Что такое robots.txt [Основы для новичков]

Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
« Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
«Вкалывают роботы»: что такое robots.txt и как его настроить

Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Переходим в инструмент, вводим домен и содержимое вашего файла.

Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
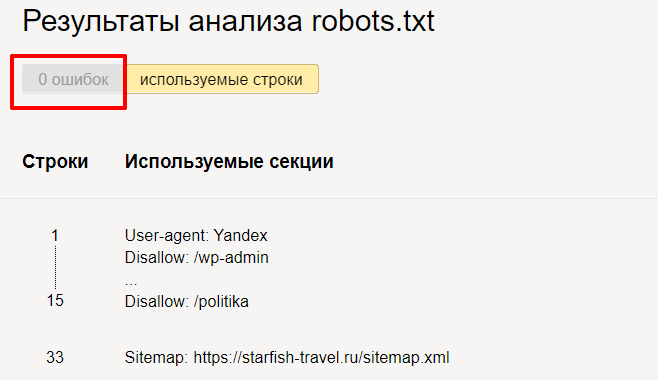
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
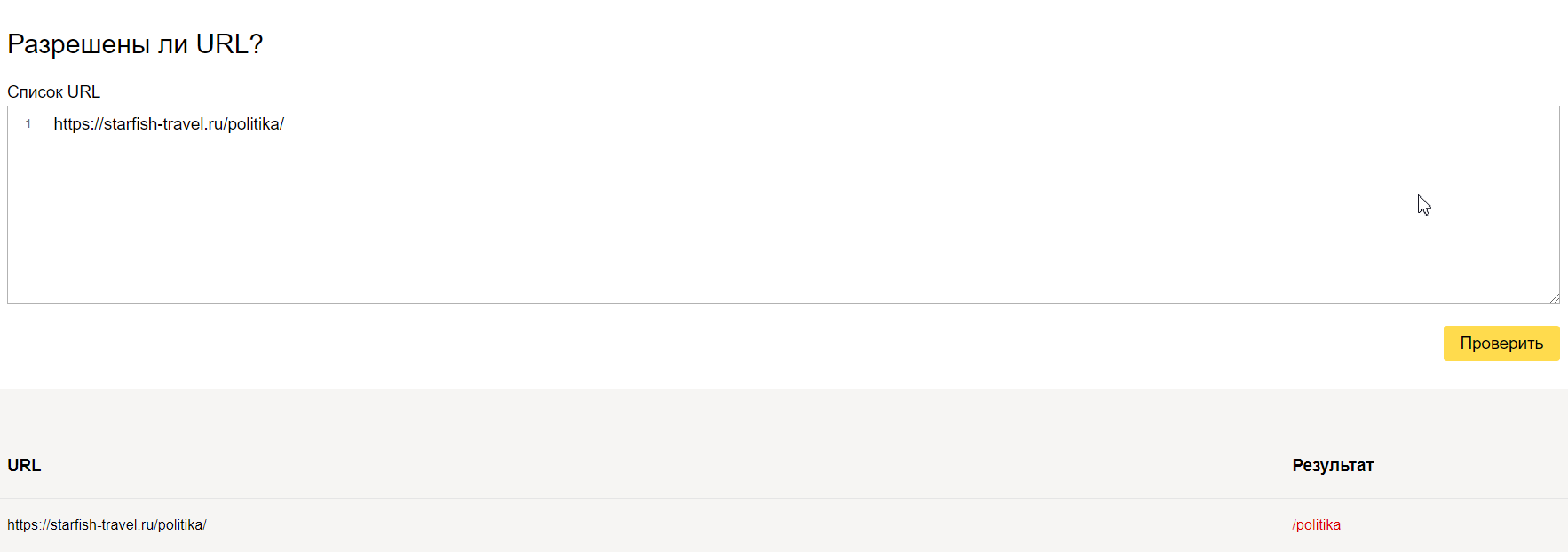
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Как составить правильный robots.txt для Яндекса и Google [инструкция]
Примеры готового файла robots.txt. Решения для сайтов на WordPress, Битрикс, OpenCart и Joomla.
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию HTML-кода страницы:
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
А эта запись запрещает всем роботом сканировать весь сайт:
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
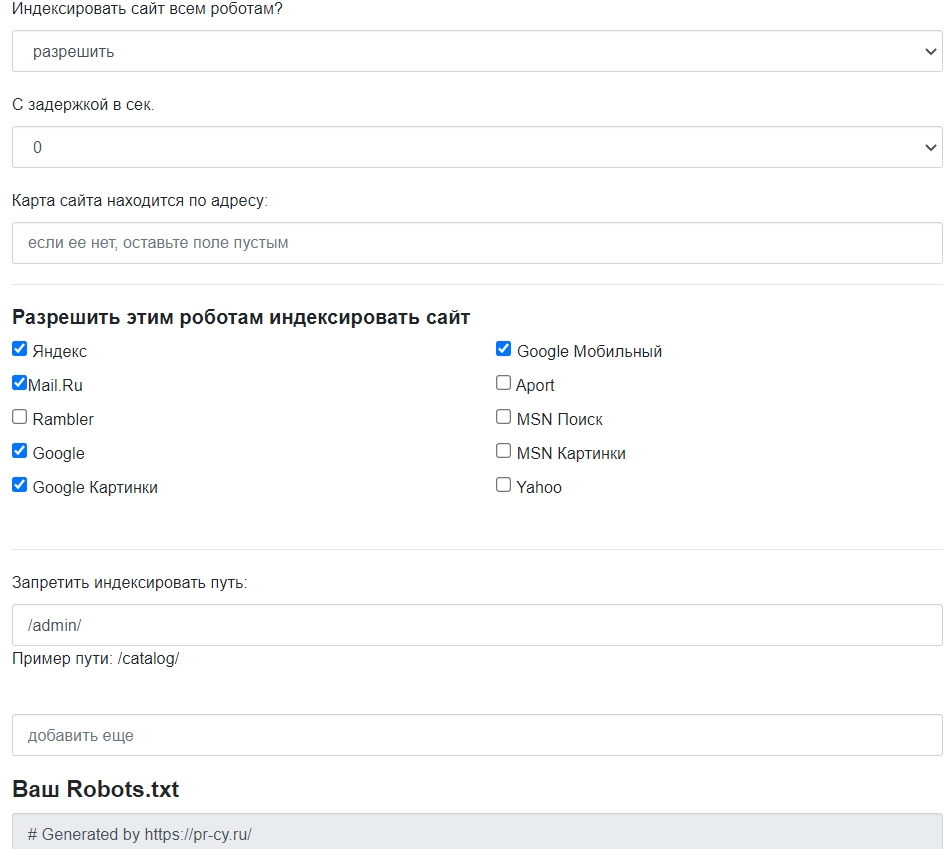 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
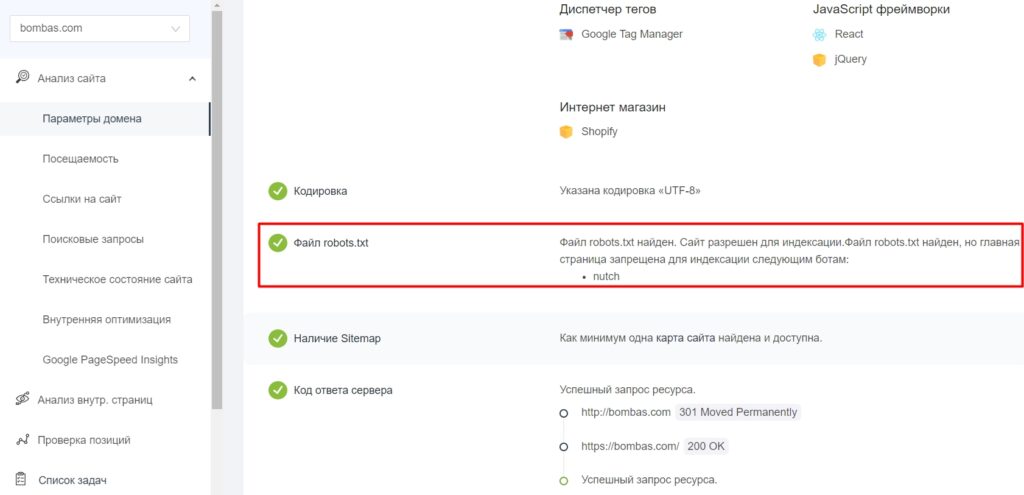 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
Настройка правильного файла robots.txt
Файл robots.txt отвечает за правильный обход сайта поисковыми роботами Яндекс и Google. Его отсутствие или некорректная настройка может привести к неверной индексации, что в свою очередь окажет негативное влияние на позиции сайта в поисковых системах.
1. Создаем записи, которые определяют, для каких поисковых роботов представлены правила:
2. Определяем страницы, которые необходимо закрыть от индексации. В общем случае, это:
Важно! Страницы пагинации должны быть открыты для индексации! Подробнее об индексации пагинации можете прочитать в нашей заметке «Как настроить правильную индексацию страниц пагинации».
3. C помощью директив Disallow и Allow прописываем правила для корректной индексации сайта для каждого User-agent.
Disallow запрещает к индексации указанные после него файлы, а Allow — разрешает. Кроме этого, в данных правилах могут использоваться регулярные выражения с символами «*» и «$». Знак «*» означает любую последовательность символов после него, а знак «$» ее останавливает.
На примере ниже мы запретили к индексации страницу раздела «Статьи» и все страницы, расположенные во вложенном каталоге «SEO».
Стоит отметить, что задав выражение как на скриншоте ниже, мы открываем все вложенные категории и страницы.
Еще один важный момент — определение применяемого правила для страницы, если она подходит под несколько директив. Для этого они сортируются по возрастанию длины префикса URL и применяются по порядку.
Например, у нас есть набор следующих директив:
Чтобы понять, будет ли третье правило применяться, надо их отсортировать по возрастанию длины префикса URL:
Делаем вывод, что страница «Как настроить robots.txt» разрешена к индексированию, а остальные страницы данного раздела — нет.
4. С помощью инструмента «Проверка оптимизации для мобильных устройств» определяем, какие файлы необходимы поисковым роботам для правильной индексации сайта на мобильных устройствах и открываем их для индексации:
5. Добавление директивы Host. С марта 2018 года Яндекс отказался от использования данной директивы. Теперь для указания главного зеркала достаточно настройки 301 редиректов. Указывать директиву Host в robots.txt более не нужно.
6. В конце файла прописываем путь с актуальной картой сайта sitemap.xml.
7. Проверяем правильность заполнения файла robots.txt. Для этого:
В качестве примера можно ознакомиться с настройкой данного файла по ссылке:
Подробные инструкции по настройке robots.txt Вы сможете найти на страницах «Использование robots.txt» от Яндекса и «О файлах robots.txt» от Google.
Ждите новые заметки в блоге или ищите на нашем сайте.
Как правильно прописать Robots.txt
Время чтения: 16 минут Нет времени читать?
Сначало расскажу, что такое robots.txt.
Robots.txt – файл, который находится в корневой папки сайта, где прописываются специальные инструкции для поисковых роботов. Эти инструкции необходимы для того, чтобЫ при заходе на сайт, робот не учитывал страницу/раздел, другими словами мы закрываем страницу от индексации.
Зачем нужен robots.txt
Файл robots.txt считается ключевым требованием при SEO-оптимизации абсолютно любого сайта. Отсутствие этого файла может негативно сказаться на нагрузку со стороны роботов и медленной индексации и, даже более того, сайт полностью не будет проиндексирован. Соответственно пользователи не смогут перейти на страницы через Яндекс и Google.
Влияние robots.txt на поисковые системы?
Поисковые системы (в особенности Google) проиндексируют cайт, но если файла robots.txt нет, то, как и говорил не все страницы. Если имеется такой файл, то роботы руководствуются правилами, которые указываются в этом файле. Причем существует несколько видов поисковых роботов, если одни могут учитывать правило, то другие игнорируют. В частности, робот GoogleBot не учитывает директиву Host и Crawl-Delay, робот YandexNews совсем недавно перестал учитывать директиву Crawl-Delay, а роботы YandexDirect и YandexVideoParser игнорируют общепринятые директивы в robots.txt (но учитывают те, которые прописаны специально для них).
Нагружают сайт больше всего роботы, которые подгружают контент с вашего сайта. Соответственно, если мы укажем роботу, какие страницы индексировать, а какие игнорировать, а также с какими временными промежутками подгружать контент со страниц (это больше качается крупных сайтов у которых имеется более 100 000 страниц в индексе поисковых систем). Это позволит значительно облегчить роботу индексацию и процесс подгружения контента с сайта.

К ненужным для поисковых систем можно отнести файлы которые относятся к CMS, например, в WordPress – /wp-admin/. Помимо этого, скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и так далее.
Для большинства роботов также рекомендую закрыть от индексации все файлы Javascript и CSS. Но для GoogleBot и Yandex такие файлы лучше индексировать, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования.
Что такое директива robots.txt?

Директивы – это и есть правила для поисковых роботов. Первые стандарты по написанию robots.txt и соответственно появились в 1994, а расширенный стандарт в 1996 году. Однако, как вы уже знаете, что не все роботы поддерживают те или иные директивы. Поэтому ниже я расписал чем руководствуются основные роботы при индексации страниц сайта.
Что означает User-agent?
Это самая главная директива, которая определяет для каких поисковых роботов будут действовать следовать дальнейшие правила.



