Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
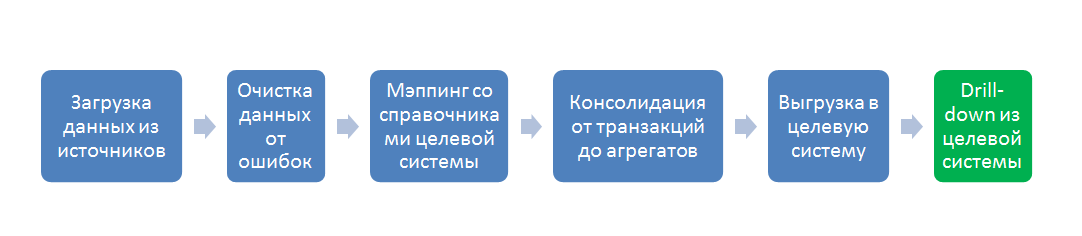
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
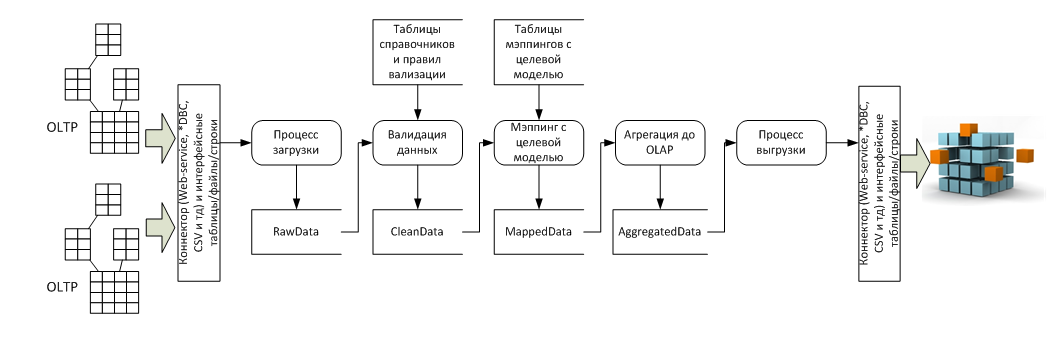
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
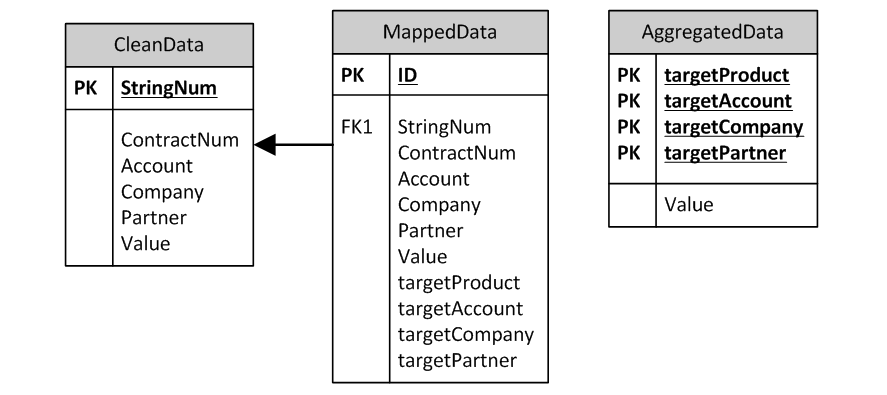
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Расширение файла ETL
Microsoft Event Trace Log Format
Что такое файл ETL?
Формат файла ETL используется для хранения журналов событий, созданных системой Windows. Хранит данные в двоичном формате. Системные журналы создаются приложением Microsoft Tracelog, которое регистрирует события ядра. Он регистрирует такие события как:
Трассировка сеанса также может включать в себя события запуска и завершения работы системы. В файле ETL хранятся данные в двоичном формате и для чтения его предназначены специальные средства диагностики и отчетности. Файлы ETL не должны редактироваться вручную.
В файлах ETL хранятся журналы высокочастотных событий и их описания. Такие файлы могут быть полезны при устранении неполадок в системе. Прежде чем системные evernts записываются в файл ETL, они буферизуются, а затем сохраняются в журнале и сжимаются в двоичном формате для экономии места. Файлы отчетов могут занимать много места, поэтому рекомендуется отслеживать объем доступного пространства на диске, туда, где они записаны. Команда Tracerpt может использоваться для анализа журналов трассировки событий для поиска соответствующей информации с использованием различных фильтров.
Программы, которые поддерживают ETL расширение файла
Программы, обслуживающие файл ETL
Как открыть файл ETL?
Причин, по которым у вас возникают проблемы с открытием файлов ETL в данной системе, может быть несколько. С другой стороны, наиболее часто встречающиеся проблемы, связанные с файлами Microsoft Event Trace Log Format, не являются сложными. В большинстве случаев они могут быть решены быстро и эффективно без помощи специалиста. Мы подготовили список, который поможет вам решить ваши проблемы с файлами ETL.
Шаг 1. Установите Microsoft Event Viewer программное обеспечение
Шаг 2. Убедитесь, что у вас установлена последняя версия Microsoft Event Viewer
 Если проблемы с открытием файлов ETL по-прежнему возникают даже после установки Microsoft Event Viewer, возможно, у вас устаревшая версия программного обеспечения. Проверьте веб-сайт разработчика, доступна ли более новая версия Microsoft Event Viewer. Иногда разработчики программного обеспечения вводят новые форматы вместо уже поддерживаемых вместе с новыми версиями своих приложений. Причиной того, что Microsoft Event Viewer не может обрабатывать файлы с ETL, может быть то, что программное обеспечение устарело. Последняя версия Microsoft Event Viewer должна поддерживать все форматы файлов, которые совместимы со старыми версиями программного обеспечения.
Если проблемы с открытием файлов ETL по-прежнему возникают даже после установки Microsoft Event Viewer, возможно, у вас устаревшая версия программного обеспечения. Проверьте веб-сайт разработчика, доступна ли более новая версия Microsoft Event Viewer. Иногда разработчики программного обеспечения вводят новые форматы вместо уже поддерживаемых вместе с новыми версиями своих приложений. Причиной того, что Microsoft Event Viewer не может обрабатывать файлы с ETL, может быть то, что программное обеспечение устарело. Последняя версия Microsoft Event Viewer должна поддерживать все форматы файлов, которые совместимы со старыми версиями программного обеспечения.
Шаг 3. Настройте приложение по умолчанию для открытия ETL файлов на Microsoft Event Viewer
Если проблема не была решена на предыдущем шаге, вам следует связать ETL файлы с последней версией Microsoft Event Viewer, установленной на вашем устройстве. Следующий шаг не должен создавать проблем. Процедура проста и в значительной степени не зависит от системы
Выбор приложения первого выбора в Windows
Выбор приложения первого выбора в Mac OS
Шаг 4. Проверьте ETL на наличие ошибок
Если вы выполнили инструкции из предыдущих шагов, но проблема все еще не решена, вам следует проверить файл ETL, о котором идет речь. Вероятно, файл поврежден и, следовательно, недоступен.

Если ETL действительно заражен, возможно, вредоносное ПО блокирует его открытие. Немедленно просканируйте файл с помощью антивирусного инструмента или просмотрите всю систему, чтобы убедиться, что вся система безопасна. Если сканер обнаружил, что файл ETL небезопасен, действуйте в соответствии с инструкциями антивирусной программы для нейтрализации угрозы.
2. Убедитесь, что файл с расширением ETL завершен и не содержит ошибок
Вы получили ETL файл от другого человека? Попросите его / ее отправить еще раз. Возможно, файл был ошибочно скопирован, а данные потеряли целостность, что исключает доступ к файлу. Если файл ETL был загружен из Интернета только частично, попробуйте загрузить его заново.
3. Убедитесь, что у вас есть соответствующие права доступа
Иногда для доступа к файлам пользователю необходимы права администратора. Войдите в систему, используя учетную запись администратора, и посмотрите, решит ли это проблему.
4. Убедитесь, что ваше устройство соответствует требованиям для возможности открытия Microsoft Event Viewer
Операционные системы могут иметь достаточно свободных ресурсов для запуска приложения, поддерживающего файлы ETL. Закройте все работающие программы и попробуйте открыть файл ETL.
5. Убедитесь, что у вас установлены последние версии драйверов, системных обновлений и исправлений
Последние версии программ и драйверов могут помочь вам решить проблемы с файлами Microsoft Event Trace Log Format и обеспечить безопасность вашего устройства и операционной системы. Возможно, что одно из доступных обновлений системы или драйверов может решить проблемы с файлами ETL, влияющими на более старые версии данного программного обеспечения.
Вы хотите помочь?
Если у Вас есть дополнительная информация о расширение файла ETL мы будем признательны, если Вы поделитесь ею с пользователями нашего сайта. Воспользуйтесь формуляром, находящимся здесь и отправьте нам свою информацию о файле ETL.
Что такое ETL: как справиться с анализом big data
Крупные предприятия собирают, хранят и обрабатывают разные типы данных из множества источников, таких как системы начисления заработной платы, записи о продажах, системы инвентаризации и других. Эта информация извлекается, преобразуется и переносится в хранилища данных с помощью ETL-систем. Расскажем, что такое ETL, а также какие платные и общедоступные решения для работы с данными есть на рынке.
ETL — что это такое и зачем?
В переводе ETL (Extract, Transform, Load) — извлечение, преобразование и загрузка. То есть процесс, с помощью которого данные из нескольких систем объединяют в единое хранилище данных.
Представьте ритейлера с розничными и интернет-магазинами. Ему нужно анализировать тенденции продаж и онлайн, и офлайн. Но бэкэнд-системы для них, скорее всего, будут отдельными. Они могут иметь разные поля или форматы полей для сбора данных, использовать системы, которые не могут «общаться» друг с другом.
И вот тогда наступает момент для ETL.
ETL-система извлекает данные из обеих систем, преобразует их в соответствии с требованиями к формату хранилища данных, а затем загружает в это хранилище.
ETL — что это на практике, а не на примере?
Современные инструменты ETL собирают, преобразуют и хранят данные из миллионов транзакций в самых разных источниках данных и потоках. Эта возможность предоставляет множество новых возможностей: анализ исторических записей для оптимизации процесса продаж, корректировка цен и запасов в реальном времени, использование машинного обучения и искусственного интеллекта для создания прогнозных моделей, разработка новых потоков доходов, переход в облако и многое другое.
Облачная миграция. Процесс переноса данных и приложений в облако называют облачной миграцией. Она помогает сэкономить деньги, сделать приложения более масштабируемыми и защитить данные. ETL в таком случае используют для перемещения данных в облако.
Хранилище данных. Хранилище данных — база данных, куда передают данные из различных источников, чтобы их можно было совместно анализировать в коммерческих целях. Здесь ETL используют для перемещения данных в хранилище данных.
Машинное обучение. Машинное обучение — метод анализа данных, который автоматизирует построение аналитических моделей. ETL может использоваться для перемещения данных в одно хранилище для машинного обучения.
Интеграция маркетинговых данных. Маркетинговая интеграция включает в себя перемещение всех маркетинговых данных — о клиентах, продажах, из социальных сетей и веб-аналитики — в одно место, чтобы вы могли проанализировать их. ETL используют для объединения маркетинговых данных.
Интеграция данных IoT. То есть данных, собранных различными датчиками, в том числе встроенными в оборудование. ETL помогает перенести данные от разных IoT в одно место, чтобы вы могли сделать их подробный анализ.
Репликация базы данных — данные из исходных баз данных копируют в облачное хранилище. Это может быть одноразовая операция или постоянный процесс, когда ваши данные обновляются в облаке сразу же после обновления в исходной базе. ETL можно использовать для осуществления процесса репликации данных.
Бизнес-аналитика. Бизнес-аналитика — процесс анализа данных, позволяющий руководителям, менеджерам и другим заинтересованным сторонам принимать обоснованные бизнес-решения. ETL можно использовать для переноса нужных данных в одно место, чтобы их можно было использовать.
Популярные ETL-системы: обзор, но коротко
Cloud Big Data — PaaS-сервис для анализа больших данных (big data) на базе Apache Hadoop, Apache Spark, ClickHouse. Легко масштабируется, позволяет заменить дорогую и неэффективную локальную инфраструктуру обработки данных на мощную облачную инфраструктуру. Помогает обрабатывать структурированные и неструктурированные данные из разных источников, в том числе в режиме реального времени. Развернуть кластер интеграции и обработки данных в облаках можно за несколько минут, управление осуществляется через веб-интерфейс, командную строку или API.
IBM InfoSphere — инструмент ETL, часть пакета решений IBM Information Platforms и IBM InfoSphere. Доступен в различных версиях (Server Edition, Enterprise Edition и MVS Edition). Помогает в очистке, мониторинге, преобразовании и доставке данных, среди преимуществ: масштабируемость, возможность интеграции почти всех типов данных в режиме реального времени.
PowerCenter — набор продуктов ETL, включающий клиентские инструменты PowerCenter, сервер и репозиторий. Данные хранятся в хранилище, где к ним получают доступ клиентские инструменты и сервер. Инструмент обеспечивает поддержку всего жизненного цикла интеграции данных: от запуска первого проекта до успешного развертывания критически важных корпоративных приложений.
iWay Software предоставляет возможность интеграции приложений и данных для удобного использования в режиме реального времени. Клиенты используют их для управления структурированной и неструктурированной информацией. В комплект входят: iWay DataMigrator, iWay Service Manager и iWay Universal Adapter Framework.
Microsoft SQL Server — платформа управления реляционными базами данных и создания высокопроизводительных решений интеграции данных, включающая пакеты ETL для хранилищ данных.
OpenText — платформа интеграции, позволяющая извлекать, улучшать, преобразовывать, интегрировать и переносить данные и контент из одного или нескольких хранилищ в любое новое место назначения. Позволяет работать со структурированными и неструктурированными данными, локальными и облачными хранилищами.
Oracle GoldenGate — комплексный программный пакет для интеграции и репликации данных в режиме реального времени в разнородных IT-средах. Обладает упрощенной настройкой и управлением, поддерживает облачные среды.
Pervasive Data Integrator — программное решение для интеграции между корпоративными данными, сторонними приложениями и пользовательским программным обеспечением. Data Integrator поддерживает сценарии интеграции в реальном времени.
Pitney Bowes предлагает большой набор инструментов и решений, нацеленных на интеграцию данных. Например, Sagent Data Flow — гибкий механизм интеграции, который собирает данные из разнородных источников и предоставляет полный набор инструментов преобразования данных для повышения их коммерческой ценности.
SAP Business Objects — централизованная платформа для интеграции данных, качества данных, профилирования данных, обработки данных и отчетности. Предлагает бизнес-аналитику в реальном времени, приложения для визуализации и аналитики, интеграцию с офисными приложениями.
Sybase включает Sybase ETL Development и Sybase ETL Server. Sybase ETL Development — инструмент с графическим интерфейсом для создания и проектирования проектов и заданий по преобразованию данных. Sybase ETL Server — масштабируемый механизм, который подключается к источникам данных, извлекает и загружает данные в хранилища.
Open source ETL-средства
Большинство инструментов ETL с открытым исходным кодом помогают в управлении пакетной обработкой данных и автоматизации потоковой передачи информации из одной системы данных в другую. Эти рабочие процессы важны при создании хранилища данных для машинного обучения.
Некоторые из бесплатных и открытых инструментов ETL принадлежат поставщикам, которые в итоге хотят продать корпоративный продукт, другие обслуживаются и управляются сообществом разработчиков, стремящихся демократизировать процесс.
Open source ETL-инструменты интеграции данных:
Apache Airflow — платформа с удобным веб-интерфейсом, где можно создавать, планировать и отслеживать рабочие процессы. Позволяет пользователям объединять задачи, которые нужно выполнить в строго определенной последовательности по заданному расписанию. Пользовательский интерфейс поддерживает визуализацию рабочих процессов, что помогает отслеживать прогресс и видеть возникающие проблемы.
Apache Kafka — распределенная потоковая платформа, которая позволяет пользователям публиковать и подписываться на потоки записей, хранить потоки записей и обрабатывать их по мере появления. Kafka используют для создания конвейеров данных в реальном времени. Он работает как кластер на одном или нескольких серверах, отказоустойчив и масштабируем.
Apache NiFi — распределенная система для быстрой параллельной загрузки и обработки данных с большим числом плагинов для источников и преобразований, широкими возможностями работы с данными. Пользовательский веб-интерфейс NiFi позволяет переключаться между дизайном, управлением, обратной связью и мониторингом.
CloverETL (теперь CloverDX) был одним из первых инструментов ETL с открытым исходным кодом. Инфраструктура интеграции данных, основанная на Java, разработана для преобразования, отображения и манипулирования данными в различных форматах. CloverETL может использоваться автономно или встраиваться и подключаться к другим инструментам: RDBMS, JMS, SOAP, LDAP, S3, HTTP, FTP, ZIP и TAR. Хотя продукт больше не предлагается поставщиком, его можно безопасно загрузить с помощью SourceForge. CloverDX по-прежнему поддерживает CloverETL в соответствии со стандартным соглашением о поддержке.
Jaspersoft ETL — один из продуктов с открытым исходным кодом TIBCO Community Edition, позволяет пользователям извлекать данные из различных источников, преобразовывать их на основе определенных бизнес-правил и загружать в централизованное хранилище данных для отчетности и аналитики. Механизм интеграции данных инструмента основан на Talend. Community Edition прост в развертывании, позволяет создавать витрины данных для отчетности и аналитики.
Apatar — кроссплатформенный инструмент интеграции данных с открытым исходным кодом, который обеспечивает подключение к различным базам данных, приложениям, протоколам, файлам. Позволяет разработчикам, администраторам баз данных и бизнес-пользователям интегрировать информацию разного формата из различных источников данных. У инструмента интуитивно понятный пользовательский интерфейс, который не требует кодирования для настройки заданий интеграции данных. Инструмент поставляется с предварительно созданным набором инструментов интеграции и позволяет пользователям повторно использовать ранее созданные схемы сопоставления.
Итак, почему стоит отказаться от локальных ETL-решений?
Традиционные локальные ETL чаще всего поставляются в комплекте с головной болью. Например, создаются собственными силами, поэтому могут быстро устареть или не иметь сложных функций и возможностей. Они дороги и требуют времени на обслуживание, а также поддерживают только пакетную обработку данных и плохо масштабируются.
Локальные платформы ETL были важнейшим компонентом инфраструктуры предприятий на протяжении десятилетий. С появлением облачных технологий, SaaS и больших данных выросло число источников информации, что вызвало рост спроса на более мощную и сложную интеграцию данных.
Бесплатный удобный ETL инструмент с открытым кодом на основе Python — фантастика или нет?
Мы давно ищем идеальный ETL инструмент для наших проектов. Ни один из существующих инструментов нас полностью не удовлетворял, и мы попробовали собрать из open-source компонентов идеальный инструмент для извлечения и обработки данных. Кажется, у нас это получилось! По крайней мере, уже многие аналитики попробовали эту технологию и отзываются очень позитивно. Сборку мы назвали ViXtract и опубликовали на GitHub под BSD лицензией. Под катом — рассуждения о том, каким должен быть идеальный ETL, рассказ о том, почему его лучше делать на Python (и почему это совсем не сложно) и примеры решения реальных задач на ViXtract. Приглашаю всех заинтересованных к дискуссии, обсуждению, использованию и развитию нового решения для старых проблем!
Визуализация результатов анализа — это очень важно, но роль загрузки данных нельзя недооценивать. За последние 5 лет, которые я занимаюсь BI (как с технической, так и с бизнесовой стороны), я провел более 500 интервью с клиентами, на которых мы обсуждали задачи и потребности конкретных компаний. И в большинстве из них мои собеседники подчеркивали, что визуализация — это очень нужная и полезная вещь, но самые большие проблемы и трудозатраты возникают при загрузке и очистке данных.
80% времени аналитика уходит на преобразование, очистку, выгрузку и сверку данных
Мы в Visiology в основном работаем с крупными предприятиями, промышленностью и госорганизациями, но в разговорах с коллегами я убедился, что проблемы везде одни и те же. Аналитики могут уделить анализу и визуализации только 20% своего времени, потому что 80% уходит на преобразование, очистку, выгрузку и сверку данных. Чтобы эффективно решать эту проблему, мы постоянно ищем новые методы и инструменты работы с данными, тестируем, пробуем на реальных задачах. Что же мы называем идеальным ETL инструментом?
Итак, вот 5 основных критериев, которым должен соответствовать идеальный ETL (Extract-Transform-Load) инструмент:
ETL-инструмент должен быть простым в освоении. Речь не о том, что с ним должны уметь работать совсем неопытные люди. Просто специалист не должен тратить полжизни на изучение нового ПО, а просто взять и практически сразу начать работать с ним.
В нём должно быть предусмотрено максимальное количество готовых коннекторов. Ведь в сущности, мы все пользуемся плюс-минус одними и теми же системами: от 1С до SAP, Oracle, AmoCRM, Google Analytics. И никто не хочет программировать коннекторы к ним с нуля.
Инструмент должен быть универсальным и работать с разными BI системами. Это облегчает переход аналитиков и разработчиков из одной компании в другую — если на прошлом месте работы, например, использовали QlikView, а на новом — Visiology, желательно сохранить возможность пользоваться тем же ETL-инструментом.
ETL не должен ограничивать развитие аналитики. Увы, очень у многих ETL-инструментов есть критическая проблема — в них несложно реализовать простенькие вещи, но для более сложных задач приходится искать новый инструмент, который сможет расти вместе с тобой.
Наконец, естественное желание — получить недорогой (а лучше — полностью бесплатный) инструмент, причем не только на время “пробного периода”, а насовсем, чтобы пользоваться им без ограничений.
Что может предложить нам рынок?
В поиске ответа на этот вопрос для себя самих и для наших клиентов. мы отметили на диаграмме наиболее известные решения, подходящие для этой задачи. Они расположены от бесплатных к дорогим, от простых до корпоративных систем Enterprise-класса.

В категории наиболее сложных и дорогих систем доминируют Oracle и Informatica. Microsoft SSIS — чуть более демократичный. Рядом с ними — Apache Airflow. Это открытый продукт, не требующий оплаты, но зато кривая входа для него оказывается довольно крутой. Кроме этого существуют ETL-инструменты, встроенные или связанные с конкретными BI-системами. В их число входят, например, Tableau Prep или Power Query, который используется совместно с Power BI. В числе бесплатных и демократичных решений — Pentaho Data Integration, бывший Kettle, и Loginom.
Но, увы, ни одна из этих систем не удовлетворяет перечисленным 5 критериям. Oracle и Informatica оказываются слишком дорогими и сложными. С Airflow не так уж просто сразу начать работать. EasyMorph не дотягивает по функциональности, а все инструменты, оказавшиеся в центре нашей диаграммы, прекрасно работают, но не являются универсальными. Фактически, я называл бы достаточно сбалансированными решениями Loginom и Pentaho, но тут возникает ещё один важный момент, о котором обязательно нужно поговорить.
Визуальный или скриптовый ETL?
Если копнуть глубже, то все эти (и другие) ETL-инструменты можно разбить на два больших класса — визуальные и скриптовые. Визуальный ETL позволяет делать схемы из готовых блоков, а скриптовый позволяет задавать параметры на специальном языке программирования, уже оптимизированном для обработки данных.
Выбор между визуальным и скриптовым ETL — это настоящий холивар, достойный противостояния «Android vs iOS». Лично я отношусь к той категории, которая считает, что за скриптовыми ETL — будущее. Конечно, визуальный ETL имеет свои преимущества — это наглядность и простота, но только на первом этапе. Как только возникает потребность сделать что-то сложное, картинки становятся слишком запутанными, и мы все равно начинаем писать код. А поскольку в визуальных ETL нет отладчиков и других полезных примочек для кодинга, делать это приходится в откровенно неудобных условиях.
Pentaho и Loginom относятся к визуальному типу. Я считаю, что это очень хорошие системы для своих задач, и если вы сторонник визуальной ETL — на них можно остановиться. Но я всё-таки всегда делаю выбор в пользу скриптового подхода, потому что он позволяет задавать параметры без графических ограничений, и с ним можно значительно ускорить работу — когда ты уже в этом разобрался.
Конечно, стоит учитывать, что все ETL-инструменты тяготеют к смешанному варианту работы, когда либо визуальный дополняется кодом, либо код дополняется визуальными. Но всё равно в ДНК системы может быть что-то одно. И если мы хотим получить хороший скриптовый ETL, нужно ответить на вопрос — каким он должен быть?
Если мы хотим, чтобы ETL был открытым, бесплатным и уже с экосистемой, значит инструмент должен быть на Python. Почему? Потому что, во-первых, Python — это простой язык, сейчас даже дети учатся программировать на Python чуть ли ни с первого класса. Например, в “Алгоритмике” начинают курс программирования именно с Python, а не с Basic или визуального языка Google. Так что подрастающее поколение разработчиков уже знакомо с ним. Во-вторых, огромная экосистема готовых технологий и библиотек уже создана: от каких-то банальных коннекторов до очень серьёзных вещей, связанных с Data Science и так далее. Можно начинать развиваться в этом направлении: здесь ограничений никаких нет.
Конечно, у Python есть и минусы. При столкновении с экосистемой “один на один” будет серьёзная кривая входа. Новичкам разбираться с темой оказывается достаточно сложно. Как минимум, нужно иметь компетенции по работе с Linux, и это для многих сразу становится стоп-фактором. Именно поэтому нам часто говорят: «Нет, мы хотим что-нибудь простое, готовое, с Python мы разбираться не готовы».
Решение = JupyterHub + PETL + Cronicle
Но поскольку во всём остальном готовый инструмент на Python получается хорош, для решения проблемы входа мы подобрали набор технологий, которые помогают упростить работу с системой. Это уже доказавшие свою эффективность зрелые open-source решения, которые можно запросто объединить и использовать:
JupyterHub — интерактивная среда выполнения Python-кода. По сути, это среда разработки, которая позволяет работать с кодом в интерактивном режиме. Она очень удобна для тех, кто не является профессиональным разработчиком, не накопил готовых навыков программирования на уровне спинномозговых рефлексов. JupyterHub помогает, когда ты разбираешься с кодом, пробуешь что-то новое, экспериментируешь.
Библиотека PETL была разработана на Python специально для обработки данных. Она берёт на себя огромное количество рутинных задач, например, разбор CSV файлов различных форматов или создание схемы в БД при выгрузке данных.
Cronicle — удобный и функциональный планировщик, который позволяет легко автоматизировать выполнение задач по обработке данных, отслеживать статистику, выстраивать цепочки, настраивать оповещения и так далее.
Чтобы всем этим было проще пользоваться, мы объединили три инструмента в ViXtract. Речь идет о сборке набора open-source технологий, которая позволяет легко установить решение одной командой и использовать ETL, не заморачиваясь по поводу Linux, по поводу прав, нюансов интеграций и других тонкостей.
Кроме трех основных, сборка включает в себя вспомогательные технические компоненты, такие как PostgreSQL для хранения обработанных данных и Nginx для организации веб-доступа. Кроме этого в дистрибутиве есть уроки и туториалы, в том числе, готовые примеры интеграций, с которых можно начать работу. В планах — добавить в пакет обучающие видеоролики, и я надеюсь, что вы тоже захотите подключиться к этому проекту, ведь ViXtract — это полностью открытый продукт, выпущенный под open-source лицензией.
И ещё несколько слов о самой оболочке
Давайте посмотрим на интерфейс нашего инструмента. На стартовой странице находятся кнопки запуска редактора, планировщика и переходы на полезные ресурсы — сайт, telegram-канал, сообщество и библиотека PETL. Это документация, в которой описаны все функции преобразования, загрузки файлов. Когда вы начинаете работать с ViXtract, эту страницу логично держать всё время под рукой. Сейчас документация на английском, но одно из направлений развития — это перевод всего набора информации на русский язык.
В ViXtract имеется сразу несколько ядер (aka настроенных окружений). Например, одно из них можно использовать для разработки, а другое — для продуктива. Таким образом, вы можете установить много различных библиотек в одном окружении, а для продуктива оставить только проверенные. Окружения можно легко добавлять и изменять, а если вам интересно узнать о самом процессе работы с данными через ViXTract, вы всегда можете задать вопрос в Telegram сообществе ViXtract.

В интерфейсе Jupyter можно сформулировать задачу на преобразование данных. Для этого мы просто создаем тетрадку (набор коротких блоков кода, которые можно запускать интерактивно) и загружаем при необходимости исходные файлы данных.
Загрузка данных
PETL поддерживает множество источников данных, мы рассмотрим несколько типовых примеров. Эти же примеры доступны в виде готовых тетрадок на GitHub или в установленном ViXtract, там их можно попробовать.
Загрузка из xlsx-файла
Использование открытых источников через API
Работа с базой данных
Данные из xlsx-файла
Видим, что данные загрузились без ошибок, однако заголовки столбцов не определились, потому что в начале файла есть лишняя пустая строка. Исправим это, используя функцию skip и поместим результат в переменную olympics
Теперь заголовки у столбцов корректные, однако не достаточно информативны, исправим это, задав заголовки вручную.
Мы начали выстраивать цепочку преобразования таблицы, это удобно, так как можно просмотреть результат работы на каждом этапе. Иногда, наоборот, удобнее объединить цепочку сразу в одной команде. Например, совместим изменение заголовка с сортировкой по количеству золотых медалей.
Сохраним полученные результаты в новый xlsx-файл.
Готово! Теперь обработанный файл можно скачать или загрузить в BI-систему.
Данные из открытого источника рынка акций
Посмотрим, что мы получили в ответ. Мы увидим данные в формате JSON, которые нужно будет промотать до конца
Используем column_names в качестве значения параметра header функции fromcolumns
В этом примере мы используем List comprehension, инструмент Python, который позволяет делать довольно сложные преобразования в наглядном функциональном стиле и без циклов.
Сохраним полученную табличку в csv-файл.
Через несколько секунд созданный файл появится в панели файлов слева, и вы сможете просмотреть или скачать его.
Данные из БД (PostgreSQL)
В состав ViXtract входит предустановленная СУБД PostgreSQL, её удобно использовать как промежуточное хранилище данных, из которого их уже забирает BI-система. Похожие подходы могут быть использованы и с любой другой СУБД.
Рассмотрим следующий пример.
Доступны данные о состояниях различных типов транспортных средств. В базе есть 2 таблицы:
status_ts содержит информацию о состояниях различных ТС
ts_types содержит наименования типов ТС
Необходимо подготовить таблицу, содержащую валидные данные по бульдозерам:
В данных не должно быть пропусков
Время указано в формате datetime
Кроме данных по бульдозерам других нет
Все состояния, кроме отсутствия данных
Для каждого состояния рассчитана продолжительность
Чтобы исключить строки с пропусками, используем функцию select и определенный выше фильтр row_without_nones
Объединим обе таблицы и выберем данные только по бульдозерам, сразу уберём строки с состоянием «Отсутствие данных».
Проверим, что таблица создалась. Обратите внимание, что схема таблицы (типы полей, их названия и так далее) была создана полностью автоматически.
Так мы не зря выбрали Python?
Я по-прежнему часто слышу мнение: “Python, вся эта экосистема — это ужас какой-то, это что-то необъятное!”. Но на самом деле для того, чтобы выгружать данные, требуется лишь небольшое подмножество этого Python, примерно такое же, как с любым другим ETL-инструментом. Когда вы разберетесь с теми функциями, которые действительно нужны, появляется возможность развиваться дальше, переходить к обработке больших данных, потому что все стеки Big Data уже имеют обёртки на Python — качественные, нативные и удобные. А те технологии, которые используются в ViXtract, применяются и для обработки больших данных, за исключением, может быть, PETL, который ориентирован на средние объёмы информации.
Кстати, продвинутая аналитика и Data Science тоже строятся на экосистеме Python. И если что-то было предварительно создано на Python, результаты можно легко передать разработчику уже для внедрения в продуктив. Другими словами, проведенная в ViXtract работа на Python может быть дальше использована в AirFlow для развития в Enterprise-системе. Возможно, разработчику нужно будет переписать код в соответствии со стандартами продуктива, но затраты на коммуникации уменьшаются на порядок.
В ходе нашего Beta-тестирования ViXtract аналитики начали сами решать задачи по загрузке данных из разных источников и их очистке. Раньше эти люди предпочитали написать задачу и отдать её разработчикам — мол, пусть готово будет через неделю, но зато без проблем. А сейчас они могут сами сделать все необходимое за полчаса. И мне хотелось бы, чтобы вы тоже оценили ViXtract, оставили свое мнение о нём, а может быть — подключились к разработке этого инструмента. Так что если вам тоже интересна эта тема, подписывайтесь на наш блог и подключайтесь к обсуждению.
Сайт ViXtract, на котором можно посмотреть видео-демонстрацию и попробовать ViXtract без установки на свой сервер



