IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
Проектирование баз данных. Информационная избыточность. Избыточность данных в базе данных. Проблемы возникающие из-за информационной избыточности
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем сегодня рубрику Заметки о MySQL, в которой я успел описать установку MySQL сервера, настройку MySQL сервера и файл my.ini, а также поговорил о видах и типах баз данных. Сегодня я хотел бы поговорить об аномалиях в базе данных и проблеме избыточности данных в базе данных, то есть о избыточности информации.
Как и обещал, эта статья и следующая тоже будут посвящены проектированию баз данных, моделированию баз данных или созданию баз данных, как хотите, так и называйте. Данная публикация посвящена проблемам, которые могут возникнуть при проектирование базы данных, точнее одной из проблем.
Попытаюсь рассказать, как обычно на пальцах, что такое информационная избыточность и избыточность данных в базе данных. Также попытаюсь рассказать о проблемах обработки данных, которые могут возникнуть из-за избыточности информации, затрону тему целостности данных в базе данных. Немного затрону тему нормализации базы данных и нормальных форм, нормальные формы – это тема следующей публикации. Какие нормальные формы бывают и как привести базу данных к нормальной форме. Всё это вы найдете в следующей публикации.

Избавиться от избыточности данных, а следовательно и от аномалий баз данных – это вопрос проектирования баз данных. И решать вопрос устранения избыточности в базе данных следует до того, как вы начали ее реализовывать программно, то есть, до того как начали создавать базу данных в той или иной СУБД, в нашем случае СУБД MySQL.
Чтобы избавиться от информационной избыточности, а вместе с тем решить проблему модификации, удаления и добавления данных вам не потребуется каких-либо специальных программ, достаточно будет представлять структуру проектируемого объекта(заметьте, пока еще не структуру базы данных), иметь под рукой несколько чистых листов бумаги, карандаш или ручку. Но, чтобы начать от чего-то избавляться, нужно знать суть самой проблемы, из-за чего эта проблема возникает и так ли она для вас критична.
Из-за избыточности информации в базе данных возникают не только проблемы модификации, добавления и удаления данных из базы данных, но и остро встает вопрос экономии места на диске, согласитесь глупо хранить одну и ту же информацию в разных местах. Избыточность баз данных тесно связана с нормальными формами. Точнее, информационная избыточность – это отрицательный фактор, влияющий на целостность базы данных, вынуждающий нас приводить свои базы данных к нормальной форме.
Данная публикации как раз и предназначена для тех, кто хочет быстро разобраться с тем, что такое информационная избыточность и избыточность данных в базе данных, а так же тем, кто хочет разобраться с вопросом, как избавиться от избыточности данных.
Информационная избыточность. Избыточность базы данных. Что такое избыточность.
Начнем мы с информационной избыточности и избыточности реляционных баз данных в частности. Поскольку, эта самая избыточность и заставляет нас нормализовывать базы данных.
Для начала напишу умное определение избыточности, а затем постараюсь объяснить его по-русски.
Информационная избыточность – термин из теории информации, означающий превышение количества информации, используемой для передачи или хранения сообщения, над его информационной энтропией.
Давайте начнем разбираться с определением избыточности и начнем с термина информационная энтропия.
Информационная энтропия – это мера неопределенности информации, неопределенность появления какого-либо символа. Данное определение появилось в теории электросвязи. Для администратора баз данных информационную энтропию следует интерпретировать немного по-другому: информационная энтропия всё также мера неопределенности информации, но, какая информационная неопределенность может возникнуть в базе данных?
Например, у нас есть база данных, в которой хранится библиотека и есть писатель Иванов И.И., сколько книг написал Иванов И.И.? Бог его знает. Может одну, а может и сто. И сколько раз появится этот Иванов И.И. в нашей таблице, мы не знаем. Такая вот неопределенность информации.
Любая база данных предназначена для хранения информации. И при проектирование базы данных следует учесть то, что какая-то информация может повторяться несколько раз. А каждая повторяющаяся запись – это занятое место на диске. То есть превышение количества информации необходимого для хранения данных.
Конечно, можно сказать, что сейчас, с появлением терабайтных накопителей отпала необходимость экономить место на диске. Но информационная избыточность ведет не только к увеличению требуемого объема памяти для хранения информации содержащейся в базе данных.
Избыточность данных в базе данных – это нежелательное явление еще и потому, что при работе с таблицами базы данных (которые еще называют отношениями), содержащими избыточные данные возникают проблемы связанные с обработкой информации, эти проблемы называются аномалии. Про аномалии баз данных читайте в следующем разделе.
Последствия информационной избыточности в базе данных. Избыточность данных. Аномалии (проблемы) в базе данных.
Как мы уже выяснили, избыточность информации ведет не только к тому, что требуется увеличение объема накопителей, но и приводит к аномалиям в базе данных.
Аномалии в базе данных – это проблемы связанные с обработкой информации, а точнее с удаление данных из базы данных, с модификацией данных в таблице базы данных и аномалия добавления данных в базу данных.
Как вы поняли, в базе данных есть три аномалии:
Все эти проблемы связаны с целостностью баз данных, а именно с избыточностью данных в базе данных. Давайте остановимся подробней на каждой аномалии.
Давайте посмотрим на примере приближенном к реальности, что такое избыточность данных. Допустим, у нас есть таблица, в которой хранятся данные список преподавателей и список предметов, которые они ведут. Естественно, в это таблице присутствует информационная избыточность.
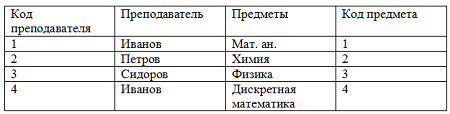
Таблица с информационной избыточностью
Избыточность данных в этой таблице заключается в том, что любой преподаватель может вести несколько предметов, как преподаватель Иванов и для каждого нового предмета приходится добавлять новые записи в таблицу.
Один преподаватель может вести разные предметы, а разные предметы могут вести разные преподаватели. Давайте посмотрим, какие аномалии могут произойти в данном конкретном случае и как можно избавиться от аномалий в конкретном случае.
Аномалия включения. Проблема добавления данных в базу данных.
Избыточность данных очевидна, поскольку произошло дублирование информации, преподаватель Иванов ведет два предмета и его пришлось вписать дважды в таблицу. Но это еще не всё. Допустим, в нашей школе появился новый предмет и мы хотим его добавить в существующую таблицу базы данных, но мы еще не нашли преподавателя для этого предмета. А вписать в таблицу предмет нужно уже сейчас.
В этом случае мы должны присвоить значение NULL каждому атрибуту преподавателя, но делать это никак нельзя, так как атрибут «Код преподавателя» является первичным ключом отношения (первичным ключом таблицы). Результатом попытки создания такой записи будет нарушение целостности данных базы данных, а любая СУБД, в том числе и СУБД MySQL отклонит подобную попытку создания такой записи.
Все вышеописанное является аномалией включения. Чтобы избавиться от аномалии включения нужно разбить таблицу на две: таблица преподавателей и таблица предметов. Примерно это будет выглядеть так:
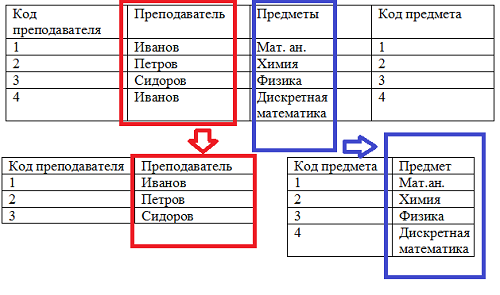
Избавляемся от избыточности данных в базе данных.
Здесь мы разделили общую таблицу, тем самым избавились от аномалии включения и от возникшей информационной избыточности, то есть от дублирования в базе данных. В принципе то, что мы сделали в данный момент – привели базу данных ко второй нормальной форме.
Вторая нормальная форма позволяет нам избавиться от аномалии включения, а также от дублирования информации в базе данных, то есть мы избавляемся от избыточности информации.
Аномалия модификации. Проблема изменения базы данных.
Следующая проблема, которая может возникнуть из-за избыточности базы данных – это проблема внесения изменений в таблицы базы данных или как ее еще называют – аномалия модификации.
В нашем примере проблема модификации могла бы возникнуть при попытке изменения фамилий преподавателей, например, если бы в этом списке была незамужняя женщина с фамилией Сидорова, то возможно, когда-нибудь она вышла бы замуж и поменяла фамилию, а оператору пришлось бы для каждой записи, в которой имелась фамилия Сидорова заменить на новую фамилию. Это довольно нудная работа. Каждая такая запись или строка таблицы базы данных называется кортежем.
Чтобы избавиться от аномалии модификаций и все связанные с ней проблемы мы можем прибегнуть к предыдущему способу, просто разбиваем одну большую таблицу на две маленьких. То есть, приводим базу данных ко второй нормальной форме или просто нормализуем.
И опять же, таким образом мы избавляемся от дублирования данных в базе данных. Все довольно просто.
Аномалия удаления. Проблема удаления данных из базы данных.
Проблема удаления данных из базы данных – это еще одна проблема, которая появляется, если данные в базе избыточны ее еще называют аномалия удаления. Проблема удаления данных из базы данных заключается в том, что при удаление одной записи или кортежа из таблицы, относящейся к какому-либо из преподавателю, вместе с записью о преподавателе, из базы данных удалится вся информация о предмете, который вел этот преподаватель.
Решается проблема удаления данных из базы данных очень просто, нормализуем базу данных до второй нормальной формы, то есть разделяем таблицу на две, как это показано в разделе посвященном аномалии включения.
Обратите внимание: типы данных у различных СУБД могут быть разными, у MySQL типы данных одни, у какой-либо другой СУБД могут быть другие типы данных, как и у языков программирования. У JavaScript типы данных одни, а у PHP типы данных другие.
Руководство по проектированию реляционных баз данных (10-13 часть из 15) [перевод]
Продолжение.
Предыдущие части: 1-3, 4-6, 7-9
10. Нормализация баз данных
Указания для правильного проектирования реляционных баз данных изложены в реляционной модели данных. Они собраны в 5 групп, которые называются нормальными формами. Первая нормальная форма представляет самый низкий уровень нормализации баз данных. Пятый уровень представляет высший уровень нормализации.
Вот некоторые из основных пунктов, которые связаны с нормализацией баз данных:
Очень малое количество баз данных следуют всем пяти нормальным формам, предоставленным в реляционной модели данных. Обычно базы данных нормализуются до второй или третьей нормальной формы. Четвертая и пятая формы используются редко. Поэтому я ограничусь тем, чтобы рассказать вам лишь о первых трех.
11. Первая нормальная форма (1НФ)
Первая нормальная форма гласит, что таблица базы данных – это представление сущности вашей системы, которую вы создаете. Примеры сущностей: заказы, клиенты, заказ билетов, отель, товар и т.д. Каждая запись в базе данных представляет один экземпляр сущности. Например, в таблице клиентов каждая запись представляет одного клиента.
Первичный ключ.
Правило: каждая таблица имеет первичный ключ, состоящий из наименьшего возможного количества полей.
Как вы знаете, первичный ключ может состоять из нескольких полей. Вы, к примеру, можете выбрать имя и фамилию в качестве первичного ключа (и надеяться, что эта комбинация будет уникальной всегда). Будет намного более хорошим выбором номер соц. Страхования в качестве первичного ключа, т.к. это единственное поле, которое уникальным образом идентифицирует человека.
Еще лучше, когда нет очевидного кандидата на звание первичного ключа, создайте суррогатный первичный ключ в виде числового автоинкрементного поля.
Атомарность.
Правило: поля не имеют дубликатов в каждой записи и каждое поле содержит только одно значение.
Возьмем, например, сайт коллекционеров автомобилей, на котором каждый коллекционер может зарегистрировать его автомобили. Таблица ниже хранит информацию о зарегистрированных автомобилях.

Горизонтальное дублирование данных – плохая практика.
С таким вариантом проектирования вы можете сохранить только пять автомобилей и если у вас их менее 5, то вы тратите впустую свободное место в базе данных на хранение пустых ячеек.
Другим примером плохой практики при проектировании является хранение множественных значений в ячейке.
Множественные значения в одной ячейке.
Верным решением в данном случае будет выделение автомобилей в отдельную таблицу и использование внешнего ключа, который ссылается на эту таблицу.
Порядок записей не должен иметь значение.
Правило: порядок записей таблицы не должен иметь значения.
Вы можете быть склонны использовать порядок записей в таблице клиентов для определения того, какой из клиентов зарегистрировался первым. Для этих целей вам лучше создать поля даты и времени регистрации клиентов. Порядок записей будет неизбежно меняться, когда клиенты будут удаляться, изменяться или добавляться. Вот почему вам никогда не следует полагаться на порядок записей в таблице.
В следующей части рассмотрим вторую нормальную форму (2НФ).
12. Вторая нормальная форма.
Для того, чтобы база данных была нормализована согласно второй нормальной форме, она должна быть нормализована согласно первой нормальной форме. Вторая нормальная форма связана с избыточностью данных.
Избыточность данных.
Правило: поля с не первичным ключом не должны быть зависимы от первичного ключа.
Может звучать немного заумно. А означает это то, что вы должны хранить в таблице только данные, которые напрямую связаны с ней и не имеют отношения к другой сущности. Следование второй нормальной форме – это вопрос нахождения данных, которые часто дублируются в записях таблицы и которые могут принадлежать другой сущности.
Дублирование данных среди записей в поле store.
Таблица выше может принадлежать компании, которая продает автомобили и имеет несколько магазинов в Нидерландах.
Если посмотрите на эту таблицу, то вы увидите множественные примеры дублирования данных среди записей. Поле brand могло бы быть выделено в отдельную таблицу. Также, как и поле type (модель), которое также могло бы быть выделено в отдельную таблицу, которая бы имела связь многие-к-одному с таблицей brand потому, что у бренда могут быть разные модели.
Колонка store содержит наименование магазина, в котором в настоящее время находится машина. Store – это очевидный пример избыточности данных и хороший кандидат для отдельной сущности, которая должна быть связана с таблицей автомобилей связью по внешнему ключу.
Ниже пример того, как бы вы моги смоделировать базу данных для автомобилей, избегая избыточности данных.
В примере выше таблица car имеет внешний ключ – ссылку на таблицы type и store. Столбец brand исчез потому, что на бренд есть неявная ссылка через таблицу type. Когда есть ссылка на type, есть ссылка и на brand, т.к. type принадлежит brand.
Избыточность данных была существенным образом устранена из нашей модели базы данных. Если вы достаточно придирчивы, то вы, возможно, еще не удовлетворены этим решением. А как насчет поля country_of_origin в таблице brand? Пока дубликатов нет потому, что есть только четыре бренда из разных стран. Внимательный разработчик базы данных должен выделить названия стран в отдельную таблицу country.
И даже сейчас вы не должны быть удовлетворены результатом потому, что вы также могли бы выделить поле color в отдельную таблицу.
Насколько строго вы подходите к созданию ваших таблиц – решать вам и зависит от конкретной ситуации. Если вы планируете хранить огромное количество единиц автомобилей в системе и вы хотите иметь возможность производить поиск по цвету (color), то было бы мудрым решением выделить цвета в отдельную таблицу так, чтобы они не дублировались.
Существует другой случай, когда вы можете захотеть выделить цвета в отдельную таблицу. Если вы хотите позволить работникам компании вносить данные о новых автомобилях вы захотите, чтобы они имели возможно выбирать цвет машины из заранее заданного списка. В этом случае вы захотите хранить все возможные цвета в вашей базе данных. Даже если еще нет машин с таким цветом, вы захотите, чтобы эти цвета присутствовали в базе данных, чтобы работники могли их выбирать. Это определенно тот случай, когда вам нужно выделить цвета в отдельную таблицу.
13. Третья нормальная форма.
Третья нормальная форма связана с транзитивными зависимостями. Транзитивные зависимости между полями базы данных существует тогда, когда значения не ключевых полей зависят от значений других не ключевых полей. Чтобы база данных была в третьей нормальной форме, она должна быть во второй нормальной форме.
Транзитивные зависимости.
Правило: не может быть транзитивных зависимостей между полями в таблице.
Таблица клиентов (мои клиенты – игроки немецкой и французской футбольной команды) ниже содержит транзитивные зависимости.
В этой таблице не все поля зависят исключительно от первичного ключа. Существует отдельная связь между полем postal_code и полями города (city) и провинции (province). В Нидерландах оба значение: город и провинция – определяются почтовым кодом, индексом. Таким образом, нет необходимости хранить город и провинцию в клиентской таблице. Если вы знаете почтовый код, то вы уже знаете город и провинцию.
Такая транзитивной зависимости следует избегать, если вы хотите, чтобы ваша модель базы данных была в третьей нормальной форме.
В данном случае устранение транзитивной зависимости из таблицы может быть достигнуто путем удаления полей города и провинции из таблицы и хранение их в отдельной таблице, содержащей почтовый код (первичный ключ), имя провинции и имя города. Получение комбинации почтовый код-город-провинция для целой страны может быть весьма нетривиальным занятием. Вот почему такие таблицы зачастую продаются.
Другим примером для применения третьей нормальной формы может служить (слишком) простой пример таблицы заказов интернет-магазина ниже.
НДС (value added tax) – это процент, который добавляется к цене продукта (19% в данной таблице). Это означает, что значение total_ex_vat может быть вычислено из значения total_inc_vat и vice versa. Вы должны хранить в таблице одно из этих значений, но не оба сразу. Вы должны возложить задачу вычисления total_inc_vat из total_ex_vat или наоборот на программу, которая использует базу данных.
Третья нормальная форма гласит, что вы не должны хранить данные в таблице, которые могут быть получены из других (не ключевых) полей таблицы. Особенно в примере с таблицей клиентов следование третьей нормальной форме требует либо большого объема работы, либо приобретения коммерческой версии данных для такой таблицы.
Третья нормальная форма не всегда используется при проектировании баз данных. Когда разрабатываете базу данных вы всегда должны сравнивать преимущества от более высокой нормальной формы в сравнении с объемом работ, которые требуются для применения третьей нормальной формы и поддержания данных в таком состоянии. В случае с клиентской таблицей лично я бы предпочел не нормализовать таблицу до третьей нормальной формы. В последнем примере с НДС я бы использовал третью нормальную форму. Хранение данных, воспроизводимых из существующих, обычно плохая идея.
Избыточность информации
Связанные понятия
Упоминания в литературе
Связанные понятия (продолжение)
Хеш-деревом, деревом Меркла (англ. Merkle tree) называют полное двоичное дерево, в листовые вершины которого помещены хеши от блоков данных, а внутренние вершины содержат хеши от сложения значений в дочерних вершинах. Корневой узел дерева содержит хеш от всего набора данных, то есть хеш-дерево является однонаправленной хеш-функцией. Дерево Меркла применяется для эффективного хранения транзакций в блокчейне криптовалют (например, в Bitcoin’е, Ethereum’е). Оно позволяет получить «отпечаток» всех транзакций.
В статистике метод оценки с помощью апостериорного максимума (MAP) тесно связан с методом максимального правдоподобия (ML), но дополнительно при оптимизации использует априорное распределение величины, которую оценивает.
В программировании, ассемблерной вставкой называют возможность компилятора встраивать низкоуровневый код, написанный на ассемблере, в программу, написанную на языке высокого уровня, например, Си или Ada. Использование ассемблерных вставок может преследовать следующие цели.
Парсер (англ. parser; от parse – анализ, разбор) или синтаксический анализатор — часть программы, преобразующей входные данные (как правило, текст) в структурированный формат. Парсер выполняет синтаксический анализ текста.
Не путайте с ECC памятью, хотя регистровые модули всегда используют ECC.Регистровая память (англ. Registered Memory, RDIMM, иногда buffered memory) — вид компьютерной оперативной памяти, модули которой содержат регистр между микросхемами памяти и системным контроллером памяти. Наличие регистров уменьшает электрическую нагрузку на контроллер и позволяет устанавливать больше модулей памяти в одном канале. Регистровая память является более дорогой из-за меньшего объема производства и наличия дополнительных.
В области телекоммуникаций и информатике параллельным соединением называют метод передачи нескольких сигналов с данными одновременно по нескольким параллельным каналам. Это принципиально отличается от последовательного соединения; это различие относится к одной из основных характеристик коммуникационного соединения.
Коды избыточности: простыми словами о том, как надёжно и дёшево хранить данные

Так выглядит избыточность
Коды избыточности* широко применяются в компьютерных системах для увеличения надёжности хранения данных. В Яндексе их используют в очень многих проектах. Например, применение кодов избыточности вместо репликации в нашем внутреннем объектном хранилище экономит миллионы без снижения надёжности. Но несмотря на широкое распространение, понятное описание того, как работают коды избыточности, встречается очень редко. Желающие разобраться сталкиваются примерно со следующим (из Википедии):
Меня зовут Вадим, в Яндексе я занимаюсь разработкой внутреннего объектного хранилища MDS. В этой статье я простыми словами опишу теоретические основы кодов избыточности (кодов Рида — Соломона и LRC). Расскажу, как это работает, без сложной математики и редких терминов. В конце приведу примеры использования кодов избыточности в Яндексе.
Ряд математических деталей я не буду рассматривать подробно, но дам ссылки для тех, кто хочет погрузиться глубже. Также замечу, что некоторые математические определения могут быть не строгими, так как статья рассчитана не на математиков, а на инженеров, желающих разобраться в сути вопроса.
* Под термином «коды избыточности» в статье подразумевается инженерный термин «erasure codes».
1. Суть кодов избыточности
Суть всех кодов избыточности предельно простая: хранить (или передавать) данные так, чтобы они не пропадали при возникновении ошибок (поломках дисков, ошибках передачи данных и т. д.).
В большинстве* кодов избыточности данные разбиваются на n блоков данных, для них считается m блоков кодов избыточности, всего получается n + m блоков. Коды избыточности строятся таким образом, чтобы можно было восстановить n блоков данных, используя только часть из n + m блоков. Далее мы рассмотрим только блочные коды избыточности, то есть такие, в которых данные разбиваются на блоки.

Чтобы восстановить все n блоков данных, нужно иметь минимум n из n + m блоков, так как нельзя получить n блоков, имея только n-1 блок (в этом случае пришлось бы 1 блок брать «из воздуха»). Достаточно ли n произвольных блоков из n + m блоков для восстановления всех данных? Это зависит от типа кодов избыточности, например коды Рида — Соломона позволяют восстановить все данные с помощью произвольных n блоков, а коды избыточности LRC — не всегда.
Хранение данных
В системах хранения данных, как правило, каждый из блоков данных и блоков кодов избыточности записывается на отдельный диск. Тогда при поломке произвольного диска исходные данные все равно можно будет восстановить и прочитать. Данные можно будет восстановить даже при одновременной поломке нескольких дисков.
Передача данных
Коды избыточности можно использовать для надёжной передачи данных в ненадёжной сети. Передаваемые данные разбивают на блоки, для них считают коды избыточности. По сети передаются и блоки данных, и блоки кодов избыточности. При возникновении ошибок в произвольных блоках (вплоть до некоторого количества блоков), данные все равно можно безошибочно передать по сети. Коды Рида — Соломона, например, используют для передачи данных по оптическим линиям связи и в спутниковой связи.
* Есть также коды избыточности, в которых данные не разбиваются на блоки, например коды Хэмминга и коды CRC, широко применяемые для передачи данных в сетях Ethernet. Это коды для помехоустойчивого кодирования, они предназначены для обнаружения ошибок, а не для их исправления (код Хэмминга также позволяет частично исправлять ошибки).
2. Коды Рида — Соломона
Коды Рида — Соломона — одни из наиболее широко распространённых кодов избыточности, изобретённые ещё в 1960-х и впервые получившие широкое применение в 1980-х для серийного выпуска компакт-дисков.
Ключевых вопросов для понимания кодов Рида — Соломона два: 1) как создавать блоки кодов избыточности; 2) как восстанавливать данные с помощью блоков кодов избыточности. Найдем на них ответы.
Для упрощения далее будем считать, что n=6 и m=4. Другие схемы рассматриваются по аналогии.
Как создавать блоки кодов избыточности
Каждый блок кодов избыточности считается независимо от остальных. Для подсчёта каждого блока используются все n блоков данных. На схеме ниже X1-X6 — блоки данных, P1–P4 — блоки кодов избыточности.

Все блоки данных должны быть одинакового размера, для выравнивания можно использовать нулевые биты. Полученные блоки кодов избыточности будут иметь тот же размер, что и блоки данных. Все блоки данных разбиваются на слова (например, по 16 бит). Допустим, мы разбили блоки данных на k слов. Тогда все блоки кодов избыточности тоже будут разбиты на k слов.

Для подсчёта i-го слова каждого блока избыточности будут использоваться i-е слова всех блоков данных. Они будут считаться по следующей формуле:
Зачем нужны поля Галуа

Казалось бы, всё просто: разбиваем данные на блоки, блоки — на слова, с помощью слов блоков данных считаем слова блоков кодов избыточности — получаем блоки кодов избыточности. В целом это так и работает, но дьявол в деталях:
Эти проблемы не позволяют использовать для кодов Рида — Соломона целые числа. Решение проблемы оригинальное, его можно описать следующим образом: давайте придумаем специальные числа, которые можно представить с помощью слов нужной длины (например, 16 бит), и результат выполнения всех операций над которыми (сложение, вычитание, умножение, деление) также будет представлен в памяти компьютера при помощи слов нужной длины.
Такие «специальные» числа давно изучает математика, их называют полями. Поле — это множество элементов с определёнными для них операциями сложения, вычитания, умножения и деления.
Таким образом, мы имеем систему уравнений, с помощью которых можно построить блоки кодов избыточности, написав соответствующую компьютерную программу. С помощью этой же системы уравнений можно выполнить восстановление данных.
* Это не строгое определение, скорее описание.
Как восстанавливать данные
Восстановление нужно тогда, когда из n + m блоков часть блоков отсутствует. Это могут быть как блоки данных, так и блоки кодов избыточности. Отсутствие блоков данных и/или блоков кодов избыточности будет означать, что в уравнениях выше неизвестны соответствующие переменные x и/или p.
Уравнения для кодов Рида — Соломона можно рассматривать как систему уравнений, в которых все значения альфа, бета, гамма, дельта — константы, все x и p, соответствующие доступным блокам, — известные переменные, а остальные x и p — неизвестные.
Например, пусть блоки данных 1, 2, 3 и блок кодов избыточности 2 недоступны, тогда для i-й группы слов будет следующая система уравнений (неизвестные отмечены красным):
Мы имеем систему из 4 уравнений с 4 неизвестными, значит можем решить её и восстановить данные!
Из этой системы уравнений следуют ряд выводов про восстановление данных для кодов Рида — Соломона (n блоков данных, m блоков кодов избыточности):
Что ещё нужно знать
В описании выше я обхожу стороной ряд важных вопросов, для рассмотрения которых нужно глубже погружаться в математику. В частности, ничего не говорю про следующее:
В конце статьи есть ссылки на литературу по этим важным вопросам.
Выбор n и m
Как на практике выбрать n и m? На практике в системах хранения данных коды избыточности используют для экономии места, поэтому m выбирают всегда меньше n. Их конкретные значения зависят от ряда факторов, в том числе:
Кроме того, хранение данных в нескольких ДЦ накладывает дополнительные ограничения на выбор n и m: при отключении 1 ДЦ данные всё ещё должны быть доступны для чтения. Например, при хранении данных в 3 ДЦ должно выполняться условие: m >= n/2, в противном случае возможна ситуация, когда данные недоступны для чтения при отключении 1 ДЦ.
3. LRC — Local Reconstruction Codes
Для восстановления данных с помощью кодов Рида — Соломона приходится использовать n произвольных блоков данных. Это очень существенный минус для распредёленных систем хранения данных, ведь для восстановления данных на одном сломанном диске придётся читать данные с большинства остальных, создавая большую дополнительную нагрузку на диски и сеть.
Наиболее часто встречающиеся ошибки — недоступность одного блока данных из-за поломки или перегруженности одного диска. Можно ли как-то уменьшить избыточную нагрузку для восстановления данных в таком (наиболее частом) случае? Оказывается, можно: специально для этого существуют коды избыточности LRC.
LRC (Local Reconstruction Codes) — коды избыточности, придуманные в Microsoft для применения в Windows Azure Storage. Идея LRC максимально проста: разбить все блоки данных на две (или более) группы и считать часть блоков кодов избыточности для каждой группы по отдельности. Тогда часть блоков кодов избыточности будет подсчитана с помощью всех блоков данных (в LRC они называются глобальными кодами избыточности), а часть — с помощью одной из двух групп блоков данных (они называются локальными кодами избыточности).
LRC обозначается тремя числам: n-r-l, где n — количество блоков данных, r — количество глобальных блоков кодов избыточности, l — количество локальных блоков кодов избыточности. Для чтения данных при недоступности одного блока данных нужно прочитать только n/l блоков — это в l раз меньше, чем в кодах Рида — Соломона.
Для примера рассмотрим схему LRC 6-2-2. X1–X6 — 6 блоков данных, P1, P2 — 2 глобальных блока избыточности, P3, P4 — 2 локальных блока избыточности.

Блоки кодов избыточности P1, P2 считаются с помощью всех блоков данных. Блок кодов избыточности P3 — с помощью блоков данных X1–X3, блок кодов избыточности P4 — с помощью блоков данных X4–X6.
Остальное делается в LRC по аналогии с кодами Рида — Соломона. Уравнения для подсчёта слов блоков кодов избыточности будут такими:
Для подбора чисел альфа, бета, гамма, дельта нужно выполнить ряд условий, гарантирующих возможность восстановления данных (то есть решения системы уравнения). Подробнее о них можно прочитать в статье.
Также на практике для подсчёта локальных кодов избыточности P3, P4 применяют операцию XOR.
Из системы уравнений для LRC следует ряд выводов:
Таким образом, LRC выигрывает у кодов Рида — Соломона в восстановлении данных после одиночных ошибок. В кодах Рида — Соломона для восстановления даже одного блока данных нужно использовать n блоков, а в LRC для восстановления одного блока данных достаточно использовать n/l блоков (n/2 в нашем примере). С другой стороны, LRC проигрывает кодам Рида — Соломона по максимальному количеству допустимых ошибок. В примерах выше коды Рида — Соломона могут восстановить данные при любых 4 ошибках, а для LRC существует 2 комбинации из 4 ошибок, когда данные восстановить нельзя.
Что более важно — зависит от конкретной ситуации, но зачастую экономия избыточной нагрузки, которую даёт LRC, перевешивает чуть меньшую надёжность хранения.
4. Другие коды избыточности
Помимо кодов Рида — Соломона и LRC, есть много других кодов избыточности. Разные коды избыточности используют разную математику. Вот некоторые другие коды избыточности:
5. Использование в Яндексе
Ряд инфраструктурных проектов Яндекса применяет коды избыточности для надёжного хранения данных. Вот несколько примеров:
В MDS используются коды избыточности LRC, схема 8-2-2. Данные с кодами избыточности пишутся на 12 разных дисков в разных серверах в 3 разных ДЦ: по 4 сервера в каждом ДЦ. Подробнее об этом читайте в статье.
В YT используются как коды Рида — Соломона (схема 6-3), которые были реализованы первыми, так и коды избыточности LRC (схема 12-2-2), причём LRC — предпочтительный способ хранения.
В YDB используются коды избыточности, основанные на even-odd (схема 4-2). Про коды избыточности в YDB уже рассказывали на Highload.
Применение разных схем кодов избыточности обусловлено разными требованиями, предъявляемыми к системам. Например, в MDS данные, хранимые с помощью LRC, размещаются сразу в 3 ДЦ. Нам важно, чтобы данные оставались доступными для чтения при выходе из строя 1 любого ДЦ, поэтому блоки должны быть распределены по ДЦ так, чтобы при недоступности любого ДЦ количество недоступных блоков было не больше допустимого. В схеме 8-2-2 можно разместить по 4 блока в каждом ДЦ, тогда при отключении любого ДЦ будет недоступно 4 блока, и данные можно будет читать. Какую бы схему мы ни выбрали при размещении в 3 ДЦ, в любом случае должно быть (r + l) / n >= 0,5, то есть избыточность хранения будет минимум 50%.
В YT ситуация другая: каждый кластер YT целиком располагается в 1 ДЦ (разные кластеры в разных ДЦ), поэтому там нет такого ограничения. Схема 12-2-2 даёт избыточность 33%, то есть хранить данные выходит дешевле, при этом они также могут переживать до 4 одновременных отключений дисков, как и схема в MDS.
Есть ещё много особенностей применения кодов избыточности в системах хранения и обработки данных: нюансы восстановления данных, влияние восстановления на время выполнения запросов, особенности записи данных и т. д. Я собираюсь отдельно рассказать об этих и других особенностях применения кодов избыточности на практике, если тема будет интересна.



