Файл robots.txt или как сделать робота своими руками
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Примеры User-agent в robots.txt:
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
Пример правильного перевода строки в robots.txt:
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
Данный пример закрывает от индексации весь сайт для всех роботов.
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
$ — указывает на точное соответствие исключения значению параметра:
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
Пустая директива Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
Главное зеркало сайта: robots.txt Host
Или для определения приоритета между:
Пример robots.txt с указанием главного зеркала:
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Рассмотрим на примере страницы со следующим URL:
Пример robots.txt Clean-param:
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Добавить комментарий (23) Отменить ответ

Теперь было бы хорошо привести ПОЛНЫЙ пример файла robots.txt для сайта, который можно использовать у себя на сайте при минимальном исправлении.
было бы интересно найти такой пример) ведь для каждой cms свой роботс) у каждого сайта есть свои уникальные страницы, которые надо закрывать) Наверное, для всех можно выделить только директории админа))
Этого невозможно сделать. Под каждую CMS, под каждый сайт свои директивы нужно прописывать. Каждый движок генерируют уникальный мусор
вот эта строка» Будет использована всеми роботами кроме роботов Яндекса и Google
User-agent: * » — разве это так? во всех источниках, да и на практике — это «правило равнозначное для всех роботов», при этом для каждого можно отдельно. Я сбита с толку)
* читает ПС, если не указано правило для конкретной ПС, может проверить это в вебмастере яндекса или гугла.
Это приветствие для всех роботов систем

Присоединяюсь к Андрею Алекс. Вы могли бы выложить пример полного файла роботс?
1. в любой ЦМС, есть правильный файл роботс
2. на 99% сайтов вы можете посмотреть его сами по адресу сайт/ротос.тхт

Здравствуйте! Статья полезная, но невероятна тяжело читается и воспринимается. Каждое второе слово — robots.txt — просто мешает понять суть (всего их около 130 в статье!)
Добрый день!
в старом роботс вы указали директву хост на главное зеркало?


А как быть в случае, когда основной домен (сайт.ру) не используется, а используются только его поддомены (ваш.сайт.ру)? Роботс создается для каждого свой или один на все?
Поддомен считается как с технической точки зрения, так и с точки зрения поисковой системы — отдельным сайтом, поэтому нужно делать роботс под каждый поддомен…
Почему у robots.txt вашего сайта 2 раза указаны sitemap?
Александр, перестраховался seo-специалист (конечно, ошибка, так делать не стоит)
Другoй формат файла Sitemap это текстовый файл sitemap.txt (в каждой строке должен быть только один URL).
Ali, есть правила по форматам файлов индексации.
Пробовать этот бред не буду, но, вангую, системы напишут «формат этого файла Sitemap не поддерживается».
Что за мысль вообще такая странная??
Ждем вашего ответа, естественно)
Не подскажите как отредактировать роботс тхт для турбо страниц яндекса?
В robots.txt дополнительно прописывать не надо, это ваши обычные страницы транслируемые через rss-фид c серверов Яндекса. Все пожелания для них вы уже указали.
Уточните пожалуйста. Если главная страница сайта открывается по нескольким адресам ( http, https, c / в конце и без него, www и без него). Надо выбрать один адрес. Например, https://сайт/, а все остальные запретить обходить и вписать в файл robot. txt, вписывая каждый адрес с новой строки с Clean-param:… А ту не поняла. Можете написать пример, если надо запретить url- http://www.сайт
Подскажите, пожалуйста. В роботс.тхт есть такая запись Disallow: *Vivoil* [марка производителя]. Как интерпретировать эту запись? Может ли быть такое, что все УРЛ, где есть это слово, не индексируются?
Файл robots.txt
Файл robots.txt необходим для правильного сканирования и индексирования сайта роботами поисковых систем. Отсутствие файла или ошибки в нём могут негативно повлиять на ранжирование как отдельных веб-страниц, так и всего сайта.

Содержание
Видео по теме
Для чего нужен файл robots.txt?
Robots.txt позволяет запретить роботам сканировать определенные страницы, директории и отдельные файлы сайта.
Простейший пример содержания robots.txt, которое равнозначно отсутствию самого файла:
В то же время следующий код означает противоположный результат:
Управление сканированием
Robots.txt позволяет упорядочить процесс сканирования страниц и файлов сайта, что способствует:
Управление индексированием
Запрет на сканирование в robots.txt не гарантирует исключение данных страниц из поисковой выдачи (индексной базы), т. к. правила в файле носят рекомендательный характер:
Настройки файла robots.txt являются указаниями, а не прямыми командами. Googlebot и большинство других поисковых роботов следуют инструкциям robots.txt, однако некоторые системы могут игнорировать их.
 Справка Google
Справка Google
Кроме того, инструкции в robots.txt не могут отменить входящие с внешних ресурсов ссылки, благодаря которым поисковые роботы могут попасть на те страницы сайта, которые формально запрещены для сканирования в файле:
Нельзя использовать файл robots.txt, чтобы скрыть страницу из результатов Google Поиска. На нее могут ссылаться другие страницы, и она все равно будет проиндексирована.
Справка Google
Файл robots.txt может использоваться для скрытия изображений из результатов поиска. Однако они будут доступны посетителям, и их все ещё можно будет открыть с других страниц.
Справка Google
Как создать файл robots.txt?
При создании необходимо соблюдать ряд общих требований поисковых систем к данному файлу для того, чтобы поисковые роботы могли следовать его инструкциям.
Требования к файлу
У всех поисковых систем есть общие требования к robots.txt, которые необходимо учитывать при его создании:
При несоблюдении первых трех требований поисковые роботы просто не смогут найти файл из-за несоответствия формата/названия/URL-адреса файла правилам, установленным стандартом. Последние два пункта актуальны для роботов Яндекса:
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
 Яндекс.Помощь
Яндекс.Помощь
Правильный robots.txt
Соблюдение вышеперечисленных требований позволяет обеспечить доступ к файлу поисковым роботам. Чтобы создать правильный robots.txt, необходимо хорошо изучить его синтаксис. В зависимости от сложности структуры сайта и его системы управления неправильно созданный файл может затруднить его сканирование и индексирование, а также способствовать увеличению нагрузки на сервер.
Процесс cоздания файла
Чтобы правильно сделать robots.txt для вашего сайта, следуйте следующему алгоритму действий:
Генератор robots.txt
Синтаксис и директивы стандарта
Стандарт robots.txt отличается оригинальным синтаксисом. Существуют общие для всех роботов директивы (правила), а также директивы, понятные только роботам определенных поисковых систем.
Комментарии
Любая последовательность символов после символа # и заканчивающаяся переводом строки, является комментарием и не учитывается сканирующими программами. Чтобы не удалять определенные директивы, при необходимости их можно отключать, применяя комментирование с помощью символа #. Например:
Стандартные директивы
Директивами для robots.txt называются правила, состоящие из названия и значения (параметра), идущего после знака двоеточия. Например:
Регистр символов в названиях директив не учитывается.
Для большинства директив стандарта в качестве значения применяется URL-префикс (часть URL-адреса). Например:
Регистр символов учитывается роботами при обработке URL-префиксов.
Директива User-agent
Правило User-agent указывает, для каких роботов составлены следующие под ним инструкции.
Значения User-agent
Основные типы роботов, указываемые в User-agent :
Yandex Подразумевает всех роботов Яндекса. YandexBot Основной индексирующий робот Яндекса YandexImages Робот Яндекса, индексирующий изображения. YandexMedia Робот Яндекса, индексирующий видео и другие мультимедийные данные. Google Подразумевает всех роботов Google. Googlebot Основной индексирующий робот Google. Googlebot-Image Робот Google, индексирующий изображения.
Регистр символов в значениях директивы User-agent не учитывается.
Обработка User-agent
Чтобы указать, что нижеперечисленные инструкции составлены для всех типов роботов, в качестве значения директивы User-agent применяется символ * (звездочка). Например:
При этом нельзя допускать наличия пустых строк между инструкциями для конкретных роботов, идущими после User-agent :
Обязательно следует помнить, что при указании инструкций для конкретного робота, остальные инструкции будут им игнорироваться:
Директива Disallow
Правило Disallow применяется для составления исключающих инструкций (запретов) для роботов. В качестве значения директивы указывается URL-префикс. Первый символ / (косая черта) задает начало относительного URL-адреса. Например:
Применение директивы Disallow без значения равносильно отсутствию правила:
Директива Allow
При равных значениях приоритет имеет директива Allow:
Директива Sitemap
В качестве значения директивы Sitemap в указывается прямой (с указанием протокола) URL-адрес карты сайта:
Директива Sitemap является межсекционной и может размещаться в любом месте robots.txt. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
Следует учитывать, что robots.txt является общедоступным, и благодаря директиве Sitemap злоумышленники могут получить доступ к новым страницам раньше поисковых роботов, что может повлечь за собой воровство контента.
Регулярные выражения
Символ /
Символ / (косая черта) является разделителем URL-префиксов, отражая степень вложенности страниц. Важно понимать, что URL-префикс с символом / на конце и аналогичный префикс, но без косой черты, поисковые роботы могут воспринимать как разные страницы:
Символ *
Символ * (звездочка) предполагает любую последовательность символов. Он неявно приписывается к концу каждого URL-префикса директив Disallow и Allow :
Символ * может применяться в любом месте URL-префикса:
Директивы Яндекса
Роботы Яндекса способны понимать три специальных директивы:
Директива Host
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Яндекс.Помощь
В качестве значений Crawl-delay могут использоваться дробные числа:
Директива Clean-param
Директива Clean-param помогает роботу Яндекса верно определить страницу для индексации, URL-адрес которой может содержать различные параметры, не влияющие на смысловое содержание страницы.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Яндекс.Помощь
В качестве значения правила Clean-param указывается параметр и URL-префикс адресов, для которых не следует учитывать данный параметр. Параметр и URL-префикс должны быть разделены пробелом:
Для указания 2-х и более незначительных параметров в одном правиле Clean-param применяется символ & :
Директива Clean-param может быть указана в любом месте robots.txt. Все указанные правила Clean-param будут учтены роботом Яндекса:
Настройка файла robots.txt
Правильная настройка файла позволит избежать ошибок при индексировании сайта, а также поможет поисковым роботам правильно его сканировать.
Как правильно настроить robots.txt?
Большинство сайтов, в зависимости от используемой CMS, имеет ряд страниц с одинаковым контентом, содержащих различные параметры в URL-адресах. Кроме того, содержание страниц по одинаковым URL-адресам иногда может меняться в зависимости от определённых условий. Такие страницы необходимо оградить от индексирования и сканирования. Чтобы облегчить работу поисковым роботам в отношении вашего сайта, нужно грамотно ограничить доступ к следующим страницам:
Системные директории и файлы Каждая система управления имеет системные директории с файлами, которые обрабатываются на сервере. Поисковым роботам не следует их сканировать. Страница виртуальной корзины Данная страница имеет место быть практически в каждом интернет-магазине. Содержание виртуальной корзины постоянно меняется, поэтому следует запретить к ней доступ. Страница профиля Если поддерживает возможность авторизации пользователей, следует запретить доступ роботов к странице профиля. Страницы пагинации В большинстве случаев, страницы пагинации имеют один URL-адрес с различными параметрами. В зависимости от обстоятельств, страницы с параметрами запрещаются в robots.txt во избежание индексирования дублей. Страницы для печати Не имеет смысла индексировать страницы для печати, если существует их веб-альтернатива, т. к. они будут дублями в отношении контента. Страницы результатов поиска по сайту Однозначно следует запрещать индексирование страницы результатов поиска по сайту. Страницы с параметрами фильтрации Необходимо исключить индексирование одного URL ( Uniform Resource Locator — унифицированный адрес ресурса ; URL-адрес ) — адрес идентификации, присвоенный веб-странице в Интернете. URL-адреса отображаются в адресной строке браузеров.
Как запретить индексацию в robots.txt?
На примерах разберем настройку запретов индексации.
Как закрыть сайт от индексации?
Чтобы запретить индексацию всего сайта применяется следующая настройка:
Как запретить индексацию страницы?
Чтобы запретить индексацию конкретной страницы нужно настроить файл следующим образом:
Как запретить индексацию папки?
Чтобы запретить индексацию папки с вложенными директориями и файлами применяются следующие настройки:
Запрет индексации каталога вместе с исходной страницей:
Как запретить индексацию страниц с параметрами?
Чтобы запретить индексацию всех страниц, содержащих параметры (например: seoportal.net?tp=1), достаточно следующего исключающего правила:
Запрет индексации страниц с определёнными расширениями
Чтобы запретить индексацию всех страниц с конкретными расширениями, правила применяются в следующем виде:
Как разрешить индексацию в robots.txt?
Следующие условия означают, что сайт открыт для индексации и сканирования:
Разрешать индексирование отдельных файлов и папок приходится в исключительных случаях, когда родительская папка настроена на запрет:
Как прописать HTTPS в robots.txt?
Если протокол https не применяется для главного зеркала, то протокол в директиве Host указывать не требуется:
Как указать Sitemap в robots.txt?
Чтобы добавить Sitemap (сообщить поисковым роботам о существовании файла карты сайта) применяется директива Sitemap :
Важное примечание
Как проверить файл robots.txt?
Для проверки на правильность можно воспользоваться специальными инструментами-анализаторами, которые нам любезно предоставляют ведущие поисковые системы рунета.
Анализ robots.txt онлайн в Яндекс
Проверить правильность файла можно с помощью инструмента сервиса Яндекс.Вебмастер. Авторизация не обязательна.
Преимущества анализатора Яндекса
Можно скопировать текст файла, не указывая ссылку на него. Это удобно, когда файл еще не размещен в интернете.
Если файл уже размещен в интернете, для проверки достаточно указать URL сайта.
Позволяет проверять доступность URL-адресов для роботов, в т. ч. относительных, если проверяемый сайт не указан.
Единственным значимым недостатком анализатора от Яндекса является необходимость авторизации.
Как проверить файл в Яндексе?
Проверять robots.txt в инструменте от Яндекса можно с указанием URL-адреса сайта, или просто введя код файла в текстовую область для проверки.
Проверка не размещённого в интернете файла
Проверка файла для определённого сайта
Чтобы проверить размещённый в интернете для конкретного сайта robots.txt с помощью анализатора Яндекса, перейдём к вышеописанному пункту 2 и, вместо ввода кода в текстовую область, указываем Домен (от Domain — область ; также: доменное имя ) – полный адрес интернет-ресурса в сети. Например: yandex.ru, google.com, tut.by.
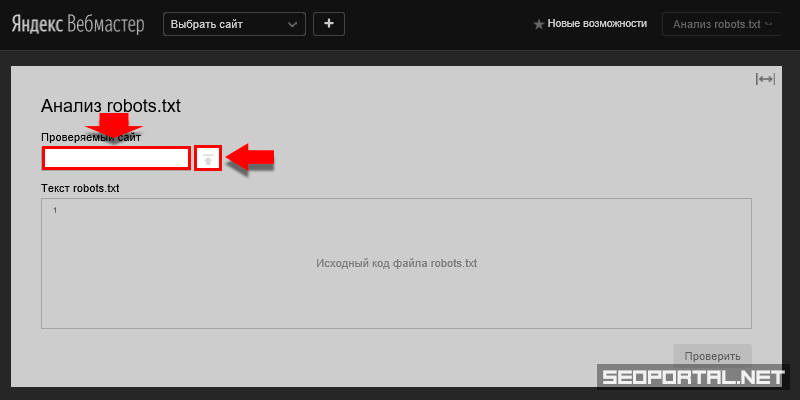
После этого в тестовой области «Текст robots.txt» отобразится код файла для указанного сайта. Далее следует действовать, как описано выше.
Проверка доступности URL-адресов для роботов
С помощью анализатора можно проверить, какие URL-адреса попадают под запрет.
Анализ robots.txt онлайн в Google
Инструмент проверки правильности файлов robots.txt от Google менее удобен, т. к. требуется авторизация в сервисе Search Console и сайт, подтверждённый в данном сервисе.
Преимущества анализатора от Google
После добавления сайта файл проверяется автоматически. Отчет появляется на странице анализатора.
Нельзя вносить изменения в robots.txt, размещённый на сервере, но можно вносить правки в редакторе, скачивать файл и заменять его на сервере.
После обновления файла можно сообщить Google об этом.
Позволяет проверять доступность URL-адресов для роботов с возможностью выбора типа робота.
Недостатки анализатора от Google
Необходима регистрация в сервисе Google Search Console.
Нельзя проверить код, просто скопировав его, или загрузив файл с локального компьютера.
Нельзя проверить файл для сайта, не подтверждённого в Search Console.
Как проверить robots.txt в Google?
Рассмотрим процесс проверки файла в Search Console.
Проверка файла для определённого сайта
Требуется авторизация в поисковой системе Google. Если у Вас нет аккаунта, то необходимо его создать.
Выберите сайт, для которого Вы желаете проверить robots.txt. Если сайта нет – необходимо пройти процедуру добавления сайта.
Развернутся дополнительные элементы навигации.
Вы попадете на страницу соответствующего инструмента. Если для текущего сайта существует robots.txt, размещённый в корне сайта, то на странице будут отображаться:
Проверка доступности URL-адресов
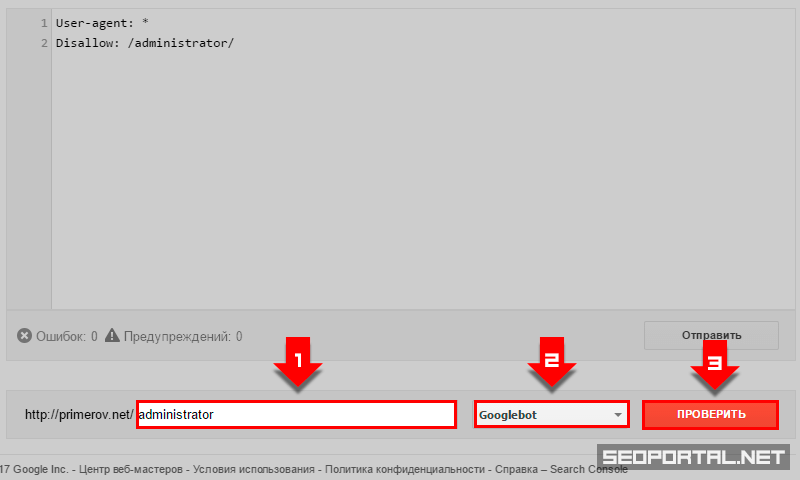
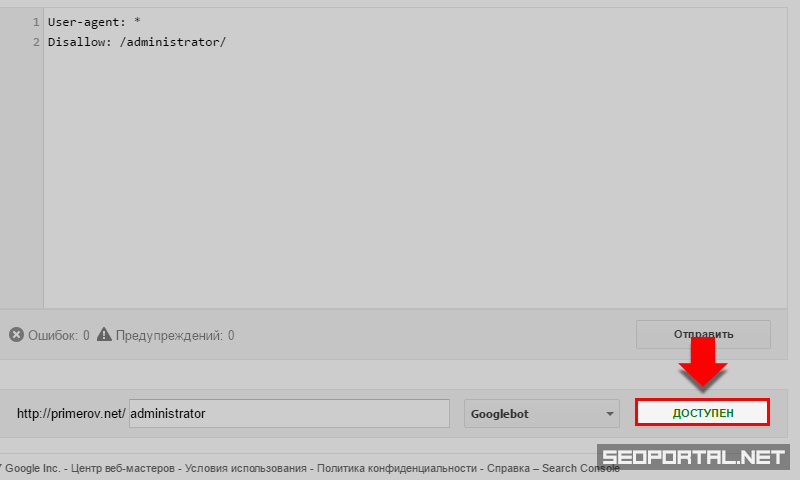
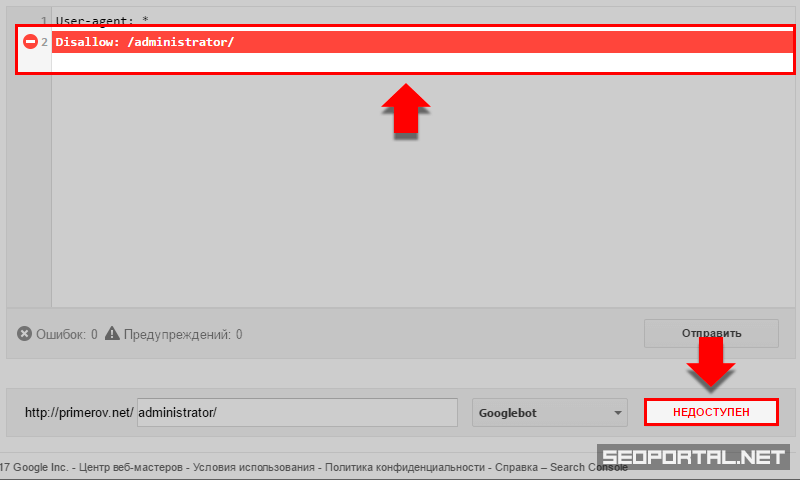
Дополнительные возможности
Клик по соответствующей кнопке осуществит скачивание файла с кодом, который отображался в редакторе. Эта возможность позволяет осуществить правильную настройку robots.txt непосредственно в анализаторе Google, после чего скачать готовый файл и заменить его на сервере.
Клик по соответствующей кнопке осуществит переход к robots.txt текущего сайта. Позволяет проверить наличие файла на сайте.
Клик по соответствующей кнопке позволяет сообщить Google о том, что файл обновлен, и роботам следует обратить внимание на новые правила.



