CPU utilization
Смотреть что такое «CPU utilization» в других словарях:
CPU bound — In computer science, CPU bound (or compute bound) is when the time for a computer to complete a task is determined principally by the speed of the central processor: processor utilization is high, perhaps at 100% usage for many seconds or minutes … Wikipedia
CPU cache — Cache memory redirects here. For the general use, see cache. A CPU cache is a cache used by the central processing unit of a computer to reduce the average time to access memory. The cache is a smaller, faster memory which stores copies of the… … Wikipedia
Avaya Unified Communications Management — Developer(s) Nortel (now Avaya) Operating system MS Windows, and Linux Type Unified Communications Configuration and Management Avaya Unified Communications Management in computer networking is the name of a collection o … Wikipedia
Ganglia — Страница статистики серверов … Википедия
Tagged Command Queuing — (TCQ) is a technology built into certain ATA and SCSI hard drives. It allows the operating system to send multiple read and write requests to a hard drive. ATA TCQ is not identical in function to the more efficient Native Command Queuing (NCQ)… … Wikipedia
Rate-monotonic scheduling — In computer science, rate monotonic scheduling [citation|first1=C. L.|last1=Liu|authorlink1=Chung Laung Liu|first2=J.|last2=Layland|title=Scheduling algorithms for multiprogramming in a hard real time environment|journal=Journal of the ACM|volume … Wikipedia
Norton AntiVirus — Developer(s) Symantec Corporation Stable release … Wikipedia
Direct memory access — (DMA) is a feature of modern computers that allows certain hardware subsystems within the computer to access system memory independently of the central processing unit (CPU). Without DMA, the CPU using programmed input/output is typically fully… … Wikipedia
Peer-to-Peer Protocol (P2PP) — Application layer protocol that can be used to form and maintain an overlay among participant nodes. Provides mechanisms for nodes to join, leave, publish, or search for a resource object in the overlay. Maintaining information about nodes in… … Wikipedia
% CPU Utilization
| Официальное название | CPU Utilization Counter |
| Тип счётчика | Интервальный (% занятости) |
| Описание | Усреднённая утилизация процессора за интервал времени. На каждом отрезке, на котором не выполняется Idle Thread, процессор считается занятым какой-то реальной нагрузкой. Этот счётчик – сумма показателей утилизации ЦПУ пользователем, системой и во время простоя (Idle + User + System utilization, названия могут отличаться на разных платформах) |
Расследование стоит начинать со счётчика Утилизации ЦПУ пользовательского режима, чтобы определить, на что расходуется ресурс ЦПУ: на процессы пользователя или ядра
Примечание: Высокий процент утилизации процессоров на машине не всегда означает наличие проблемы, которую нужно решать. Однако стоит разобраться в причинах, если время простоя ЦПУ ниже 20%, а его падение ниже 10% может свидетельствовать об ошибке.
Метрика загруженности процессора (CPU utiliztion) — это не то что вы думаете

Всем привет. Предлагаю вашему вниманию свой перевод поста «CPU Utilization is Wrong» из блога Брендана Грегга.
Как вы думаете, что значит нагрузка на процессор 90% на картинке ниже?
Вот что это значит на самом деле:
Stalled, то есть «приостановлено» значит, что в данный момент процессор не обрабатывает инструкции, обычно это означает, что он ожидает завершения операций ввода/вывода связанных с памятью (здесь и далее речь о RAM, а не дисковом вводе/выводе). Соотношение между «занято» и «приостановлено» (busy/stalled), которое я привел выше, это то что я обычно вижу в продакшене. Вероятно, что ваш процессор тоже большую часть времени находится в stalled состоянии, но вы об этом и не догадываетесь.
Что это значит для вас? Понимание того насколько много ваш процессор находится в приостановленном состоянии может помочь вам понять куда направить усилия по оптимизации производительности приложения: на ускорение кода или уменьшение числа операций ввода/вывода связанных с памятью. Всем кто заинтересован в оптимизации нагрузки на процессор, в особенности в облаках с настроенным автомасштабированием на основе нагрузки на CPU, будет полезно знать насколько долго процессор находится в приостановленном состоянии.
Что такое нагрузка на процессор на самом деле?
Метрика, которую мы называем нагрузкой на процессор (CPU utilization) на самом деле это «не-idle время», то есть время, которое процессор не выполняет idle-тред. Ядро вашей операционной системы (какую бы ОС вы не использовали) обычно следит за этим во время переключения контекста. Если не-idle тред запустился, а затем спустя 100 милисекунд остановился, то ядро посчитает, что процессор был использован в течение всего этого времени.
Эта метрика так же стара как и системы совместного использования времени (time sharing systems). В бортовом компьютере лунного модуля Apollo (это пионер среди систем совместного использования времени) idle-тред назывался «DUMMY JOB» и инженеры мониторили циклы выполняющие его в сравнении с реальными задачами, это было важной метрикой измерения нагрузки. (Я писал об этом ранее).
Что же с этой метрикой не так?
Со временем все становится только хуже. Долгое время производители процессоров увеличивали тактовые частоты своих процессоров быстрее чем производители памяти уменьшали задержки доступа к памяти (CPU DRAM gap). Примерно в 2005 году процессоры достигли частот в 3 GHz и с тех пор мощность процессоров растет не за счет увеличения тактовой частоты, а за счет большего числа ядер, гипертрединга и многопроцессорных конфигураций. Все это предъявляет еще больше требований к памяти. Производители процессоров пытались снизить задержки связанные с памятью за счет больших по размеру и более умных CPU-кешей, более быстрых шин и соединений. Но проблема со stalled-состоянием все еще не решена.
Как понять, что процессор на самом деле делает
Сделать это можно используя Performance Monitoring Counters (PMC-счетчики): хардверные счетчики, которые могут быть прочитаны с помощью Linux pref (пакет linux-tools-generic в Линуксе) и других утилит. Для примера понаблюдаем за всей системой в течение 10 секунд:
Ключевая метрика здесь instructions per cycle (insns per cycle: IPC, число инструкций за один цикл), которая показывает сколько в среднем инструкций было выполнено за каждый такт. Чем больше, тем лучше. В примере выше значение 0.78 кажется очень неплохим (нагрузка 78%?) до тех пор пока вы не узнаете, что максимальная скорость процессора это IPC 4.0. Такие процессоры называют 4-wide, это название пошло от особенностей пути извлечения/декодирования инструкций в процессоре (подробнее об этом в Википедии).
Существуют сотни PMC-счетчиков, которые позволяют детальнее разобраться с производительностью системы, например, посчитать число приостановленных циклов по типам.
В облаках
Если вы работаете в виртуальном окружении, то вероятно у вас нет доступа к PMC-счетчикам, это зависит от поддержки этой фичи гипервизором. Я недавно писал о том, что PMC-счетчики теперь доступны в AWS EC2 в виртуальных машинах базирующихся на Xen.
Как интерпретировать и что делать
Если ваш IPC 1.0, то вероятно, вы ограничены числом инструкций, которые может выполнять процессор. Попробуйте найти способ уменьшить число выполняемых инструкций: уменьшить число ненужной работы, кешировать операции и т.п. CPU flame графы — отличная утилита для этих целей. С точки зрения тюнинга железа, попробуйте использовать процессор с большей тактовой частотой и большим числом ядер и гипертредов.
Для моих правил выше я выбрал значение IPC 1.0, почему именно его? Я пришел к нему из своего опыта работы с PMC-счетчиками. Вы можете выбрать для себя другое значение. Сделайте два тестовых приложения, одно упирающееся по производительности в процессор, другое — в память. Посчитайте IPC для них и возьмите среднее значение.
Что инструменты мониторинга производительности должны сообщать вам?
Другие причины почему CPU utilization вводит в заблуждение
Проблема со stalled-циклами может быть не только в задержках связанных с памятью:
— изменение температуры может влиять на приостановленность процессора,
— турбобуст может менять тактовую частоту процессора,
— ядро варьирует частоту процессора с определенным шагом,
— проблема с усреднением: 80% нагрузки в течение минуты скроет кратковременный всплеск до 100%,
— спинлоки: процессор нагружен, имеет высокий IPC, но приложение ничего не делает.
Заключение
Нагрузка на процессор (CPU utilization) это обычно неправильно интерпретируемая метрика, так как она включает циклы, потраченные на ожидание ответа от основной памяти, которые могут доминировать в современных нагрузках. Вы можете понять что на самом деле стоит за %CPU используя дополнительные метрики, включая число инструкций за цикл (IPC). Если IPC 1.0, то в скорость процессора. Я писал про IPC в своем предыдущем посте, в том числе написал и о использовании PMC-счетчиках, необходимых для измерения IPC.
Инструменты мониторинга производительности, которые показывают %CPU должны показывать PMC-счетчики, чтобы не вводить пользователей в заблуждение. Например, они могут показывать %CPU с IPC и/или число instruction-retired и stalled циклов. Вооруженные этими метриками разработчики и админы могут решить как правильнее тюнинговать их приложения и системы.
Анализ ключевых показателей производительности — часть 3, последняя, про системные и сервисные метрики
Мы заканчиваем публикацию перевода по тестированию и анализу производительности от команды Patterns&Practices о том, с чем нужно есть ключевые показатели производительности. За перевод спасибо Игорю Щегловитову из Лаборатории Касперского. Остальные наши статьи по теме тестирования можно найти по тегу mstesting
В первой статье цикла по анализу ключевых показателей производительности мы наладили контекст, теперь переходим к конкретным вещам. Во второй посмотрели на анализ пользовательских, бизнесовых показателей/метрик и показателей, необходимых к анализу внутри приложения. В этой, заключительной — про системные и сервисные (в т.ч. зависимых сервисов) метрики.
Итак,
Системные метрики.
Системные метрики позволяют определять, какие системные ресурсы используются и где могут возникать конфликты ресурсов. Эти метрики направлена на отслеживание ресурсов уровня машины, таких как память, сеть, процессор и утилизация диска. Эти метрики могут дать представление о внутренних конфликтах лежащих в основе компьютера.
Вы также можете отслеживать данные метрики для определения аспектов производительности – нужно понимать, если ли зависимость между системными показателями и нагрузкой на приложение. Возможно, вам потребуются дополнительные аппаратные ресурсы (виртуальные или реальные). Если при постоянной нагрузке происходит увеличение значений данных метрик, то это может быть обусловлено внешними факторами — фоновыми задачами, регулярно-выполняющимися заданиями, сетевой активностью или I/O устройства.
Как собирать
Вы можете использовать Azure Diagnostics для сбора данных диагностики для для отладки и устранения неполадок, измерения производительности, мониторинга использования ресурсов, анализа трафика, планирования необходимых ресурсов и аудита. После сбора диагностики ее можно перенести в Microsoft Azure Storage для дальнейшей обработки.
Другой способ для сбора и анализа диагностических данных — это использование PerfView. Этот инструмент позволяет исследовать следующие аспекты:
Изначально PerfView был предназначен для локального запуска, но теперь он может быть использован для сбора данных из Web и Worker ролей облачных сервисов Azure. Вы можете использовать NuGet-пакет AzureRemotePerfView для установки и запуска PerfView удаленно на серверах ролей, после чего скачать и проанализировать полученные данные локально.
Windows Azure Diagnostics и PerfView полезны для анализа используемых ресурсов “постфактум”. Однако, при применении таких практик как DevOps, необходимо мониторить “живые” данные производительности для обнаружения возможных проблем производительности еще до того, как они произойдут. APM-инструменты могут предоставлять такую информацию. Например, утилиты Troubleshooting tools для веб-приложений на портале Azure могут отображать различные графики, показывающие память, процессор и утилизацию сети.

На портале Azure есть “health dashboard”, показывающий общие системные метрики.
Аналогичным образом, панель Diagnostic позволяет отслеживать заранее настроенный набор наиболее часто используемых счетчиков производительности. Здесь вы можете определить специальные правила, при выполнении которых оператор будет получать специальные нотификации, например, когда значение счетчика сильно превысит определенное значение.
Веб-портал Azure может отображать данные о производительности в течении 7 дней. Если вам нужен доступ данных за более длительный период, то данные о производительности нужно выгружать напрямую в Azure Storage.
Websites Process Explorer позволяет вам просматривать детали отдельных процессов запущенных на веб-сайте, а также отслеживать корреляции между использованием различных системных ресурсов.
New Relic и многие другие APM имеют схожие функции. Ниже приведено несколько примеров.
Мониторинг системных ресурсов делится на категории, которые охватывают утилизацию памяти (физической и управляемой), пропускную способность сети, работу процессора и операции дискового ввода вывода (I/O). В следующих разделах описано, на что следует обратить внимание.
Использование физической памяти
Существует две основные причины ошибки OutOfMemory – процесс превышает выделенное для него пространство виртуальной памяти либо операционная система оказывается неспособной выделить дополнительную физическую память для процесса. Второй случай является самым распространенным.
Вы можете использовать описанные ниже счетчики производительности для оценки нагрузки на память:
Также следует учитывать, что большие объемы памяти могут привести к фрагментации (когда свободной физической памяти в соседних блоках недостаточно), поэтому система, которая показывает, что имеет достаточно свободной памяти, может оказаться не в состоянии выделить эту память для конкретного процесса.
Многие APM-инструменты предоставляют сведения об использовании процессами системной памяти без необходимости глубокого понимания о принципах работы памяти. На графике ниже показана пропускная способность (левая ось) и время отклика (правая ось) для приложения, находящегося под постоянной нагрузкой. Примерно после 6 минут производительность внезапно падает, и время отклика начинает “прыгать”, по прошествии нескольких минут происходит показателей.
Результаты нагрузочного тестирования приложения
Записанная с помощью New Relic телеметрия показывает избыточное выделение памяти, которое вызывает сбой операций с последующим восстановлением. Использованная память растет за счет файла подкачки. Такое поведение является классическим симптомом утечки памяти.
Телеметрия, показывающая избыточное выделение памяти
Примечание: В статье Investigating Memory Leaks in Azure Web Sites with Visual Studio 2013 содержится инструкция, показывающая как использовать Visual Studio и Azure Diagnostics для мониторинга использования памяти в веб-приложении в Azure.
Использование управляемой памяти
.NET приложения используют управляемую память, которая контролируется CLR (Common Language Runtime). Среда CLR проецирует управляемую память на физическую. Приложения запрашивают у CLR управляемую память, и CLR отвечает за выделение требуемой и освобождение неиспользуемой памяти. Перемещая структуры данных по блокам, CLR обеспечивает компоновку этого типа памяти, уменьшая тем самым фрагментацию.
Управляемые приложения имеют дополнительный набор счетчиков производительности. В статье Investigating Memory Issues содержится детальное описание ключевых счетчиков. Ниже описаны наиболее важные счетчики производительности:
Управление производительностью вычислительных систем на примере RISC-серверов Sun
Производительность — главный показатель работоспособности системы. Не обладая необходимой производительностью, она не способна выполнять возложенные на нее задачи. И примеров тому можно привести массу: невозможность своевременно отреагировать на изменение конъюнктуры рынка из-за задержки аналитической обработки данных (OLAP), отказ в обслуживании клиента из-за перегрузки системы (процессинг), срыв сроков поставок (ERP) или подачи отчетов в фискальные органы и т. д. В результате сроки выполнения бизнес-задач могут оказаться сорванными, что в конечном итоге приведет к финансовым потерям компании.
На снижение производительности влияют многие факторы: от выхода из строя компонентов вычислительных средств до ошибки в проектировании. Однако, даже если система хорошо спроектирована, ее производительность может перестать удовлетворять требованиям бизнеса в случае их изменения: например, когда происходит незапланированный рост числа пользователей или объемов данных, появляются новые задачи и т. п.
Чтобы падение производительности не стало неприятным сюрпризом, ее уровень надо постоянно отслеживать и корректировать. Сделать это помогает методика управления уровнем сервиса (Service Level Management, SLM), следование которой позволяет держать в заданных рамках все показатели — не только производительности, но и готовности информационных сервисов ИС.
 |
| Рисунок 1. Процесс управления уровнем обслуживания. |
В соответствии с данной методикой (см. Рисунок 1), необходимо определить, какие показатели производительности должна иметь вычислительная система, как их измерять и каким образом полученные данные отражают реальную картину. Для решения проблемы снижения производительности необходимо предпринять адекватные меры по ее устранению. Приобретение более мощного оборудования не является панацеей от всех бед. Во многих случаях помогает оптимизация системы, но рецептов на все случаи жизни не существует.
Вопросы выбора показателей производительности системы, их измерения и анализа полученных данных рассматриваются далее на примере платформы SPARC/Solaris. В заключение статьи приводится ряд рекомендаций по оптимизации ОС Solaris для повышения производительности при работе с СУБД Oracle.
КАКИХ ЦЕЛЕЙ ХОЧЕТСЯ ДОСТИЧЬ
С момента появления вычислительной техники пользователи хотят, чтобы компьютеры работали быстрее. Но всегда ли нужно идти у них на поводу? Если сервер способен обработать 10 тыс. транзакций в секунду, много это или мало? На первый взгляд для банка, у которого всего 10 тыс. клиентов, такая производительность более чем достаточна, а для оператора мобильной связи с тем же числом абонентов вроде бы маловата. Однако если в банке одновременно с интерактивным обслуживанием клиентов сотня экспертов выполняет сложные аналитические задачи с использованием тех же финансовых транзакций, то сервер автоматизированной банковской системы (АБС) может не успеть выполнить запрос на обслуживание важного клиента, что грозит потерей денег — клиент предъявит иск или просто откажется от услуг банка. Напротив, если сервер биллинговой системы оператора мобильной связи не успеет обработать детальную запись о звонке абонента (Call Detailed Record, CDR), то он имеет возможность сделать это в следующую итерацию, поскольку коммутаторы сети мобильной связи обычно хранят CDR некоторое время.
Итак, 10 тыс. транзакций в секунду — это много или мало? Ответ зависит от того, выполнение каких задач возложено на сервер и какие требования при этом предъявляются. Например, в случае АБС банка сервер должен выполнить запрос клиента на осуществление финансовой транзакции не более чем за 30 с, а для биллинговой системы оператора мобильной связи требование может выглядеть иначе — сервер должен суметь обработать за 1 мин не менее 5000 CDR.
Если требования изначально не определены, то измерение производительности системы становится бессмысленным занятием. Требования обычно фиксируются в соглашении об уровне обслуживания (Service Level Agreement, SLA). SLA — это полноценный контракт между провайдером услуг и потребителем, который в наших примерах может быть заключен между службой ИТ банка и руководством банка, отделом эксплуатации биллинговой системы и службой биллинга. Он необходим для оценки уровня услуг ИТ и обеспечения управления этим уровнем. Как правило, SLA оговаривает такие параметры, как коэффициент готовности услуги (доступность), нормативы устранения сбоев, а также показатели производительности (Key Performance Indicator, KPI).
Зафиксированные в SLA требования (Service Level Objective, SLO) говорят о том, какую производительность системы необходимо поддерживать, а KPI позволяют установить, что производительность системы находится на должном уровне. (SLO для АБС банка и биллинговой системы уже были сформулированы выше.) Кроме того, в SLO указывают, как учитывается время обработки: в частности, для финансовых транзакций — это может быть интервал времени между отправкой запроса на выполнение транзакции и получением визуального подтверждения его выполнения. Для АБС банка KPI могут быть сформулированы как доля транзакций, время обработки которых превышает определенный порог, например 28 с. Если количество подобных финансовых транзакций вышло за заданный порог, например 5%, то можно говорить о падении производительности системы и следует принять меры к ликвидации данной ситуации. Для биллинговой системы KPI формулируются проще — как минимальное число CDR, обрабатываемых за 1 мин.
ЧТО ИЗМЕРЯТЬ?
К сожалению, использование KPI позволяет только фиксировать факт снижения производительности, но не раскрывает причины происходящего. На практике производительность грамотно спроектированной системы не должна падать при отсутствии каких-либо существенных изменений во внешних условиях функционирования, отказов оборудования или неумелого вмешательства администраторов в ее работу. Как правило, системы проектируются с запасом производительности и масштабируемости на случай увеличения нагрузок вследствие прироста объемов обрабатываемых данных и числа пользователей. Незапланированное резкое увеличение числа пользователей (в частности, в результате создания нового подразделения) или появление новых задач является существенным изменением внешних условий функционирования. Поэтому, если система стала медленнее работать, прежде всего надо выяснить, какие случились перемены. Как уже было отмечено, обычно KPI не позволяют определить, что могло повлиять на нормальную работу системы.
Кроме того, измерение параметров KPI не всегда возможно или удобно осуществлять в том виде, в каком они заданы в SLA. Обычно значение KPI зависит от производительности множества компонентов системы: сети, прикладного программного обеспечения и сервера. У каждого из данных компонентов существуют индикаторы производительности. Для сервера такими индикаторами служат загруженность процессорных мощностей, используемый объем оперативной памяти, число выполняемых процессов и др. KPI являются интегральным показателем, и зачастую формулу их расчета невозможно вывести из индикаторов производительности отдельных компонентов системы, особенно если последняя состоит из большого числа серверов, сетевых коммутаторов, дисковых массивов, коммутаторов Fibre Channel и т. д. В таком случае измеряют показатели производительности компонентов работающей системы, когда она обеспечивает требуемую производительность. Полученные значения используют как базовые (baseline) для сравнения с текущими показателями производительности компонентов при дальнейших контрольных замерах. Если конфигурация системы изменяется или претерпевает модернизацию, то определение базовых значений производится вновь.
Вместе с тем, открытым остается вопрос: какие показатели производительности отнести к базовым? Все измеряемые показатели попадают в одну из четырех категорий: производительность, время отклика/обслуживания, длина очереди и утилизация.
Производительность (throughput) — это объем работы, который может быть выполнен за указанный промежуток времени. Число транзакций в секунду, осуществляемых системой управления базами данных (СУБД), является одним из примеров единицы измерения производительности. Максимальная производительность — объем выполненной работы за указанный промежуток времени при 100-процентной загруженности ресурсов системы. Иногда производительность путают с пропускной способностью. Пропускная способность (bandwidth) — это максимальная теоретически достижимая скорость без учета накладных расходов (overhead). Например, у шины Fast Wide SCSI пропускная способность составляет 20 Мбайт/с, а максимальная производительность — 16 Мбайт/с вследствие накладных расходов на протокол SCSI.
Время отклика (response time) — время, которое необходимо для завершения той или иной работы, например выполнения транзакции СУБД. Латентность является синонимом, но обычно используется как характеристика протоколов.
Время обслуживания (service time) — время, затрачиваемое на выполнение запроса, оно отсчитывается с момента достижения запросом начала очереди. Если система свободна и, следовательно, длина очереди запросов равна нулю, то время отклика равно времени обслуживания.
Длина очереди (queue length) — число запросов, ожидающих обслуживания. Длинные очереди увеличивают время отклика, но не влияют на время обслуживания.
Утилизация (utilization) — процент ресурсов системы, необходимых для выполнения работы, например процент времени использования процессора от общего времени работы системы.
Приведенные показатели связаны следующими формулами:
service time = utilization/throughput
queue length = throughput * response time
Так какие же параметры системы необходимо измерять? Ответ вполне очевиден: те, которые в дальнейшем помогут выявить приводящие к потере производительности «узкие» места. Как уже говорилось ранее, в любой системе имеются три компонента, где могут возникать «узкие» места, — это сеть, прикладное ПО и сервер. Для каждого из них существует свой набор показателей, на основании которых оказывается возможным выявить проблемы с производительностью. Еще раз подчеркнем, что все эти показатели попадают в одну из четырех упомянутых ранее категорий: производительность, время отклика/обслуживания, длина очереди и утилизация.
Процесс анализа показателей производительности рассмотрим на примере платформы SPARC/Solaris. В ядре операционной системы в специальных счетчиках накапливается статистика о работе компонентов системы. Для отображения статистики функционирования различных компонентов сервера и операционной системы платформы SPARC/Solaris используются следующие команды:
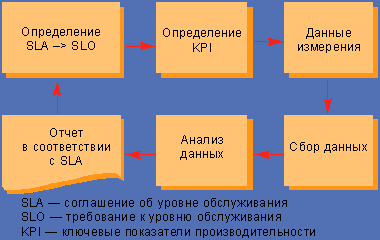
/usr/bin/vmstat — статистика об использовании виртуальной памяти, обмене страниц физической памяти с диском (paging) и обобщенные показатели загрузки процессоров; /usr/bin/mpstat — детальная статистика о загрузке процессоров; /usr/bin/iostat — статистика о подсистеме дискового ввода/вывода и NFS; /usr/bin/netstat — статистика о работе сетевых интерфейсов.
В других системах UNIX, берущих свое начало от AT&T System V, для отображения статистики служат аналогичные команды. Так, в HP-UX 11i v1 — это vmstat, mpstat, iostat, netstat, причем они отображают практически ту же информацию, что и команды ОС Solaris. Однако методика анализа их результатов для ОС Solaris и для HP-UX различна в связи с отличиями во внутренних структурах указанных ОС.
Поиск «узких» мест, влияющих на производительность сервера, рекомендуется начинать с анализа статистики использования памяти. Зачастую недостаток памяти ошибочно диагностируется как медленный доступ к диску или нехватка процессорной мощности. Для получения статистики применяйте команду vmstat (см. Листинг 1). В первую очередь следует обратить внимание на значения в колонке sr (scan rate). Они показывают число страниц памяти, которые ядро операционной системы просматривало в попытке найти свободную страницу. Когда указанная величина в колонке sr возрастает, одновременно увеличивается значение в колонке po (page-outs), показывающее число страниц физической памяти, выгружаемых на диск в область swap. Если такая ситуация наблюдается постоянно, то серверу не хватает памяти для выполнения задач, и из-за этого падает производительность.
 |
| Листинг 1 |
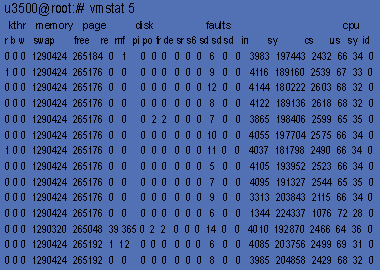
При поиске «узких» мест нужно обратить внимание и на статистику загрузки процессоров. Детальную информацию можно получить с помощью команды mpstat (см. Листинг 2). Важными для анализа являются следующие показатели:
Если значения в колонке idl постоянно близки к нулю, значит, серверу не хватает процессорной мощности для выполнения задач. Обратное не всегда верно. Время, которое процессор тратит на обработку прерываний сетевого ввода/вывода (и ряда других), учитывается как idl, поскольку приоритет таких прерываний выше, чем приоритет прерываний таймера сбора статистики. В результате якобы бездействующий сервер (высокие значения idl) в действительности может быть занят обработкой сетевого трафика. Помимо описанной возможен и ряд других подобных ситуаций, когда необходимо учитывать значения приведенных показателей в комплексе, что отражено в Таблице 1. На Листинге 2 видно, что сложная вычислительная задача (idl=0) не мешает серверу справляться с нагрузкой — все остальные параметры в норме.
 |
| Листинг 3 |
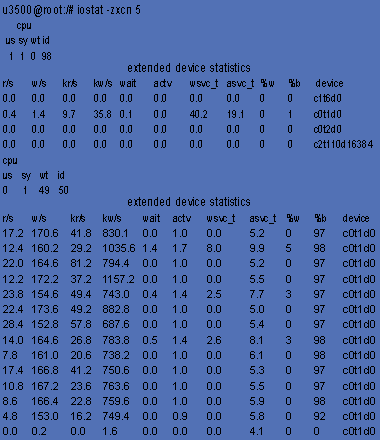
Аналогично командам vmstat и mpstat, внимания заслуживает только часть показателей, выдаваемых командой iostat (см. Листинг 3). К ним относятся:
Если последние три показателя близки к нулю, то это означает, что серверные диски достаточно быстрые, а ввод/вывод оптимально распределен между контроллерами и не создает «узких» мест, т. е. «все в норме». На практике для диска, находящегося под нагрузкой, значения показателя asvc_t будут не нулевые, поскольку любому диску требуется некоторое время на исполнение запросов ввода/вывода.
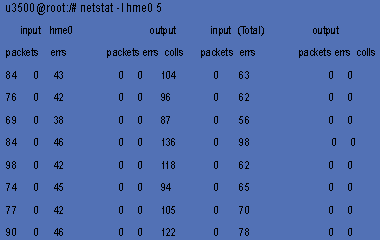
К сожалению, встроенная в Solaris команда netstat выдает очень ограниченный набор информации (см. Листинг 4), на основании которой можно было бы сделать адекватные выводы о проблемах с производительностью сети. Нужно обратить внимание лишь на то, чтобы число ошибок (errs) и коллизий (colls) было близко или равнялось нулю.
 |
| Листинг 4 |
Применение рассмотренных выше команд удобно при анализе функционирования одного-единственного сервера. Если же необходимо контролировать работу нескольких серверов и своевременно выявлять неполадки, то лучше воспользоваться развитыми средствами, в частности коммерческими пакетами Sun Management Center, HP OpenView или BMC PATROL.
Перечисленные продукты имеют развитый механизм задания правил, на основе которых они сообщают администратору о проблеме с производительностью (и не только) на контролируемых серверах. Детальное рассмотрение указанных продуктов выходит за рамки этой статьи.
Практический опыт создания и эксплуатации систем показывает, что наибольший выигрыш можно получить путем оптимизации не настроек сервера, а приложения. К сожалению, в силу ряда причин это не всегда возможно (например, из-за отсутствия исходного кода), поэтому еще одной точкой приложения усилий является оптимизация настроек такого программного обеспечения, как СУБД Oracle.
Но прежде, чем заниматься настройками, необходимо проанализировать статистику работы СУБД. С этой целью в Oracle используются специальные системные виды (View), названия которых начинаются с v$. Эти объекты представляют внутренние структуры Oracle, где накапливается статистика. Процесс накопления статистики должен быть включен, например, с помощью команды:
alter system set timed_statistics = true;
Для облегчения получения статистики в поставку Oracle входят два сценария: utlbstat.sql и utlestat.sql. Запуск utlbstat.sql инициализирует процесс сбора статистики и создания отчета, по окончании определенного промежутка времени необходимо запустить сценарий utlestat.sql, чтобы сгенерировать отчет о работе СУБД за этот период. Результат будет помещен в файл report.txt.
Детальное рассмотрение всех параметров СУБД ORACLE, которые необходимо проанализировать для выявления «узких» мест, опять же выходит за рамки данной статьи. (Более подробную информацию можно найти по указанным в «Ресурсах Internet» ссылках.)
ЧТО ПРЕДПРИНЯТЬ?
Как уже отмечалось вначале, рецептов по оптимизации системы на все случаи жизни не существует. К универсальным советам можно отнести только следующие очевидные рекомендации.
Относительно оптимизации производительности СУБД Oracle под управлением ОС Solaris можно дать следующие общие рекомендации.
Одним из «узких» мест в работе СУБД является ввод/вывод на диски. Встроенный в ОС Solaris механизм Kernel Asynchronous I/O (KAIO) позволяет сократить накладные расходы (перемещение блоков данных из SGA Oracle в кэш файловой системы и др.) при вводе/выводе данных Oracle на диски. Но для этого необходимо, чтобы файлы данных Oracle (datafiles) располагались на так называемых устройствах непосредственного доступа (raw device) OC Solaris. Это не всегда удобно, поскольку на raw device, где хранятся datafiles Oracle, файловая система отсутствует. Устранить данное неудобство позволяет опция Quick I/O файловой системы VERITAS (стандартная файловая система UFS в ОС Solaris имеет подобную опцию — Direct I/O, но та менее эффективна), она дает тот же эффект по устранению накладных расходов, но на файловой системе VxFS. Данная опция лицензируется в составе пакета VERITAS Database Edition for Oracle.
Переключение процессора с выполнения одного процесса на другой ведет к дополнительным нежелательным задержкам. Чтобы процессы Oracle не конкурировали между собой и с другими процессами, в многопроцессорной системе рекомендуется назначить им конкретные процессоров или группу процессоров, посредством команды pbind или psrset. Для более гибкого распределения вычислительных ресурсов сервера между процессами и управления ими рекомендуется воспользоваться программным средством Resource Manager, входящим в состав Solaris 9 OE.
Серверы Sun Fire моделей от F3800 до 15K имеют разные уровни латентности между компонентами. Это означает, что при доступе процессора к памяти, находящейся на другой процессорной плате, времени тратится больше, чем при доступе к памяти, размещенной на той же плате, что и сам процессор (практически архитектура NUMA). Часть процессов Oracle имеет свою «внутреннюю» память, и при этом все обращаются к общей — SGA. Чтобы оптимизировать процесс обращения к памяти, в Solaris 9 была включена функция Memory Placement Option. Эта опция в полном объеме работает для указанных серверов, начиная с редакции Solaris 9 12/02 OE. По возможности, рекомендуется использовать Solaris 9 названной или более поздней редакции. СУБД Oracle 9i «умеет» пользоваться данной опцией.



