений. В Android 5.0 Lollipop ART впервые используется по умолчанию. Она включает в себя множество усовершенствований, направленных на улучшение производительности. В этом материале мы расскажем о некоторых новых возможностях ART, сравним её с ранее используемой средой исполнения Android Dalvik и поделимся пятью советами, которые позволят сделать ваши приложения быстрее.
Что нового в ART?
В ходе профилирования множества Android-приложений, которые исполнялись в среде Dalvik, были обнаружены две ключевые особенности, на которые пользователи обращают особое внимание. Первая особенность – время, необходимое для запуска приложения. Вторая – количество разного рода «замедлений» (jank). В худших проявлениях это – запинающийся звук, дёрганая анимация, а то и вовсе – неожиданная остановка приложения. Обычно случается это из-за того, что приложению требуется слишком много времени для подготовки следующего кадра. Как результат, оно просто не успевает за частотой обновления экрана устройства. Скорость формирования кадров может стать проблемой в том случае, если следующий кадр формируется гораздо быстрее или медленнее, чем предыдущий. Если происходит что-то подобное, пользователь видит рывки в работе элементов интерфейса. Это делает взаимодействие с программой гораздо менее удобным, чем хотелось бы и пользователям, и разработчикам. В ART есть несколько новых возможностей, предназначенных для решения вышеописанных проблем.
Сравнение производительности ART и Dalvik
Когда ART только выпустили, в виде предварительной версии на Android KitKat 4.4, появились критические замечания о его производительности в сравнении с Dalvik. Надо сказать, что такое сравнение нельзя назвать честным. Ведь сравнивали раннюю предварительную версию ART со зрелым продуктом, подвергнутым за годы работы над ним множеству улучшений. В результате этих ранних тестов некоторые приложения работали в ART-среде медленнее, чем в Dalvik.
Сейчас у нас появилась возможность сравнить повзрослевшую среду ART, которая используется в массово производимых устройствах, с Dalvik. Так как в Android 5.0 используется только ART, прямое сравнение ART и Dalvik возможно лишь в том случае, если сначала выполнить тесты на некоем устройстве с установленным Android KitKat 4.4, получив данные для Dalvik-среды, затем – обновить его до Android Lollipop 5.0 и провести ту же серию тестов для ART-окружения.
При подготовке этого материала мы проделали подобные тесты с планшетом SurfTab xintron i7.0, который построен на базе процессора Intel Atom. Сначала на нём была установлена Android 4.4.4, и, соответственно, при испытаниях использовался Dalvik, потом устройство обновили до Android 5.0. и протестировали быстродействие ART.
Так как тесты проходили на разных версиях Android, существует возможность того, что некоторые из обнаруженных улучшений исходят не от ART, а от других усовершенствований Android. Однако, основываясь на проведенном нами внутреннем анализе производительности, мы можем говорить о том, что именно использование ART является основной причиной роста производительности системы.
Мы использовали тесты производительности, в которых Dalvik, за счёт агрессивной оптимизации кода, который исполняется по многу раз, способен получить преимущество. Кроме того, мы тестировали системы с использованием симулятора игровых приложений, который разработан Intel.
Исходя из полученных данных, можно сделать вывод о том, что ART превосходит Dalvik во всех из проведенных нами тестов. В некоторых случаях это превосходство весьма значительно.
Относительные показатели тестирования ART (Android Lollipop) и Dalvik (Android KitKat)
Подробности о тестовых приложениях, которыми мы пользовались, вы можете найти, пройдя по следующим ссылкам:
Относительные показатели количества кадров в секунду при тестировании производительности в средах ART и Dalvik
В результате тестирования удалось выяснить, что в ART характеристики кадров более постоянны, чем в Dalvik, с меньшим количеством «неправильных» кадров. Как результат, в ART интерфейс приложений работает более гладко.
Относительные показатели «неправильных» кадров в секунду при тестировании в средах ART и Dalvik
Полученные результаты позволяют с уверенностью говорить о том, что сегодня ART позволяет добиться лучшего восприятия приложений пользователями и большей производительности, чем Dalvik.
Перенос программного кода с Dalvik на ART
Переход от Dalvik к ART прозрачен, большинство приложений, которые работают в среде Dalvik, будут работать и в среде ART без необходимости модификации их кода. В результате, когда пользователи обновляют систему, приложения начинают работать быстрее без каких-либо дополнительных усилий. Однако, особенно если ваши приложения используют Java Native Interface, их не помешает протестировать в среде ART. Дело в том, что в ART используется более строгий механизм обработки JNI-ошибок, чем в Dalvik. Здесь можно узнать подробности об этом.
Пять советов по оптимизации кода
Производительность большинства приложений, которые будут запускаться в среде ART, увеличится только из-за тех улучшений платформы, о которых мы говорили выше. Однако, существует набор рекомендаций, следуя которым можно оптимизировать приложения для достижения еще большей производительности. Каждый из описанных ниже приёмов оптимизации кода снабжён простым примером кода, иллюстрирующим особенности его работы.
Невозможно заранее предсказать, на какой именно прирост производительности можно рассчитывать, используя тот или иной подход к оптимизации. Дело здесь в том, что все приложения разные, их итоговое быстродействие очень сильно зависит от остального кода и от особенностей их использования. Однако мы объясним, почему предлагаемые методы оптимизации способны улучшить скорость работы приложений. Для того чтобы оценить их воздействие на ваше приложение, испытывайте их, применяя к своему коду.
Рекомендации, которые мы предлагаем, применимы довольно широко, но мы ориентируемся на то, что при работе с ART улучшения будут восприняты компилятором dex2oat, который генерирует двоичный исполняемый код из dex-файлов и оптимизирует его.
Совет №1. Всегда, когда возможно, используйте локальные переменные вместо общедоступных полей класса
Ограничивая область видимости переменных, вы не только улучшите читаемость кода и уменьшите число потенциальных ошибок, но и сделаете его лучше подходящим для оптимизации.
В блоке неоптимизированного кода, который показан ниже, значение переменной v вычисляется во время исполнения приложения. Это происходит из-за того, что данная переменная доступна за пределами метода m() и может быть изменена в любом участке кода. Поэтому значение переменной неизвестно на этапе компиляции. Компилятор не знает, изменит ли вызов метода some_global_call() значение этой переменной, или нет, так как переменную v, повторимся, может изменить любой код за пределами метода.
В оптимизированном варианте этого примера v – это локальная переменная. А значит, её значение может быть вычислено на этапе компиляции. Как результат – компилятор может поместить значение переменной в код, который он генерирует, что поможет избежать вычисления значения переменной во время выполнения.
| Неоптимизированный код | Оптимизированный код |
Совет №2. Используйте ключевое слово final для того, чтобы подсказать компилятору то, что значение поля – константа
Ключевое слово final можно использовать для того, чтобы защитить код от случайного изменения переменных, которые должны быть константами. Однако оно позволяет улучшить производительность, так как подсказывает компилятору, что перед ним именно константа.
Во фрагменте неоптимизированного кода значение v*v*v должно вычисляться во время выполнения программы, так как значение v может измениться. В оптимизированном варианте использование ключевого слова final при объявлении переменной и присвоении ей значения, говорит компилятору о том, что значение переменной меняться не будет. Таким образом, вычисление значения можно произвести на этапе компиляции и в выходной код будет добавлено значение, а не команды для его вычисления во время выполнения программы.
| Неоптимизированный код | Оптимизированный код |
Совет №3. Используйте ключевое слово final при объявлении классов и методов
Так как любой метод в Java может оказаться полиморфными, объявление метода или класса с ключевым словом final указывает компилятору на то, что метод не переопределён ни в одном из подклассов.
В неоптимизированном варианте кода перед вызовом функции m() нужно произвести её разрешение.
В оптимизированном коде, из-за использования при объявлении метода m() ключевого слова final, компилятор знает, какая именно версия метода будет вызвана. Поэтому он может избежать поиска метода и заменить вызов метода m() его содержимым, встроив его в необходимое место программы. В результате получаем увеличение производительности.
| Неоптимизированный код | Оптимизированный код |
Совет №4. Избегайте вызывать маленькие методы через JNI
Существуют веские причины использования JNI-вызовов. Например, если у вас есть код или библиотеки на C/C++, которые вы хотите повторно использовать в Java-приложениях. Возможно, вы создаёте кросс-платформенное приложение, или ваша цель – увеличение производительности за счет использования низкоуровневых механизмов. Однако, важно свести количество JNI-вызовов к минимуму, так как каждый из них создаёт значительную нагрузку на систему. Когда JNI используют для оптимизации производительности, эта дополнительная нагрузка может свести на нет ожидаемую выгоду. В частности, частые вызовы коротких, не производящих значительной вычислительной работы JNI-методов, способны производительность ухудшить. А если такие вызовы поместить в цикл, то ненужная нагрузка на систему лишь увеличится.
Совет №5. Используйте стандартные библиотеки вместо реализации той же функциональности в собственном коде
Стандартные библиотеки Java серьёзно оптимизированы. Если использовать везде, где это возможно, внутренние механизмы Java, это позволит достичь наилучшей производительности. Стандартные решения могут работать значительно быстрее, чем «самописные» реализации. Попытка избежать дополнительной нагрузки на систему за счёт отказа от вызова стандартной библиотечной функции может, на самом деле, ухудшить производительность.
В неоптимизированном варианте кода показана попытка избежать вызова стандартной функции Math.abs() за счёт собственной реализации алгоритма получения абсолютного значения числа. Однако, код, в котором вызывается библиотечная функция, работает быстрее за счёт того, что вызов заменяется оптимизированной внутренней реализацией в ART во время компиляции.
| Неоптимизированный код | Оптимизированный код |
Тестирование техник оптимизации
Выясним, какова разница в производительности оптимизированного и неоптимизированного кода из совета №2 при запуске его в среде ART. Для эксперимента будем использовать планшет Asus Fonepad 8, построенный на базе CPU Intel Atom Z3530. Устройство обновлено до Android 5.0.
Вот код, который мы подвергаем испытаниям:
Разница методов testUnoptimized и testOptimized заключается лишь в том, что второй оптимизирован, переменная w, которая в нём используется, объявлена с ключевым словом final.
В ходе тестов каждый из методов будет вызван заданное количество раз. Циклы, в которых производятся эти вызовы, выполняются в фоновом потоке. После завершения тестов результаты выводятся в пользовательском интерфейсе приложения.
Интерфейс приложения для тестирования результатов оптимизации
В таблице показаны результаты десяти последовательных запусков теста в release-версии приложения. Каждый из отдельных показателей получен в результате выполнения циклического вызова соответствующего метода 10 миллионов раз.
Сравнение скорости выполнения оптимизированного и неоптимизированного кода
| № | Оптимизировано, мс. | Не оптимизировано, мс. |
| 1 | 25 | 193 |
| 2 | 21 | 203 |
| 3 | 30 | 220 |
| 4 | 25 | 175 |
| 5 | 23 | 184 |
| 6 | 28 | 177 |
| 7 | 30 | 186 |
| 8 | 27 | 191 |
| 9 | 34 | 212 |
| 10 | 27 | 174 |
| Среднее | 27 | 191.5 |
В результате оказалось, что оптимизированный метод выполняется, в среднем, в 7 раз быстрее неоптимизированного.
Исходный код проекта, подходящий для импорта в Android Studio, можно найти здесь.
Оптимизации Intel в ART
Intel работала с OEM-производителями устройств, предоставляя им оптимизированную, в расчёте на процессоры Intel, версию Dalvik. То же самое происходит и в случае с ART, в результате производительность новой среды исполнения, со временем, будет увеличиваться. Оптимизированные версии кода можно будет получить либо в Android Open Source Project (AOSP), либо – напрямую у производителей устройств. Как и прежде, оптимизации прозрачны и для пользователей и для разработчиков, то есть, для того, чтобы воспользоваться их преимуществами, ни тем ни другим не придётся прилагать дополнительных усилий.
Для того чтобы узнать подробности об оптимизации Android-приложений для устройств, построенных на базе процессоров Intel, ознакомиться с компиляторами, посетите Intel Developer Zone.
Пять шагов по оптимизации производительности приложения для Андроид
В этой небольшой статье я хочу поделиться с вами опытом, как программно оптимизировать производительность приложения Андроид за 5 простых шагов на примере создания цифровой версии игры «Корона Эмбера».
До создания серьезных приложения со сложной структурой View и Layout’ов мы особо не задумывались над тем, как простые и логичные действия в стиле «смотрите, я набросал дизайн из лэйаутов» могут серьезно замедлить работу всей программы.
Помимо прочего, задача с «Короной Эмбера» осложнялась еще и тем, что игра, которую мы задумали перенести на Андроид платформу, была сама по себе достаточно насыщенной различными компонентами, которые как-то надо было умещать на игровом поле или рядом с ним.
В статье я собрал наш успешный опыт и облёк его в удобную и читабельную форму, полезную для тех, кто все еще гуглит «как программно оптимизировать приложение под Андроид» или «почему мое приложение лагает».
Итак. Исходная точка (то, как это все выглядело ДО оптимизации)
Дизайн приложения был создан из «правильной» кучи около двух сотен View и десятка Layout’ов. Загрузка игрового поля происходила около 5 секунд, а почти каждое действие зависало еще на 1-2 секунды. И если на прогрессивных устройствах и эмуляторах лаги были практически незаметны, то на большинстве менее современных устройств картина выглядела достаточно печальной.

Понятно, что это не устраивало ни меня, ни нашу команду, ни тестеров. И хотя мы были искреннее уверены, что все оптимизировано дальше некуда, мы принялись искать информацию.
Часть знаний, которыми я хочу поделиться, мы нашли здесь — классные видео-уроки с русскими субтитрами (рекомендую), часть — на Хабре, часть — в глубинах Интернета, на том же сайте Google Developers.
Причем, каждый раз получая новую порцию и проводя очередную оптимизацию, мы были уверены «все теперь дальше некуда, быстрее не будет» и с каждым шагом открывали для себя все больше и больше нового.
И вот, как это происходило.
Шаг 1. Измерение
По сути это даже не шаг, а настойчивая рекомендация постоянно измерять свою производительность. Для этого в Андроид Студио предусмотрено несколько специальных программ: Android Device Monitor с HierarhyViewer, SystemTracing, Method Profiling; Android Monitor с Memory, CPU и GPU мониторами. Описывать их работу не цель данной статьи, вы легко можете найти гайды здесь же, на Хабре, или в упомянутых видео-уроках.
Суть в том, что чтобы оптимизировать производительность, нужно сначала понять где же она «спотыкается».
Хотя, даже без измерения, есть несколько вещей, на которые необходимо обращать внимание каждому разработчику и мы шагаем дальше.
Шаг 2. Оптимизация иерархии и снижение веса
Основная потеря производительности приложений происходит при пересчете и перерисовке отображенных Layout’ов. Причем чем «тяжелее» лэйаут — тем дольше происходит перерасчет его показателей. И тут надо обратить внимание на следующие моменты:
— в вашей иерархии не должно быть вложенных LinearLayout с параметрами «weigh» (вес). Измерение такого лэйаута занимает в два (три, четыре! — в зависимости от вложенности) больше времени. Лучше заменить эту конструкцию на GridLayout (или support.v7.GridLayout для API меньше 21);
— некоторые LinearLayout можно заменить на RelativeLayout, тем самым убрав дополнительные вложения, например;
— оказывается, RelativeLayout также измеряется дважды. Где возможно — его нужно заменить на более «легкий» FrameLayout.
Изучив нашу разметку мы с ужасом обнаружили, что в ней есть вложенные до четырех (!) раз LinearLayout с параметром вес, игровое поле состоит из почти сотни RelativeLayout (клетки поля), а некоторые Layout просто не нужны.
(Зеленым отмечено допустимое вложение, желтым — нежелательное, оранжевым — опасное, красным — «никогда-так-не-делайте!»)
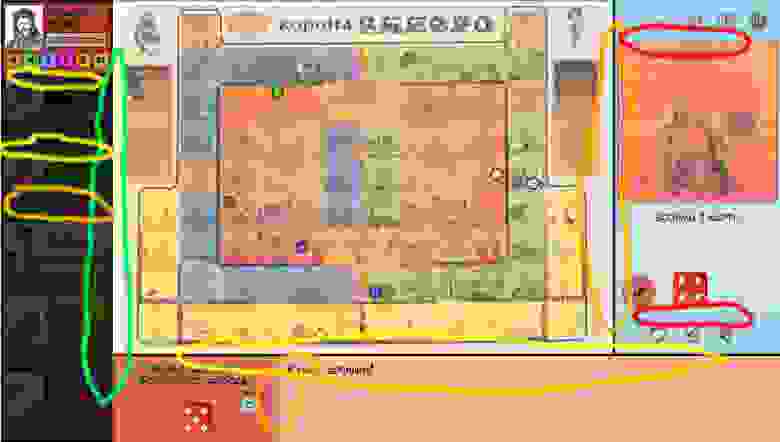
После этого мы немного переработали структуру. «Персонажа» вынесли в отдельный фрагмент с RelativeLayout, все вложенные Linear заменили на (один!) support.v7.GridLayout, а все RelativeLayout (на скрине их не видно — это клетки поля) заменили на FrameLayout. Получилось и симпатишней и производительней.
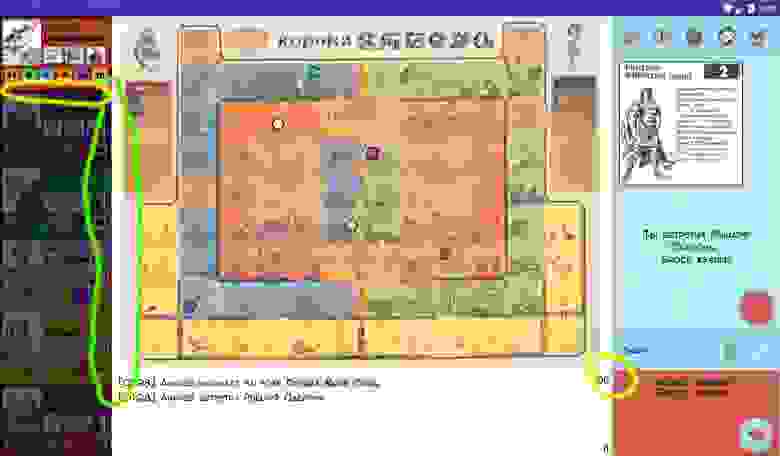
Однако до конца наши проблемы это не решило, и мы пошли дальше.
Шаг 3. Лишняя перерисовка (Overdraw)
Оказалось, что Андроид тщательно прорисовывает каждую картинку, каждый background у каждого View на экране. Здесь он, конечно, молодец. Но что делать, если одни изображения перекрывают другие, бэкграунды накладываются и часть этой прорисовки становится абсолютно ненужной? Правильно — отключать все, что не видно и не нужно.
Измерить наложение перерисовки оказывается очень просто: на своем устройстве в «Параметрах разработчика» нужно включить «Показывать превышение GPU», запустить приложение и посмотреть на экран.
Цвета View-элементов покажут, насколько у вас все хорошо (или плохо).
Свой цвет — уровень 0, «идеально»
Синий цвет — уровень 1, «нормально.
Зеленый цвет — уровень 2, „допустимо“.
Светло-красный цвет — уровень 3, „нежелательно“.
Красный цвет — уровень 4+, „не дай бог“.
Наша картинка вновь ввергла нас в ужас:

Нам пришлось снова пройтись по всей разметке и отключить background там, где он оказался лишним. Не забыли и про основной бэк приложения — одной простой строчкой:
В теме приложения выключили и его. И вот что получилось в итоге. Может и не везде идеально, но вполне допустимо. (Почти все View опустились на 3 уровня!)
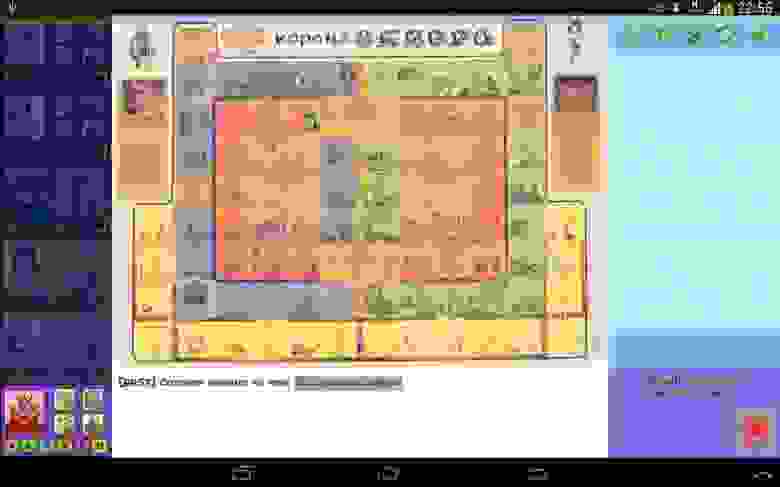
Шаг 4. Кэширование — ключ к успеху
Тоже вполне очевидная вещь, которая не казалась обязательной — это кэширование. В частности (в данном случае) кэширование шрифта.
Как вы уже наверное обратили внимание, везде, включая логи, используется свой шрифт и, о (опять) ужас!, каждый раз, для каждого нового текста он подгружается заново из Assets. Каждый раз, Карл! (черным цветом — основной потом, коричневым — работа Assesnager’а).

С кэшированием до этого никто из нас не сталкивался, но тут нас выручил один хороший человек со StackOverflow и подсказал простой код:
Применив который, лично я вообще практически забыл, что такое лаги.
Шаг 5. „А это — под укроп!“
Как в анекдоте, где мужику сказали, что он получит под надел столько земли, сколько сам сможет измерить и он скакал, бежал, шел, полз и в конце изможденный снял с себя шапку и кинул на сколько смог со словами: „А это — под укроп“, так и мы стремились максимально до мельчайших деталей оптимизировать производительность.
Поэтому пришло время оптимизации кода. Конечно, то как пишется код — это уже больше дело правильной привычки, и тут можно только дать несколько общих рекомендаций (более подробно их можно найти в любой статье по программной оптимизации). Вот с чем столкнулась наша команда:
— создавайте поменьше „ненужных“ циклов. Если что-то можно сделать без них — делайте без них;
— не создавайте переменных в цикле. Лучше создать их за его пределами, а в цикле просто обновлять;
— если есть необходимость обратиться к ресурсам неоднократно (с помощью gerResources() или же просто в другой класс/массив, например, myList.get (0)) — лучше запишите полученный результат в новую переменную и используйте ее: int myItem = myList.get(0); — это тоже подарит вашему приложению миллисекунды свободного времени;
— по возможности используйте статические методы (если нет необходимости обращаться к самому классу);
— ну и классический способ: на финальном этапе программирования убирайте инкапсуляцию (геттеры и сеттеры) и обращайтесь к переменной напрямую.
Подводя итог
Уверен, что сделанные шаги не являются окончательными и всегда будет „место под укроп“, до которого мы не добрались. Всегда готов узнать о шаге №6, 7… и даже №157, если вы захотите ими поделиться в комментариях. Более того, за „науку“ буду благодарен.
А пока, резюмируем, что же нужно сделать, чтобы ваше приложение начало „летать“:
1. Измерьте производительность своего приложения и найдите источник проблемы. Может у вас это будет не шрифт, а, например, утечка памяти (включаем Memory Monitor);
2. Оптимизируйте структуру и иерархию View (включаем HierarhyViewer и здравый смысл);
3. Убираем везде все ненужные бэки, включая background приложения (в этом случае учтите, что для корректного отображения вам все равно понадобится общий бэк);
4. Смотрим на часто используемые ресурсы/загрузки/картинки/шрифты и кэшируем их;
5. Делаем оптимизацию программного кода.
В итоге, после всех этих шагов, картинка трассинга приложения стала выглядеть вот так:
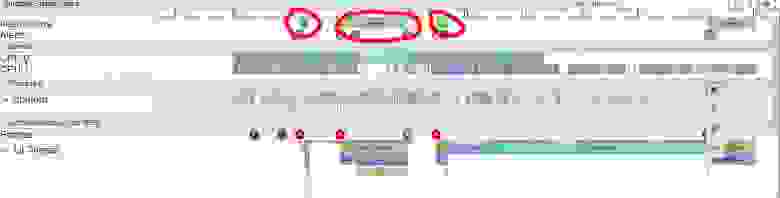
задержки практически исчезли (или стали незаметны), что нас вполне устроило.
Ну и конечно, первая мысль, которая пришла ко мне в голову после всей нашей оптимизации: „Вау! Теперь же можно добавить еще больше View и Layout на основной экран!“



