Тестирование API

Введение: Что такое API
В широком смысле слова API (Application Programming Interface) это метод который приложение предоставляет внешним пользователям для коммуникации с ним. Обычно через Интернет.
Это может быть взаимодействие с сервером приложения на смартфоне, между компьютерами или другими устройствами.
API применяются там где невозможна или нежелательна непосредственная интеграция с исходным приложением, то есть практически везде.
Крупные интернет-компании обычно предоставляют (платно или бесплатно) доступ к API своих сервисов.
Где применяют API
Сейчас будет несколько абстрактных примеров просто для понимания сути.
Конкретные примеры работы с API я разбираю в учебнике
Пример №1:
Если Вы хотите разместить на своём сайте яндекс-карты Вам не нужно устанавливать программы от Яндекса, достаточно послать несколько запросов и Яндекс передаст необходимую информацию.
Пример №2:
Предположим, что Вы создали сайт vk2.com. Вы хотите, чтобы вебмастера могли добавить на свои сайты возможность комментировать записи используя учётную запись vk2, но раскрывать или раздавать свой код не хотите.
Чтобы обойти эту проблему Вы выкладываете в публичном доступе правила, по которым вебмастера могут обращаться к vk2, чтобы получить комментарии.
Формат этих сообщений это обычно либо JSON либо XML. О них мы поговорим позже.
Повторим для закрепления сути: Смысл в том, что сайт написанный на любом языке, поддерживающем HTTP запросы, не посылает на сервер никаких PHP/C/Python команд, а общается ним с помощью запросов, описанных в API.
Если вам интересен реальный пример работы с API рекомендую статью Работа с API GitHub
Endpoint
Адрес, на который посылаются сообщения называется Endpoint.
Обычно это URL (например, название сайта) и порт. Если я хочу создать веб сервис на порту 8080 Endpoint будет выглядеть так:
Если моему Web сервису нужно будет отвечать на различные сообщения я создам сразу несколько URL (interfaces) по которым к сервису можно будет обратиться. Например
https://andreyolegovich.ru:8080 /resource1/status
https://andreyolegovich.ru:8080 /resource1/getserviceInfo
https://andreyolegovich.ru:8080 /resource1/putID
http://andreyolegovich.ru:8080 /resource1/eventslist
https://andreyolegovich.ru:8080 /resource2/putID
…
Как видите у моих эндпойнтов (Enpoints) различные окончания. Такое окончание в Endpoint называются Resource, а начало Base URL.
Такое определение Endpoint и Resource используется, например, в SOAP UI для RESTful интерфейсов
Endpoint = Base URL + Resource
Понятие Endpoint может использоваться в более широком смысле. Можно сказать, что какой-то определённый роутер или компьютер является Endpoint. Например, в понятии Endpoint Management под Endpoint имеют в виду конечное устройство. Обычно это понятно из контекста.
Также следует обратить внимание на то, что понятие Endpoint выходит за рамки RESTful и может использовать как в SOAP так и в других протоколах.
Термин Resource также связан с RESTful, но в более широком смысле может означать что-то другое.
На программистском сленге Endpoint иногда называют ручкой.
Спецификация
После того все эти интерфейсы созданы, их необходимо описать. Нужен документ из которого будет понятно
Этот документ должен быть доступен программистам с обеих сторон, иначе они просто не смогут договориться и реализовать работающий Web сервис.
HTTP методы
Вернёмся к первому пункту списка, а именно к тому, что такое методы.
В протоколе HTTP предусмотрено несколько способов отправить запрос на один и тот же Endpoint.
Про их свойства можно почитать здесь.
Когда мы знаем какие методы с какими Enpoint можно использовать составить запросы не составит труда.
GET http://andreyolegovich.ru:8080 /resource1/status
GET http://andreyolegovich.ru:8080 /resource1/getserviceInfo
PUT http://andreyolegovich.ru:8080 /resource1/putID
GET http://andreyolegovich.ru:8080 /resource1/eventslist
POST http://andreyolegovich.ru:8080 /resource1/eventslist
PUT http://andreyolegovich.ru:8080 /resource2/putID
…
Таким образом простейший запрос состоит из метода и Enpoint
Request = Method + Endpoint
Пример API
Чтобы узнать количество велосипедистов в городе нужно отправить GET запрос на https://topbicycle.ru:/bicyclists/$город
GET https://topbicycle.ru /bicyclists/helsinki
Получив такой запрос сайт вернёт число велосипедистов в Хельсинки.
Попробуйте вставить эту строку в браузер.
Это очень простые уроки для самых начинающих. Буду рад любым отзывам и предложениям в комментариях.
Тестирование API без документации
Если Вам по какой-то причине предстоит проделать эту неблагодарную работу, определетесь, насколько всё плохо. Какая у Вас есть информация об объекте тестирования.
Известно ли какие порты для Вас открыты? Знаете ли Вы нужные endpoints?
Сканирование портов
Перебор запросов
Если Вам известен нужный порт и соответствующий endopoint переберите все возможные HTTP методы. Начните с наиболее очевидных:
В худшем случае, когда ни порт ни endpoints неизвестны Вам, скорее всего придётся перебирать все открытые порты и генерировать endpoints, которые подходят по смыслу.
Разработчики обычно не особо заморачиваются и закладывают минимально-необходиму информацию. Так что включите воображение и попробуйте придумать endpoints опираясь на бизнес логику и принятые в Вашей компании стандарты.
Если ни endpoints ни бизнес логика Вам неизвестны, то у меня есть подозрение, что Вы тестируете API с не самыми хорошими намерениями.
Инструменты для тестирования
Существует множество инструментов для тестирования. Здесь Вы можете познакомиться с одними из самых популярных: Python и SOAP UI.
О работе с REST API на Python вы можете прочитать в статье «REST API с Python»
Стратегия тестирования REST API: что именно вам нужно тестировать?
Общедоступный API, ориентированный на клиента, который делают открытым для конечных пользователей, сам по себе становится продуктом. Если он сломается, это подвергнет риску не только одно приложение, но и целую цепочку бизнес-процессов, построенных вокруг него.
Знаменитая пирамида тестов Майка Кона помещает тесты API на сервисный уровень (интеграционный), что предполагает, что около 20% или более всех наших тестов должны быть сосредоточены на уровне API (точный процент зависит от наших потребностей).
 Пирамида тестов
Пирамида тестов
Когда у нас уже есть прочный фундамент из модульных тестов, охватывающих отдельные функции, тесты API обеспечивают более высокую надежность. Они проверяют интерфейс, более близкий к пользователю, но не имеют недостатков тестов пользовательского интерфейса.
Стратегия тестирования API
Основными задачами функционального тестирования API являются:
гарантировать, что реализация API работает в соответствии со спецификацией требований (которая позже становится нашей документацией по API).
предотвратить регрессий между написанным кодом(merge) и релизом.
эндпоинты правильно именованы;
ресурсы и их типы правильно отражают объектную модель;
нет отсутствующей или дублирующей функциональности;
отношения между ресурсами правильно отражаются в API.
Если у вас общедоступный API, ориентированный на клиента, такое тестирование может быть вашим последним шансом убедиться, что все требования соглашения выполнены. После публикации и использования API любые внесенные вами изменения могут внести ошибки в код клиента.(Конечно, когда-нибудь вы сможете опубликовать новую версию API (например, /api/v2 /), но даже в этом случае обратная совместимость скорее всего будет обязательной).
Итак, какие аспекты API мы должны протестировать?
После того как мы проверили соглашение API, мы можем поразмышлять о том, что тестировать. Независимо от того, думаете ли вы об автоматизации тестирования или ручном тестировании, наши функциональные тест-кейсы имеют одинаковый набор тестовых действий. Они являются частью более широких категорий тестовых сценариев и их можно разделить на три потока тестирования.
Этапы тестирования API
Каждый тест состоит из тестовых шагов. Это отдельные атомарные действия, которые тест должен выполнять в каждом потоке тестирования API. Для каждого запроса API тест должен будет выполнить следующие действия:
Проверьте корректность кода состояния HTTP. Например, создание ресурса должно возвращать 201 CREATED, а запрещенные запросы должны возвращать 403 FORBIDDEN и т. Д.
Проверьте полезную нагрузку ответа. Проверьте правильность тела JSON, имен, типов и значений полей ответа, в том числе в ответах на ошибочные запросы.
Проверьте заголовки ответа. Заголовки HTTP-сервера влияют как на безопасность, так и на производительность.
Проверьте правильность состояния приложения. Это необязательно и применяется в основном к ручному тестированию или когда пользовательский интерфейс или другой интерфейс можно легко проверить.
Проверьте базовую работоспособность. Если операция была завершена успешно, но заняла неоправданно много времени, тест не пройден.
Категории тестовых сценариев
Наши тест-кейсы делятся на следующие общие группы тестовых сценариев:
Основные позитивные тесты (прохождение успешного сценария по умолчанию)
Расширенное позитивное тестирование с дополнительными параметрами
Негативное тестирование с валидными входными данными
Негативное тестирование с недопустимыми входными данными
Тесты безопасности, авторизации и доступности (которые выходят за рамки этой статьи)
Тестирование успешного сценария по умолчанию проверяет базовую функциональность и критерии приемки API. Позже мы расширим положительные тесты, чтобы включить дополнительные параметры и дополнительные функции.
Тестовые потоки
Давайте разделим и обозначим три вида потоков тестирования, которые составляют наш план тестирования:
Мы выполняем запросы через API и проверяем действия через пользовательский интерфейс веб-приложения и наоборот. Цель этих потоков проверки целостности состоит в том, чтобы гарантировать, что, хотя на ресурсы влияют различные механизмы, система по-прежнему поддерживает ожидаемую целостность и согласованный поток данных.
Пример API и тестовая матрица
Теперь мы можем отобразить все в виде матрицы и использовать ее для написания подробного плана тестирования (для автоматизации тестирования или ручных тестов).
Предположим, что подмножеством нашего API является конечная точка /users, которая включает следующие вызовы API:
Шаг 2 «Конечные точки и методы (Описание API)»
Конечные точки указывают, как получить доступ к ресурсу, а метод указывает разрешенные взаимодействия (такие как GET, POST или DELETE) с ресурсом.
Один и тот же ресурс обычно имеет множество связанных конечных точек, каждая из которых имеет разные пути и методы, но возвращает различную информацию об одном и том же ресурсе. Конечные точки обычно имеют краткие описания, похожие на общее описание ресурса, только еще короче. Кроме того, конечная точка показывает только конечный путь URL ресурса, а не базовый, общий для всех конечных точек, путь.
Примеры конечных точек
Вот пример конечной точки ресурса User API Instagram
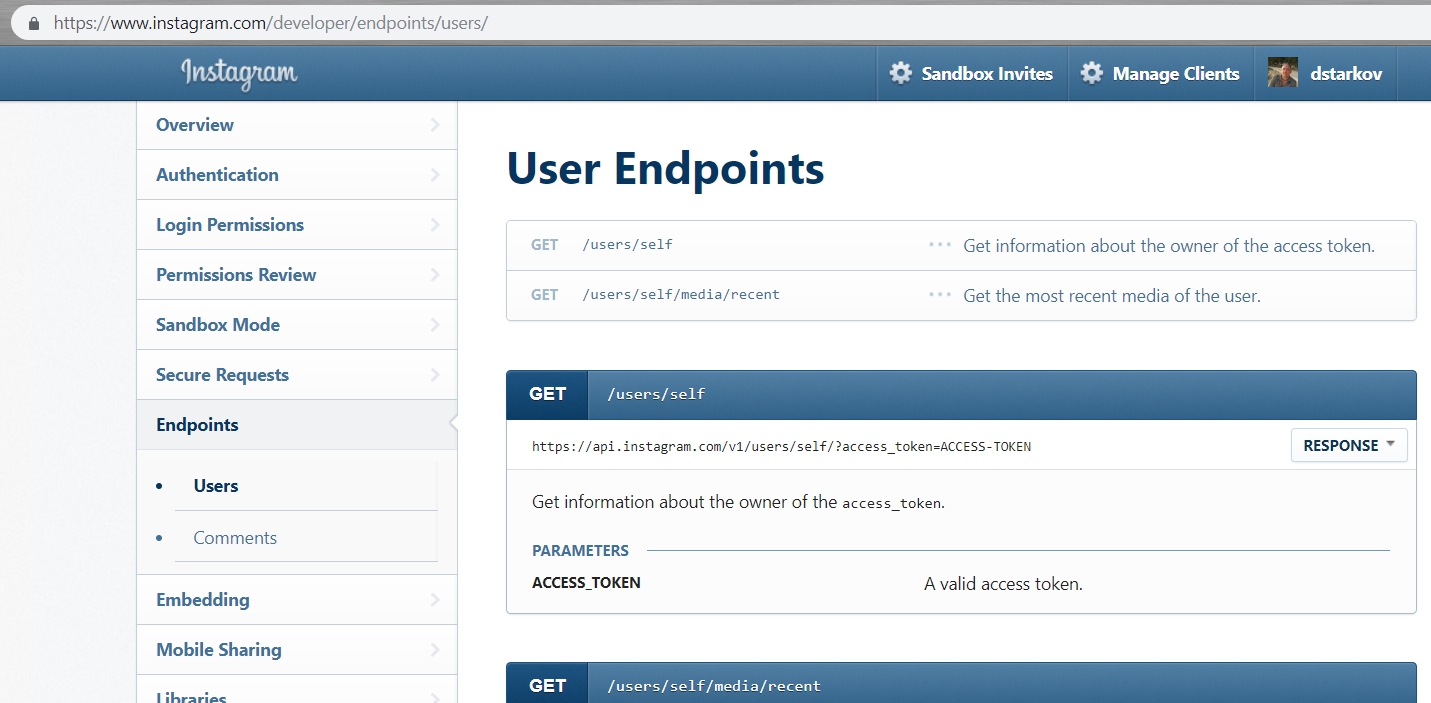
Конечная точка обычно выделяется стилизованным образом для придания ей более визуального внимания. Большая часть документации строится вокруг конечной точки, поэтому, может, имеет смысл визуально выделить конечную точку в нашей документации.
Конечная точка, возможно, является наиболее важным аспектом документации API, потому что она является тем, что разработчики будут реализовывать для выполнения своих запросов.
Представление параметра path при помощи фигурных скобок
Параметры path в конечных точках, представляют в фигурных скобках. Например, вот пример из API Mailchimp:
По возможности, параметр path выделяют другим цветом:
Фигурные скобки для параметров path являются условием, понятным пользователям. В приведенном выше примере почти ни одна конечная точка не использует фигурные скобки в синтаксисе фактического пути, поэтому
Вот пример из API Facebook, где параметр path выделен цветом для его легкой идентификации:
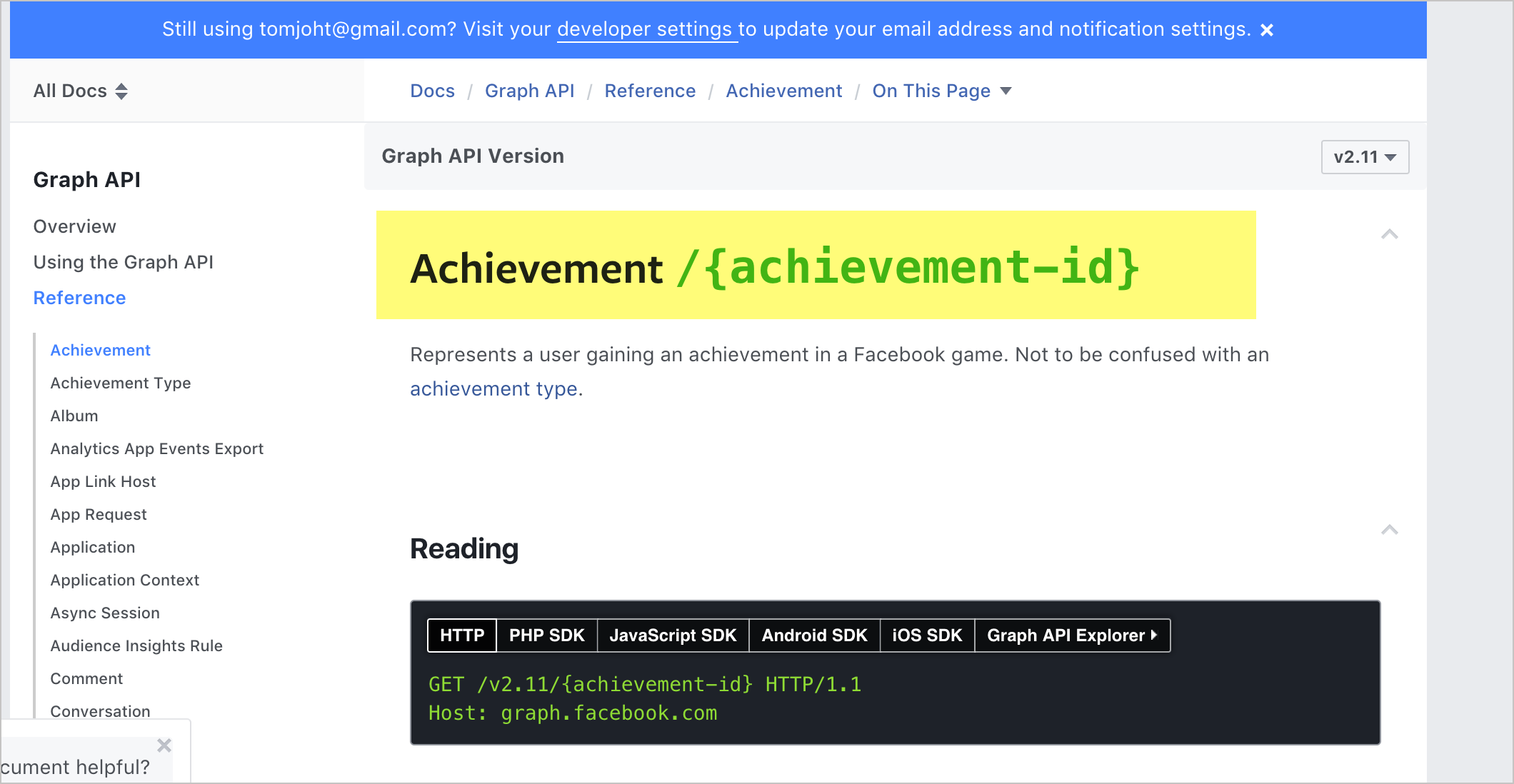
Для выделения параметров, при их описании в документации Facebook, используется зеленый цвет, который помогает пользователям понять их значение.
Параметры path не всегда выделяются уникальным цветом (например, некоторым может предшествовать двоеточие), но, как бы то ни было, нужно убедиться, что параметр path легко идентифицируется.
Перечисляем методы конечной точки
Для конечной точки обычно перечисляют методы (GET, POST и т. Д.). Метод определяет работу с ресурсом. Вкратце, каждый метод выглядит следующим образом:
См. Request methods в статье Wikipedia по HTTP для получения дополнительной информации. (Существуют дополнительные методы, но они редко используются.)
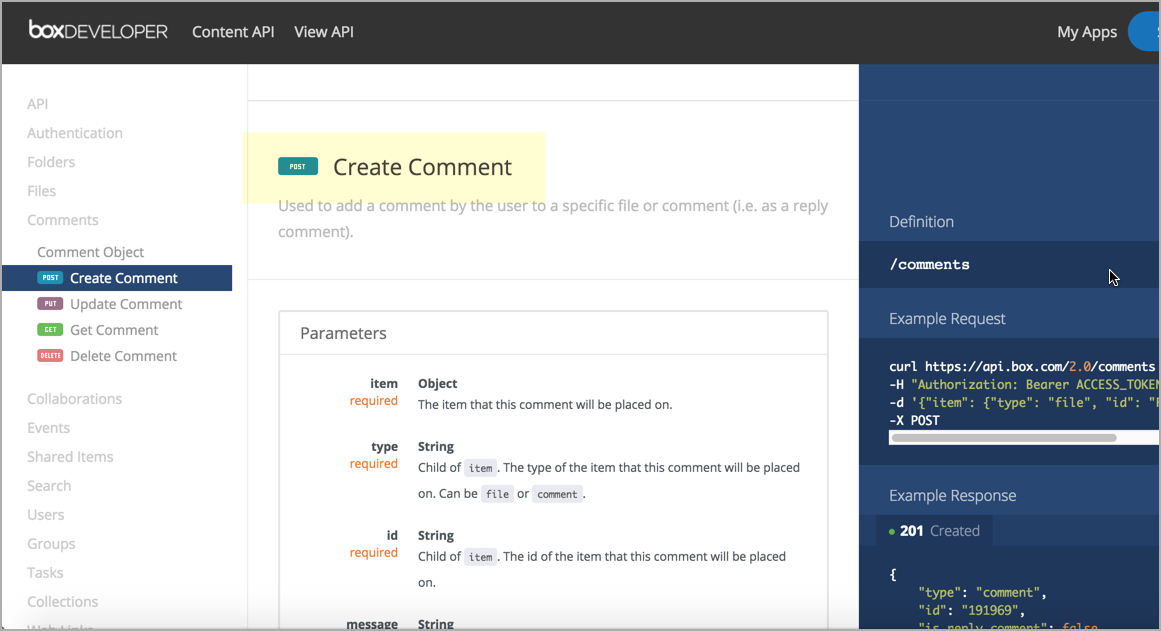
Поскольку о самом методе особо говорить нечего, имеет смысл сгруппировать метод с конечной точкой. Вот пример из Box API:
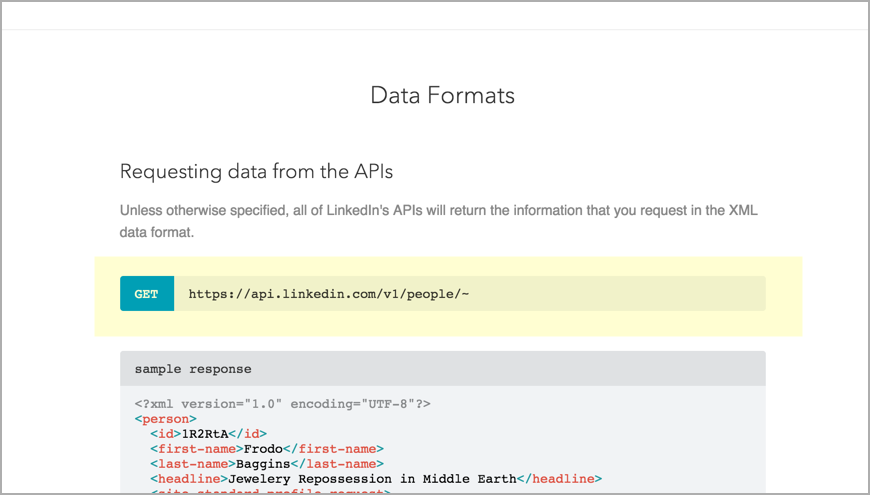
А вот пример API LinkedIn:
Конечная точка показывает только конечный путь
Когда мы описываем конечную точку, мы указываем только конечный путь (отсюда и термин «конечная точка»). Полный путь, который содержит как базовый путь, так и конечную точку, часто называют URL-адресом ресурса.
Как сгруппировать несколько конечных точек одного ресурса
Еще стоит обращать внимание при документировании конечных точек и методов, как группировать и перечислять конечные точки, особенно если у нас много конечных точек для одного и того же ресурса. В Примерах описания ресурсов мы рассмотрели различные API. Многие сайты документации используют различные схемы группировки или перечисления каждой конечной точки ресурса, поэтому не будем возвращаться к тем же примерам. Группируйте конечные точки таким образом, осмысленно, например, по методу или по типу возвращаемой информации.
Если конечные точки в основном совпадают, объединение их на одной странице может иметь смысл. Но если они в значительной степени уникальны (с разными ответами, параметрами и сообщениями об ошибках), разделение их на разные страницы, вероятно, лучше (и проще в управлении). Опять же, создав более сложный дизайн сайта, мы можем сделать большую информацию доступной для навигации на той же странице.
Как ссылаться к конечным точкам в инструкциях
Как ссылаться к конечным точкам в разделе API в руководствах и другом безадресном контенте? Ссылка на конечную точку /aqi или на конечную точку /weatherdata не имеет большого значения. Но для более сложных API-интерфейсов использование конечной точки для описания ресурса может оказаться непростым делом.
В одной компании URL-адреса конечных точек ресурса Rewards выглядели так:
А Rewards в контексте Missions выглядели вот так:
Сказать, что можно использовать ресурс Rewards, не всегда было достаточно конкретно, потому что было несколько Rewards и конечных точек Missions.
Чем длиннее конечная точка, тем более громоздкой становится ссылка. Эти виды описаний будут чаще встречаться в концептуальных разделах вашей документации. Как правило, нет четкого правила, как ссылаться на громоздкие конечные точки. Смысловой подход нашего API определим самостоятельно.
Конечная точка API surfReport
Давайте создадим описание «Конечные точки и методы» для нашего вымышленного API Surfrefport. Вот пример:
Следующие шаги
Теперь, когда мы описали ресурс и перечислили конечные точки и методы, пришло время заняться одной из самых важных частей API: раздел “Параметры”.
Базовые знания REST API
Каждое понятие ниже играет важную роль в понимании WordPress REST API. Давайте ознакомимся с понятиями и фразами, которые используются в этом руководстве, чтобы иметь представление о чем речь. Подробнее каждое понятие прямо или косвенно рассмотрено в других разделах этого руководства.
Это простой и удобный формат данных, который выглядит как объект в JavaScript, отсюда и название (JavaScript Object Notation). Пример JSON формата:
REST получает и отдает JSON. Это позволяет разработчикам создавать, читать и обновлять контент WordPress с клиентского JavaScript или из внешних приложений, написанных на любом языке программирования.
HTTP Клиент (или просто Клиент)
Инструмент, который используется для взаимодействия с REST API. Этот инструмент позволяет создавать HTTP запросы и умеет обрабатывать полученные ответы.
Таким инструментом может быть:
Маршруты и Эндпоинты
Разберем URL
Запрос к корневому маршруту
Маршрут без ЧПУ
Пространство имён
Пространство имен нужно, чтобы сделать название маршрута уникальным и таким образом избежать конфликтов при создании множества маршрутов разными плагинами/темами.
Еще одно преимущество использования пространства имён — это то, что Клиенты смогут обнаружить ваше произвольное API. Список пространств отображается по главному запросу на корневой URL REST API:
При регистрации произвольных маршрутов настоятельно рекомендуется указывать пространство имени!
Что если не указать пространство имени?
Сокращение от Create, Read, Update, Delete. Это короткое название всех видов операций маршрута, которые он позволяет делать: читать, создавать, обновлять и удалять что-либо (ресурс).
Ресурс
Ресурсы — это сущности в WordPress — это Посты, Страницы, Комментарии, Юзеры, Элементы таксономий (термины) и т.д.
WP-API позволяет HTTP-клиентам выполнять CRUD операции с ресурсами (create, read, update, delete).
Пример того, как REST API взаимодействует с ресурсами:
Путь к ресурсу
Запрос
Один из основных классов в структуре WordPress REST API это WP_REST_Request. Этот класс используется для получения информации из запроса.
Запрос может быть отправлен удаленно через HTTP или внутренне из PHP. Объекты WP_REST_Request создаются автоматически при каждом запросе HTTP к маршруту. Данные, указанные в запросе определяют, какой ответ будет получен.
Ответ
Ответ — это данные которые вернутся из API в ответ на запрос. Ответы от конечных точек управляются классом WP_REST_Response. Класс предоставляет разные способы взаимодействия с данными ответа.
Ответы могут возвращать разные данные, в том числе JSON объект ошибки:
В заголовках ответа также указывается его статус код (200, 401). В REST API статус код часто важен, на его основе можно понять что не так с запросом. Подробнее про статус коды смотрите в отдельном разделе.
HTTP Методы
HTTP метод указывается при запросе Клиентом и определяет тип действия, которое Клиент хочет выполнить над ресурсом.
Методы которые используются в WP API:
Не все клиенты поддерживают все эти методы или может быть на сервере установлен фаервол, который запрещает некоторые методы.
Поэтому в WP API есть возможность указать такой метод по-другому:
Схема
Схема в REST API — это полное описание маршрута, оно рассказывает нам о маршруте все:
Под словом «схема» можно понимать разные Схемы. В общем смысле — это Схема маршрута — это общая схема всего маршрута, в которую входят две схемы:
В WP API схема представлена в виде JSON объекта и получить его можно сделав OPTIONS запрос на маршрут. Схема предоставляет машиночитаемые данные, поэтому любой Клиент который умеет читать JSON может понять с какими данными ему предстоит работать.
Рассмотрим пример
Возьмем маршрут /wp/v2/categories и посмотрим его схему:
Схемы эндпоинтов:
В ключе endpoints мы видим «Схемы эндпоинтов», т.е. какие у маршрута есть конечные точки. Их тут две: GET (получит рубрики) и POST (создаст рубрику). И тут же описаны все возможные параметры для этих конечных точек.
Вот код схемы одного эндпоинта из кода выше (этот эндпоинт создает рубрику):
Схема ресурса:
В ключе schema мы видим «Схему ресурса», т.е. все аргументы JSON объекта, которые вернет API в случае удачного CRUD запроса.
Так выглядит схема ресурса (рубрики) из кода выше:
Вот более читаемый вариант схемы ресурса (рубрики) из кода выше:
Контекст в схеме
Контекст — показывает какие поля объекта вернутся в ответе при создании запроса в указанном контексте. Например, при обновлении или создании рубрики вернутся поля соответствующие контексту edit.
Обнаружение
Это процесс выяснения любых деталей о работе с REST API. Например:
Контроллер
Классы контроллеров объединяют отдельные части REST API в единый механизм. В них должны создаваться маршруты, они должны обрабатывать запросы, генерировать ответы API и описывать схему ресурса.
Подробнее читайте в разделе Классы контроллеров!
Где логика?! История тестирования одного микросервиса
Эта статья — расшифровка доклада Дениса Кудряшова, QA-инженера Leroy Merlin, с конференции QA Meeting Point 2020.
Денис рассказал, как столкнулся со сложной логикой, реализованной в сервисе, применил подход Control Flow Testing, и что из этого вышло. Из текста вы узнаете, можно ли использовать этот подход для синхронных или для асинхронных логических схем, какие нюансы есть у каждого кейса, а также почему моки и Control Flow Testing — идеальное сочетание.

«Небольшой» эндпоинт и первые нюансы
Некоторое время назад мой коллега попросил помочь ему в тестировании одного, как он сказал, «небольшого» эндпоинта в микросервисе их команды. Мы залезли в документацию, и я увидел это.
Хотя схема на картинке не из реального проекта, но передает ситуацию почти на 100%. На реальной схеме было большое количество ветвлений и различных вариантов обработки данных. Но это было не главное: я знал, что есть какой-то нюанс, который смутил моего коллегу — так и оказалось.
Во-первых, схема была реализована в системе управления бизнес-процессами. Суть ее заключалась в последовательном вызове эндпоинтов других микросервисов, и в общем-то больше никакой логики реализовано не было. Схема состояла из ряда запросов и небольшой постобработки полученных данных, после чего данные возвращались клиенту.
Во-вторых, обнаружилось, что мы не можем влиять на выбор ветки входными данными. Те данные, которые отправлялись на вход тестируемого микросервиса, могли повлиять только лишь на список возвращаемых параметров. То есть мы могли задать какие-то интересующие нас параметры, они бы вернулись в ответе. Если же их не задавали — тогда возвращался просто дефолтный набор данных. Но на маршрут движения данных по схеме мы никак не влияли. Повлиять могли исключительно ответы связанных сервисов, но на том окружении мы не могли ничего сделать, так как интегрированные сервисы были в зоне ответственности других команд.
Нюансы всплыли, задача ясна, надо подумать, как это протестировать. Первый и самый основной вопрос: а кто уже делал подобное до меня?
Я изучил архитектуру приложения, накидал небольшую схемку и обнаружил, что у нас в системе есть как минимум два таких места. Первое — это микросервис, о котором я рассказал ранее (Middle слой). Вторым был микросервис на бэкенде, где происходила совсем чёрная магия.
Если в первой схеме мы могли отслеживать по ответу хотя бы параметры, то в сервисе на бэкенде обработка запроса происходила в полностью асинхронном режиме, и единственный ответ, который возвращал нам сервис, заключался в информировании того, стартанул он или нет. Всё. О результатах завершения процесса мы не уведомлялись никоим образом.
Допустим, пусть схема асинхронная. Но, может быть, коллеги уже нашли какое-то решение? К сожалению, на тот момент команда микросервиса тоже билась над этой задачей. Что ж, решения нет, нужно гуглить.
Чтобы гуглинг был эффективным, я решил понять, с чем же мы вообще имеем дело и дополнительно изучить возможные нюансы задачи.
То, что мы тестируем, выглядит как API. То есть такая логика может быть зашита в любом микросервисе. В нашем случае, если мы запрашиваем какой-то сервис, то отправляем запрос, происходит магия обработки данных по некоей логической схеме и возвращается ответ. И если мы отправляем такой же запрос в асинхронную схему, то нам как минимум возвращается ответ о том, что процесс стартанул либо нет. То есть весь тест условно можно свести к запросу и анализу ответа и каких-то дополнительных данных. Это уже лучше. Но опять же — есть нюанс. Одинаковый результат можно достигнуть совершенно разными ветками схемы. И вот здесь возникает вопрос: как нам эти пути однозначно определить (проверить-то нужно все варианты)? Пометим себе этот вопрос и идём дальше.
Большим подспорьем стало то, что мы знаем конкретную логику выполнения запроса. То есть у нас перед глазами есть схема, она часть документации, и мы можем по ней определить какие-то условия, при которых запрос и данные будут обрабатываться определённым образом по определённому пути.
Попробуем формализовать и обобщить задачу и приведём какую-то абстрактную схему, для простоты — с одним ветвлением.
Схема начинает работать, когда на вход подают данные, далее происходит ветвление по определённому условию. Таким образом, зная условия ветвления, мы можем выделить две ветки движения данных. То есть, для более сложных схем возможно выделить любое количество веток, в зависимости от количества ветвлений. В данной схеме это всего лишь две ветки, которые показаны красными и зелёными стрелочками. На первый взгляд — достаточно просто.
Данная методика называется Control Flow Testing и заключается в том, что мы как бы разделяем нашу логическую схему на пути обработки данных, и подбором входных данных и управлением ответами от интегрированных сервисов формируем прохождение наших данных по тестируемой ветке логической схемы. Вроде бы просто. Но опять же — есть нюанс. Имеется как минимум две схемы работы, одна асинхронная, другая синхронная. Можем ли мы применить подход Control Flow Testing для обеих схем?
Начнем проверку нашей гипотезы с синхронной схемы.
Control Flow Testing для синхронных схем
Вот пример того, как может выглядеть реальная схема в нашей документации. Она полностью синхронная, здесь есть несколько запросов в интегрированные микросервисы. Первый запрос в эндпоинт /start, далее — запросы в сервис 1 и сервис 2. Движение данных у нас зависит от ответов микросервисов. В принципе схема достаточно информативная, но для удобства восприятия вариантов движения данных, ее можно разбить её по веткам и представить в табличном виде.
Вот такая простая табличка получилась у меня. Мы берём проверку на узле ветвления за шаг, движемся от проверки к проверке и таким образом описываем путь данных. «+» и «–» обозначают True/False соответственно, пустое значение – ветвление недоступно в данной ветке. В принципе ничего сложного. Единственное, что мы должны учесть в нашем примере — это запрос в сервис 2, но о том, как это сделать правильно, расскажу ниже.
В процессе тестирования обнаружился интересный эффект от создания такой таблички — помимо формализации веток схемы мы проверяем повторяющиеся проверки. Например, несколько проверок одного и того же параметра. И если у нас есть повторяющиеся проверки, то как правило это говорит о недостаточной проработке системы и, в частности — логической схемы. Когда мы устраняем дублирование, то у нас остаются только неповторяющиеся проверки параметров, и мы можем говорить о том, что схема похожа на правду и работает без оверинжиниринга и явных логических ошибок.
То же самое касается повторяющихся веток. Такая ситуация возможна в случае, когда, например, после какого-то определённого ветвления данные не изменяются, после чего ветки вновь объединяются в единый поток. Я остановлюсь на этом более подробно, а пока примем, что отсутствие повторяющихся веток является критерием качественно спроектированной схемы.
И так же мы можем при помощи таблички проверить коды ошибок, возвращаемых сервисом. Это необязательно, и в наших тестах мы не всегда это используем, но удобно в случае, например, когда у нас разные ветки могут возвращать одну и ту же ошибку. В этом случае мы можем проверять дополнительно ещё и коды ошибок, и заносить их в нашу табличку, чисто в качестве информации.
Какие же нюансы у нас возникают при попытке применить Control Flow Testing для анализа схемы? Опытным путем было выяснено, что табличку надо составлять на самом первом этапе, то есть на этапе проектирования фичи или сервиса. Мы столкнулись с тем, что при составлении таблицы и дальнейшей проверке ветвлений были получены результаты, которые вынудили команду переделать схему. У нас были дополнительные ненужные проверки, очень-очень много дублей. Всё это разработчикам пришлось выпилить, из-за чего процесс затянулся. Поэтому таблички лучше всё-таки предоставлять в самом начале проектирования фичи.
Пример таблицы с ветками схемы, возвращающими только ошибки (дополнительный материал, не было в презентации)
Следующий момент: иногда нам необходимо проверить последний вызов в схеме (или проверить его отсутствие — см. рисунок выше). Для чего это делается?
Если мы посмотрим на схему, то вызов в сервис-2 (самый правый снизу) происходит у нас как бы в информативном режиме для схемы, и после него никаких ветвлений нет. Соответственно, данный вызов может повлиять либо на состояние системы (и мы его должны будем проверить, чтобы удостовериться, что вызов был или не был произведен), либо на возвращаемые данные. В последнем варианте нам необходимо дополнительно проверить вернувшиеся данные.
Control Flow Testing для асинхронных схем
Ок, вроде бы с синхронной схемой разобрались. Что же с асинхронной?
С асинхронной схемой ситуация примерно следующая: в документации схемы обычно описываются в BPMN виде. Это связано с нюансами реализации и используемыми инструментами.
Выделенная часть схемы — это цепочка запросов в сервис 5, которая является циклической. При обработке представленной схемы у нас может возникнуть ситуация, когда данные пойдут по пути положительного выполнения задачи, и схема достигнет статуса «готово». Но при этом с начальный момент времени схема зациклится и повиснет в статусе «ожидает старта». Такое очень даже возможно, а значит — нам нужно каким-то образом учесть эти циклы.
Что важно при этом помнить? Первое: циклы — это не блоки ветвления. Они используют блоки, но если мы посмотрим на выделенный кусок схемы и уберём проверку тайм-аута, то у нас получится просто ровная веточка, при движении по которой статус задачи изменяется от «в работе» до «готово».
Если мы немного доработаем схему и переставим этот цикл в виде блока для каждой отдельной ветки, и для положительной, и для ошибочной (то есть когда мы попадаем в статус «ошибка»), то у нас получаются две обычные ветки.
Действительно, когда мы готовим таблицу для данной схемы, мы просто не учитываем циклические блоки, так как они нам не нужны для анализа веток.
Однако циклы будут нам очень полезны при составлении тест-кейса. В тест-кейсе проверяется статус задачи, статус допускает несколько вариантов. Если мы попадаем в вариант, который у нас представлен циклической частью схемы, то дописываем какие-то дополнительные действия по проверке статуса схемы.
Что ещё интересного в тест-кейсе с асинхронной работой? Здесь мы в некоторых случаях вынуждены эмулировать действия сторонних сервисов, делать запросы в тестируемый микросервис или кидать сообщения в очередь RabbitMQ или Kafka от имени интегрированных микросервисов. То есть нам придётся в самом тесте эмулировать эти сервисы. Но в целом тест-кейс похож на вариант с синхронной схемой.
Перейдём к нюансам асинхронных схем.
Ответ сервиса нам, как правило, возвращает 200, 201, 202 — то есть ответы группы Ок (2хх). В этом случае ответ абсолютно неинформативен, мы только знаем, что процесс запущен, и приходится дополнительно проверять через методы сервиса, в каком статусе он находится. Соответственно, в проверяемой ветке статус может иметь различные значения. Нам необходимо учитывать такую инвариантность статуса при проведении теста и правильно ее обрабатывать. В противном случае тест просто может упасть, не дождавшись смены статуса на нужный.
Приходится имитировать интегрированные сервисы. Как я говорил выше, в тесте может потребоваться имитация работы сторонних сервисов и выкидывание каких-то сообщений в очереди или запросов к тестируемому сервису.
Вывод: мы можем применить Control Flow Testing к обеим вариантам логических схем.
Правила составления таблиц
Я расскажу, какие же правила мы придумали у себя в команде для того, чтобы более эффективно работать со схемами и их тестировать.
Первое: в таблицу вносятся все узлы ветвлений по порядку. Это значит, что мы берём логическую схему, и, в зависимости от формата, проходим ее либо слева направо, либо сверху вниз. И записываем в табличку все узлы, в которых происходит выбор того или иного пути дальнейшей обработки данных.
Далее мы можем разделить таблички по ответу сервиса, например, на ветки без ошибок и с ошибками. Это позволяет отследить логику как обработки исключительных ситуаций, или детально проанализировать работу позитивных сценариев.
Также отдельной строкой в таблицу добавляется запрос при условии, что после него нет ветвления. Здесь нам необходимо проверить, что запрос вот в этот сервис действительно был, с определёнными параметрами и ответом.
В таблицу не вносятся циклы. Они нам мешают сосредоточиться на ветвлении, которое разделяет сами ветки, соответственно мы их можем представить просто в виде какого-то блока кода, который не имеет к ветвлению никакого отношения.
В тест-кейсе можем добавить обработку дополнительных вариантов, например статуса задач. Следуя этим правилам, мы получаем достаточно эффективный инструмент для контроля наших логических схем. И самое главное: мы можем эффективно использовать эту таблицу при составлении тест-кейсов и настройки моков.
Итак, мы используем подход Control Flow Testing, используем табличное представление схемы, но это не все — для теста нам потребуются моки. Зачем? Чтобы ответить на этот вопрос, давайте ещё раз взглянем на схему.
Для тестирования определенной ветки нам нужно заставить сервис отправлять нужные нам данные. Как мы это можем сделать? Вариант №1 — мокировать этот сервис и уже в заглушке отправлять нужные нам данные.
Вариант №2: запрос в сервис 1, который также возвращает какие-то данные. Однако вернувшиеся данные в схеме не анализируются, проверяется только ответ сервиса. То есть если бы у нас был 404 not found, мы бы пошли по веточке с запросом в сервис 2, иначе — тестируемый сервис вернул бы некоторые данные и положительный ответ. При мокировании важен только ответ сервиса, возвращаемые данные не важны.
И вариант № 3, когда мы не анализируем вообще ответ сервиса, но при этом запрос у нас есть и каким-то образом нам нужно отлавливать момент запроса вот в этот сервис, либо отсутствие запроса в этот сервис. Здесь возвращаемые заглушкой данные также не важны.
Как использовать моки
Если мы посмотрим на табличку с уже известными ветками и допустим, что нам потребовалось составить тест-кейс для ветки № 3, очень удобно использовать те данные, которые у нас уже имеются. Что у нас есть? Есть запрос в эндпоинт /start, помеченный плюсиком. В блоке «проверка ответа» нас интересует, чтобы сервис возвращал какой-то код ответа в теле, равный двум. В этом случае мы попадаем в ветку 3. Но нам этого недостаточно, нам необходимо ещё поставить мок для сервиса 2. Соответственно, в тесте мы проверим, что у нас был запрос в этот сервис. Потому как схема, может, например, быть неактуальной. Команда доработала какие-то фичи, что-то сделала и запроса в сервис может не быть. Нам этот момент необходимо выяснить, мы вешаем туда мок и в тесте проверим, что запрос в сервис 2 действительно был.
Таким образом мы можем настроить моки под каждую ветку. И вот что интересно: для каждой ветки комбинация моков и возвращаемых параметров будет индивидуальна. При помощи комбинации входных данных и моков мы можем однозначно задать нужную ветку обработки данных. И если в данном случае, например, для ветки 3 мы не устанавливаем мок для запроса в сервис 1, а у нас по каким-то причинам ветка пошла именно по этому пути, то тест однозначно свалился, потому что мок-сервер ничего нам не ответит и что-то пойдёт не так и явно вывалится с ошибкой.
Настройка моков
Какие есть нюансы настройки моков?
Первое — это уникальные настройки для каждой ветки. То есть мы настраиваем не просто мок, мы также настраиваем и тело ответа (не во всех случаях, см. примеры выше).
Далее — мы имеем как минимум два варианта для настройки мок-сервера.
Первый вариант, который мы естественно сразу же попробовали, был вариант с параллельными тестами. Когда у нас поднимался стационарный мок-сервер, мы его планировали использовать для регресса, закидывали туда преднастройки для разных веток, и всё у нас должно было, по идее, замечательно работать. Почему это не взлетело, расскажу чуть позже.
Второй вариант настройки — когда мы настраиваем комбинации непосредственно перед запуском теста — то, к чему мы пришли после.
Возвращаемся к параллельному запуску тестов. Здесь есть нюанс: иногда наши схемы не позволяют, запускать все варианты веток в параллели. Это может случиться из-за невозможности настройки ветки в зависимости от входных данных (как было в нашем случае). При отправке GET-запроса по запуску какой-то асинхронной схемы, мы можем не передавать никаких входных данных и, соответственно, никак не можем эти данные пробросить куда-то дальше на наши моки, и не сможем запустить тесты параллельно. Поэтому иногда мы вынуждены заниматься настройкой комбинаций непосредственно перед тестом. И в общем-то, это не плохо.
Основное достоинство настройки моков непосредственно в тесте заключается в том, что мы не зависим от входных данных и перед каждым тест-кейсом у нас очищены и определённым образом настроены мок-серверы. Мы точно знаем, какие эндпоинты у нас есть на заглушке, а каких нет. Мы сразу видим, на каком запросе у нас тест свалился.
Из недостатков, которые я выделил: «накостылить» аннотацию (этот недостаток относится уже к автоматизации тестирования), когда нам необходимо будет каким-то образом настраивать на лету наши мок-сервера. В ряде случаев это может быть проблемой.
А что же дальше? А дальше автоматизация!
Я вас не буду грузить кодом. Реализовать автоматизацию можно по-разному, в зависимости от инструментов, которые вы предпочитаете.
Однако приведу те схемы, которые мы использовали при создании автотестов. Весь запуск теста у нас будет выглядеть примерно подобным образом.
Здесь представлена схема запуска теста. Мы используем кастомный фреймворк на базе TestNG, и в тесте у нас обрабатываются все NG-шные аннотации. Мы дописали дополнительную аннотацию @Wiremock, которая отвечает за настройку мока. В ней всего два параметра: имя файла с JSON-настройками для мока, и логический параметр — чистить или не чистить мок-сервер (хост мок-сервера задается в настройках окружения). То есть при очистке мы просто удаляем какие-то настройки, которые у нас были до старта теста. Если в этом нет необходимости или у нас гоняются какие-то тесты параллельно, мы их просто оставляем и дописываем либо перезаписываем наши настройки.
Тестирование
Давайте посмотрим также на процедуру тестирования наших логических схем. Ниже представлена блок-схема теста:
Мы отправляем запрос в тестируемый сервис, проверяем его ответ, а также (при необходимости) тело ответа. Здесь нет никакой валидации запросов в мок-сервер, постольку поскольку логические схемы с запросами к интегрируемым сервисам, после которых нет постобработки и ветвлений, у нас достаточно редки. Если это необходимо, мы добавляем дополнительно проверку вот таких «висячих» запросов (был или не был произведен), и на этом тест заканчивается. Здесь проявляется плюс настройки моков перед тестом — нет нужды проверять, куда у нас действительно были запросы, в какие эндпойнты с какими параметрами. Комбинация однозначна — либо тест свалился, если была попытка произвести несипользуемый в ветке запрос, либо по схеме был произведен нужный запрос, тестируемый сервис достучался в мок и получил нужные данные.
Напоследок поговорим про асинхронные схемы.
Здесь единственное отличие только в цикле ожидания (нужен при ожидании требуемого в тесте статуса тестируемого процесса. Ну и дополнительно — имитация действий интегрируемых сервисов. Т.е. выполняем запрос, получаем ответ, проверяем, что у нас схема запустилась. Дальше ждём нужного статуса, имитируем какие-то действия и проверяем, что у нас получилось.
Что же в итоге?
Мы выяснили, что подход Control Flow Testing применим для тестирования логики наших сервисов.
Он замечательно работает как на синхронных, так и на асинхронных схемах, и мы можем его успешно применить.
Отличный инструмент для анализа логических схем — их табличное представление (когда мы разбиваем схемку на ветки и анализируем, каким образом у нас происходит запрос с какими параметрами)
Моки — наше всё, потому как настраивая моки определённым образом, мы можем выбрать конкретную тестируемую ветку и делаем возможным тестирование по методике Control Flow Testing.
Как вы организуете хранение преднастроек моков? Интересует кейс, когда есть одна фишка и очень много комбинаций. Используете ли инструмент генерации или храните в сыром виде?
Сейчас мы тестируем новый инструмент генерации. До этого использовали настройку именно перед тестом. Просто закидывали JSON’ы, которые у нас хранились рядом с тестом. Сейчас делаем генерацию. Что касается преднастроенных моков, мы решили проблему следующим образом: для подобных тестов и микросервисов мы с командой соорудили несколько вариантов сервера в Wiremock с преднастройками. И раскатываются они у нас один раз, автоматически, при деплое. То есть мы какие-то изменения вносим, запускаем джобу в Jenkins, и у нас всё автоматом раскатывается по серверам, никаких настроек менять не нужно. Для тех тестовых окружений, где уже используются эти моки, это проходит бесшовно. Если что-то необходимо добавить, мы просто добавляем это в репозиторий с настройками и раскатываем в Wiremock. Всё. Здесь никакой магии.
Проводите ли функциональное тестирование в живой среде без моков?
Пока да. Единственное, что мы от этого сейчас отказываемся в пользу изолированных сред. Поскольку команда у нас становится всё больше и больше, IT в Leroy Merlin динамично развивается и поддерживать какую-то такую живую среду, хотя бы отдалённо похожую на прод, становится накладно. Это занимает огромное количество времени, поэтому мы уходим в сторону изолированного тестирования. Но пока есть.
Философский вопрос: по ощущениям — насколько это трудозатратный способ? Не слишком ли много времени придётся потратить на составление таблиц?
Производство фичи с разветвлённой логикой без таблиц с исключительно компонентными интеграционными тестами занимает, условно говоря, какой-то период времени — допустим, месяц. При использовании подхода с таблицей, методики Control Flow Testing, мы умудрились как минимум в два раза сократить время выкатки фичи, и я подозреваю, что это не предел. Мы с коллегами сейчас разрабатываем поэтапное проектирование логических схем, где стараемся свести количество итераций по изменению и доработке самой логики до максимум двух. То есть — да, можно ускориться, и это действительно очень и очень помогает в разработке. Мы можем таблицу использовать как документацию в конечном счёте. Здесь очень много нюансов, об этом можно говорить долго, но — да, это действительно ускоряет разработку.
Насколько зависимы будут результаты тестов сервисов при мокировании других сервисов? Вы как-то задаётесь этим вопросом?
Да, мы задаёмся этим вопросом. Сейчас для таких схем мы начинаем применять дополнительно контрактное тестирование.
Сколько времени в среднем уходит на поддержку моков?
Вообще достаточно их один раз настроить, и очень редко они меняются, если только фича дорабатывается. Это если мы говорим о преднастроенных моках. Если мы говорим о моках в тесте (те, которые у нас были просто в виде файликов JSON), здесь в общем то же самое, что и в преднастроенном сервере. Доработки практически не требуют. Если же мы говорим о том, что переходим именно на динамическую конфигурацию моков, то здесь всё проще. Здесь один раз сделал код, и дальше он сам работает.
Насколько затраченное время эквивалентно пользе от таких табличек? Находят ли они баги? Помогают ли они найти баги на этапе проектирования, дают ли уверенность разрабам, что всё ок?
Они дают уверенность нашим тимлидам, что всё ок, это точно. Разрабы, я думаю, тоже довольны. То, о чём я сейчас рассказывал в докладе — реальный кейс, хоть схемы и утрированы. И мы, как только начали применять подобный подход, действительно сходу нашли несколько багов только в одной схеме. С учётом того, что нашем микросервисе порядка 17 эндпоинтов с такими схемами и половина из них сейчас не покрыта вот такими тестами — да, это очень сильно улучшит качество нашего сервиса. И да — на этапе проектирования это позволяет отлавливать баги. Но это, скорее, не баги, а валидация требований, выраженных в логической схеме. Можно так ответить.
Запись видео можно посмотреть здесь:



