Задача на сжатие строки
Добрый день, подскажите пожалуйста, как можно наиболее проще и наименьшим кодом решить данную задачу:
Задача:
Узнав, что ДНК не является случайной строкой, только что поступившие в Институт биоинформатики студенты группы информатиков предложили использовать алгоритм сжатия, который сжимает повторяющиеся символы в строке.
Кодирование осуществляется следующим образом:
s = ‘aaaabbсaa’ преобразуется в ‘a4b2с1a2’, то есть группы одинаковых символов исходной строки заменяются на этот символ и количество его повторений в этой позиции строки.
Напишите программу, которая считывает строку, кодирует её предложенным алгоритмом и выводит закодированную последовательность на стандартный вывод.
Sample Input 1:
aaaabbcaa
Sample Output 1:
a4b2c1a2
Sample Input 2:
abc
Sample Output 2:
a1b1c1
 Сжатие строки
Сжатие строки
# 3 функции нужны для стандартизации программ потом (буду использовать в других программах) def.
Сжатие строки
Питон изучаю не так давно, сейчас прохожу один курс, столкнулся с таким заданием, где нужно сжать.
Указать ошибку + задача на сжатие строки через процедуру
Здравствуйте, очень часто выручал ваш форум, вот решил и свой вопрос задать. Надеюсь на скорую.
Сжатие строки символов путем удаления пробелов из исходной строки
Помогите пожалуйста, нужен только текст кода программы ассемблера, а то с Англ.языком вообще плохо.
Как понять результат анализа ДНК на отцовство?
Результаты ДНК анализов на отцовство судьбоносны, какой бы итог они в себе ни несли. И мы, как никто, понимаем, что выбирая лабораторию для его проведения, вы должны быть уверены в точности и достоверности получаемого результата. В этой статье мы проведем полный разбор заключения по анализу ДНК на отцовство, которое выдается в медико-генетическом центре «МАМА ПАПА», а также, ответим на часто задаваемые вопросы.
Как проводится анализ ДНК на отцовство?
Стандартный материал для проведения данного анализа – это буккальный эпителий, то есть эпителий, который находится в ротовой полости человека. Хотя для проведения ДНК анализа пригоден практически любой биологический материал, содержащий в себе клетки человеческого организма. Буккальный мазок является самым быстрым, безболезненным и доступным для правильного самостоятельного забора способом получения ДНК материала.
ДНК тест на отцовство проводится путем анализа ПРЦ (полимеразной цепной реакции). Последний основан на принципах молекулярной биологии, выполняется с применением особых ферментов, многократно увеличивающих фрагменты ДНК (локусы), позволяя тем самым проводить точную сверку биологических материалов.
Точность такого анализа максимально высокая, именно потому, на данный момент это основной метод установления биологического отцовства. Качественно проведенный ПРЦ анализ не допускает двусмысленного трактования. При его использовании анализы проведенные в двух различных лабораториях в различное время обязательно совпадут!
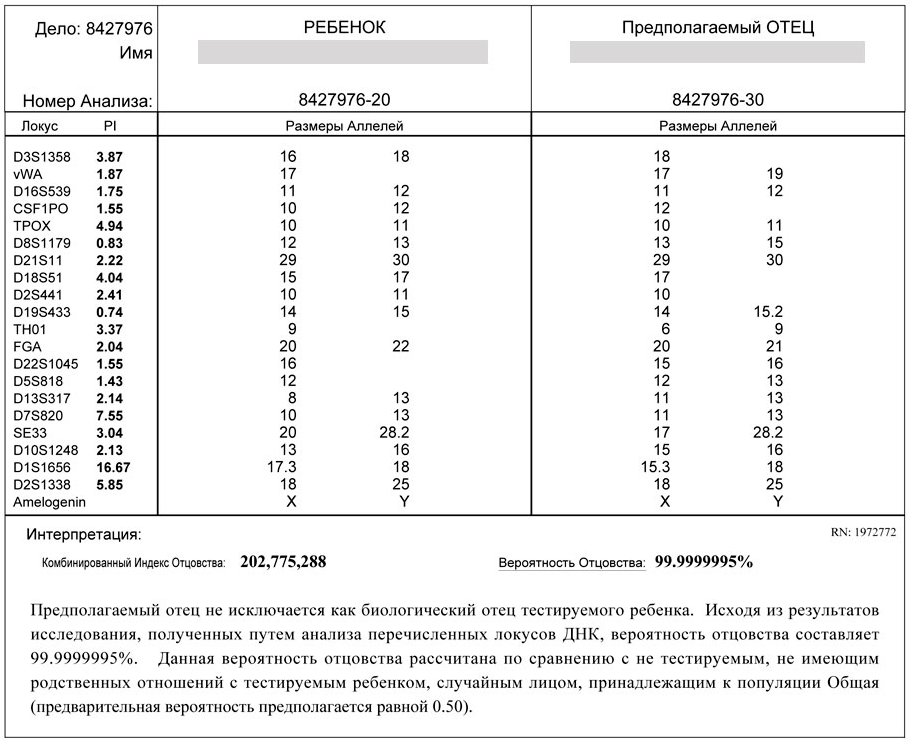
Интерпретация таблицы в результате ДНК анализа на отцовство
1. Перечень сравниваемых локусов
2. Наследование одинаковой аллели от матери и от отца.
Индекс отцовства
Параметр «Индекс отцовства» (в таблице – PI) отображает генетические шансы подтверждения биологического отцовства. Рассчитывается индекс отцовства отдельно для каждого тестируемого локуса и определяется как вероятность того, что ребенком унаследована обязательная аллель предполагаемого отца, а не случайного не тестируемого мужчины.
Комбинированный индекс отцовства – CPI вычисляется путем умножения индивидуальных PI. К примеру, CPI = 100 000, это значит, что вероятность того, что тестируемый мужчина является биологическим отцом, тестируемого ребенка в 100 000 раз выше, чем вероятность на отцовство другого случайного мужчины.
PI в локусах, не имеющих совпадения, равен нулю! Если несовпадение присутствует в 3-х и более локусах, то CPI также равен нулю! Иногда в результате теста может присутствовать несовпадение в 1 или 2 локусах, причиной этому могут быть мутации, близкая родственная связь биологического отца и предполагаемого тестироемого отца (брат, отец и сын). В таком случае, проводится расширенный ДНК анализ с дополнительными расчетами и рекомендацией к участию всех возможных биологических отцов. 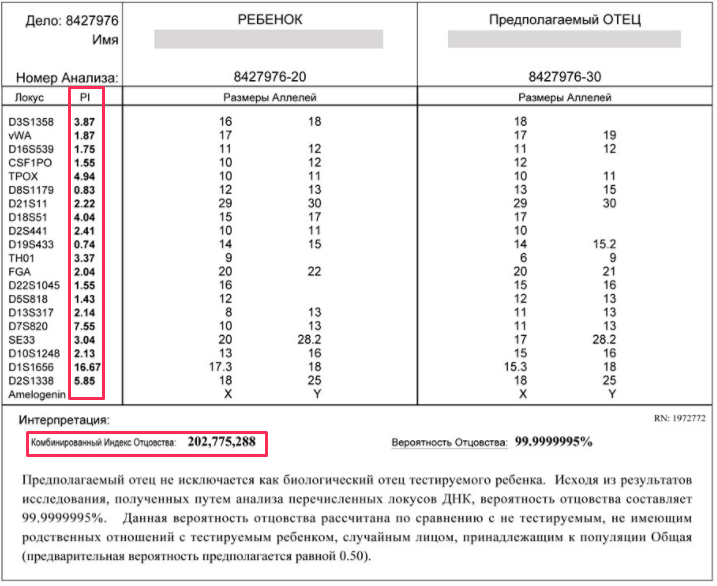
Вероятность отцовства
Вероятность отцовства в результате ДНК анализа указывается в процентах и вычисляется при помощи комбинированного индекса отцовства (CPI). Для того чтобы получить процент вероятности используется первоначальная вероятность отцовства равная 50%, которая считается нейтральным значением. Она указывает на то, что тестируемый мужчина с одинаковой вероятностью может быть и не быть отцом тестируемого ребенка
Если вы провели ДНК тест на отцовство в другой лаборатории и получили результат в 40, 70, и даже 98%, то это повод усомниться в достоверности результата. 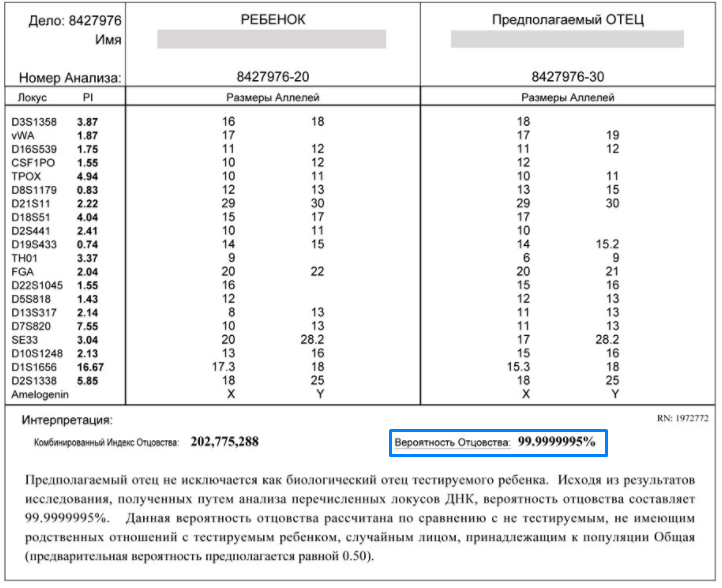
Почему вероятность отцовства 99,99999%, а не 100%?
Каждый человек обладает миллионами генетических маркеров, но тестирование всего генома процедура крайне дорогостоящая и гораздо более трудоемкая (такой анализ занимал бы не недели, а месяцы и стоил бы не менее 10 000 долларов). Для определения отцовства нет необходимости проводить полное тестирование генома, чтобы сделать достоверные выводы, лаборатории достаточно сравнить 15-17 генетических маркеров.
Однако, полностью исключить возможность идентичности ДНК тестируемого отца с неким другим мужчиной невозможно, так как всемирной ДНК базы по всему человечеству не существует. Именно по этой причине в результате ДНК теста на отцовства и не указывается 100% вероятность.
Что может повлиять на результат ДНК анализа на отцовство?
Близкое родство предполагаемых отцов – такая ситуация достаточно распространена, если о близком родстве известно, об этом обязательно нужно сообщать лаборатории и лучше проводить анализ с участием всех предполагаемых отцов. Если анализ с участием второго предполагаемого отца невозможен, то проводится расширенный анализ, до 33 локусов, в котором рассчитывается вероятность отцовства второго отца-родственника, без необходимости его участия.
Повреждение/загрязнение ДНК образца – в каких случаях это может произойти. Забор буккального мазка необходимо проводить обязательно при чистой ротовой полости, за час до забора исключается употребление пищи и каких либо напитков, кроме чистой воды. Мелкие загрязнения в виде частичек бытовой или бумажной пыли игнорируются лабораторией при проведении ДНК анализа и никак не влияют на результат. Однако, если образец будет поврежден плесенью от хранения во влажном виде в полиэтилене, или смешан с образцом другого человека, то лаборатория просто не сможет выделить ДНК из предоставленного материала и запросит пересдачу, то есть, сроки получения результата анализа ДНК на отцовство будут перенесены с учетом нового времени сдачи образцов.
Переливание крови и пересадка костного мозга также не влияют на точность ДНК анализа, так как ДНК человека не может кардинально измениться в течении жизни. Однако, данные ситуации имеют некоторые ограничения. После проведения подобных процедур некоторое время человек может иметь смешанную ДНК и для того, чтобы не запрашивать пересдачи, лаборатория просит проводить ДНК анализы на отцовство по прошествии 3-х месяцев.
Можно ли подделать результат ДНК анализа на отцовство?
Если анализ проводится для личного пользования и забор материала клиент производит самостоятельно, то мы полагаемся на ответственность и честность самих участников, и принимаем готовые ДНК образцы считая, что они принадлежат личностям, заявленным для тестирования.
Лаборатория может обнаружить подмену ДНК образцов, но только в том случае, если пол заявленных участников не будет совпадать с полом, обнаруженным в предоставленных ДНК материалах, или если два ДНК-профиля будут одинаковы.
Пол участников также указывается в таблице результата ДНК анализа на отцовство. 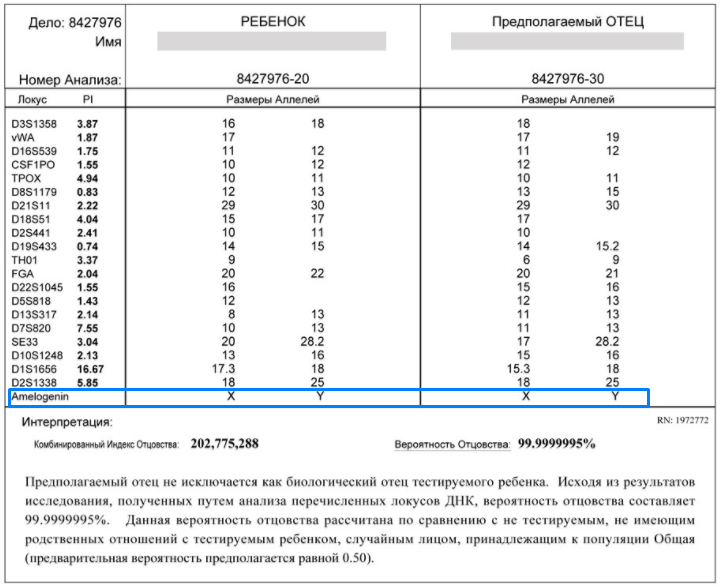
При заказе ДНК теста на отцовство для суда, забор материала проводится нашими сотрудниками, при наличии свидетелей и с идентификацией личности, то есть любая подмена исключена.
Узнав что днк не является случайной строкой только что

ДНК (сокращение от дезоксирибонуклеиновая кислота) – это одна из важнейших для живых существ молекула, в которой содержится вся генетическая информация о них. Если представить, что живое существо – это какой-нибудь сложный прибор, например, магнитофон, то ДНК можно сравнить с пленкой, на которой записаны инструкции по созданию магнитофона и его функционированию.
Молекулы ДНК есть в каждой клетке нашего организма, и они хранятся в ядре (существует еще одна внеядерная разновидность ДНК –митохондриальная, она кратко описана в словаре). Если достать ДНК всего лишь из одной клетки и вытянуть, то длина полученной нити составит около двух метров. При этом размеры клеточного ядра не превышают шести микрометров (микрометр – это одна миллионная часть метра). ДНК помещается в ядро за счет того, что она многократно свернута и уложена в компактные тельца – хромосомы. У человека в ядре каждой клетки хранятся 23 пары хромосом – один набор приходит от отца, второй – от матери. Исключением являются половые клетки – яйцеклетка и сперматозоид, которые несут только половину всех хромосом. Такое «сокращение» необходимо, чтобы при слиянии сперматозоида и яйцеклетки образовался бы организм с нормальным набором хромосом.
В каждой клетке есть специальные системы, которые считывают заложенную в ДНК информацию и на ее основе создают новые белки (белки выполняют в клетке огромное число функций – от строительства до регуляции прочтения заложенных в ДНК инструкций). Хранящиеся в ДНК «послания» особым образом закодированы. Код ДНК состоит из четырех «символов», или нуклеотидов. Эти четыре разновидности нуклеотидов обозначаются буквами А (аденин), Т (тимин), Г (гуанин) и Ц (цитозин).
В нитях ДНК нуклеотиды соединены один за другим в длинные цепочки. В итоге закодированная информация выглядит примерно так: ААТГЦГТААГЦЦ… и так далее. Для непосвященного человека подобный набор букв кажется бессмысленным, однако клеточные «шифровальщики» точно знают, как на основе заложенной в ДНК информации синтезировать нужные клетке белки.«Шифровальщики» узнают определенные последовательности нуклеотидов, называемые генами. Каждый ген кодирует один белок. Именно поэтому гены называют элементарными единицами наследственности.
Если спросить человека на улице, что приходит ему в голову, когда он слышит слово «ДНК», то, скорее всего, ответом будет «двойная спираль». У нас пока о двойной спирали не было ни слова. Что же это такое, и почему за ее открытие американские ученые Джеймс Уотсон и Френсис Крик получили Нобелевскую премию по физиологии и медицине?
Двойная спираль – это пространственная структура, в форме которой существует ДНК. Дело в том, что нити ДНК «не любят» быть поодиночке. У каждой нити есть напарница, с которой они переплетаются на всем своем протяжении. В итоге как раз и образуется двойная спираль. Нити ДНК объединяются в пары не просто так. Во-первых, двойная спираль значительно более стабильна, чем одиночная нить. Во-вторых, сдвоенные цепочки ДНК не путаются, поэтому считывание информации проходит без проблем. В-третьих, вторая цепь необходима в качестве гарантии сохранности информации. Нити ДНК соединяются в пары случайным образом, а, как говорят ученые, по принципу комплементарности. Это означает, что напротив каждого нуклеотида в одной нити всегда находится строго определенный нуклеотид из второй нити. Парой для А всегда выступает Т, а напарником Г является Ц.
Эта особенность ДНК позволяет однозначно восстановить последовательность нити, имея на руках ее комплементарную копию. Если ДНК каким-либо образом повреждается и теряются кусочки одной из нитей, специальные белки заполняют возникшие бреши, используя в качестве матрицы для синтеза новой нити ее напарницу.
Существует еще один критически важный для клетки процесс, который требует существования двойной спирали. Это деление клеток. Перед тем как удвоиться, клетка синтезирует вторую копию всей своей ДНК. Это происходит так: двойные спирали расплетаются, и специальные белки создают новые комплементарные копии к каждой из оставшихся поодиночке нитей. В итоге снова образуются двойные спирали, но их уже вдвое больше, чем было исходно. Когда клетка разделяется надвое, каждая половинка получает по одному полному комплекту ДНК.
Механизмы синтеза новых цепей работают очень точно, однако иногда происходят сбои, и на месте, скажем, нуклеотида А появляется нуклеотид Г. Причем ошибка может произойти не только в одном нуклеотиде: из цепи ДНК могут выпасть (или появиться) сразу несколько «букв». Ошибки размером в один нуклеотид получили название однонуклеотидных полиморфизмов, ошибки большего размера специального названия не имеют и объединяются под термином «мутации» (сюда входят и однонуклеотидные полиморфизмы).
Мутации могут никак не сказываться на работе клетки (например, если они произошли между генами), могут улучшить ее работу, а могут вызвать серьезный сбой. Последнее часто происходит в том случае, если из-за мутаций нарушается синтез того или иного белка. Именно мутации являются причиной многих наследственных заболеваний.
Оценка результатов ДНК-анализа для решения вопросов идентификации личности

(124 Центральная лаборатория МО РФ)
Оценка результатов ДНК-анализа для решения вопросов идентификации личности / Ракитин В.А., Корниенко И.В. // Мат. VI Всеросс. съезда судебных медиков. — М.-Тюмень, 2005. — С. 239-241.
библиографическое описание:
Оценка результатов ДНК-анализа для решения вопросов идентификации личности / Ракитин В.А., Корниенко И.В. // Мат. VI Всеросс. съезда судебных медиков. — М.-Тюмень, 2005. — С. 239-241.
код для вставки на форум:
1. ВВЕДЕНИЕ
С середины 80-х годов ведется разработка методов выявления гипервариабельных последовательностей ДНК человека, так называемая геномная «дактилоскопия». В отличие от традиционных средств, используемых для установления родства (определение группы крови, анализ белковых изоформ и др.), которые не могут обеспечить высокую степень индивидуальности набора признаков, профили ДНК практически полностью специфичны для каждого человека, в силу чего представляют собой хороший инструмент для идентификации личности. Молекулярно-генетический идентификационный анализ на сегодняшний день является одним из наиболее доказательных методов исследования биологического материала в судебной медицине.
Ведущие специалисты в области молекулярно-генетических исследований – M. M. Holland and T. J. Parsons (The Armed Forces DNA Identification Laboratory Office of the Armed Forces Medical Examiner the Armed Forces Institute of Pathology Rockville, Maryland United States of America, [1]) на основе анализа мировой практики судебной молекулярно-генетичекой экспертизы констатируют: «Профилирование ДНК является наиболее мощным и достоверным методом идентификации после дактилоскопии, поскольку большинство профилей мультилокусов ДНК-RFLP или AmpFLP позволяют надежно идентифицировать происхождение объекта, делая маркеры яДНК золотым стандартом или наилучшим методом в судебной экспертизе.
ДНК-типирующие системы на основе ПЦР и RFLP выдержали испытание научного и юридического сообщества. Хотя надежность и приемлемость этих процедур все еще критикуется в судах по рутинным причинам – (курсив наш) теперь уже есть концептуальное принятие этих двух методологий, использующих исследование профилей яДНК, а также их статистические веса. Используя эти методы, криминалистические лаборатории в настоящее время имеют способность идентифицировать биологические вещественные доказательства с большой точностью и надежностью. Анализ митохондриальной ДНК играет ключевую роль в дополнении этой способности».
ДНК-идентификация человека основана на выявлении молекулярно-генетических индивидуализирующих признаков и их анализе в исследуемых и сравниваемых объектах напрямую или опосредованно – через установление кровного родства 6. При этом следует отметить, что дискриминирующая способность непрямой ДНК-идентификации существенно ниже, чем прямой. Поэтому считаем необходимым более подробно рассмотреть вопрос идентификации личности через установление кровного родства.
2. ВОЗМОЖНОСТИ МЕТОДА
Посредством непрямой ДНК-идентификации решаются вопросы принадлежности исследуемого субъекта к определенному семейному кругу. Субъектами исследования могут быть:
ДНК-анализом, теоретически (исходя из теории вероятностей), не обеспечивается 100% доказательства кровного родства или идентичности аллельных профилей исследуемого объекта и сравниваемого субъекта. Однако, в практике, на современном уровне молекулярно-генетических исследований, возможно установление количественных и качественных характеристик совокупности генетических признаков, отличающих конкретного человека от других людей в определенной группе населения, что позволяет категорически судить об идентификации личности или о происхождении биологического следа от конкретного лица.
3. Вычисление вероятности кровного родства
Для оценки результатов молекулярно-генетической экспертизы используют вероятностные расчеты, базирующиеся на аллельных частотах в различных популяциях, получаемых эмпирически. Если кровное родство не исключается, проводится вероятностная оценка принадлежности субъекта к данной родственной группе. Процедура вероятностной оценки кровного родства, в основе которой лежит бэйсовский метод оценки условных вероятностей, состоит в следующем [3, 4, 8].
то есть коэффициент правдоподобия гипотезы, что наблюдается событие С. Коэффициент LR вычисляется по всем типированным локусам я-ДНК. Принимая положение о независимости наследования ядерных локусов [4], для n локусов имеем выражение:
Описанная выше методика статистической оценки результатов молекулярно-генетического анализа кровного родства реализована в компьютерной программе «DNAdacto» для операционной системы Microsoft Windows [5].Коэффициент правдоподобия оценки гипотез LR – вещественное число. Оно показывает отношение вероятности доказательства события, что данная группа является действительно родственной группой, к вероятности доказательства события, что исследуемый субъект не имеет родства с этой группой, но случайно подходит к ней по своему генотипу. Исходя из значений LR, можно вычислить процент вероятности кровного родства по формуле
4. ОЦЕНКА РЕЗУЛЬТАТОВ ИССЛЕДОВАНИЯ
4.1. Историческая справка
Шкала оценки значений коэффициента правдоподобия и процента вероятности кровного родства согласно Evett I.W., Weir B.S. (в русском переводе) [6, 8, 9,].
| Значение коэффициента правдоподобия | Словесная формулировка | Вероятностная оценка (%) |
|---|---|---|
Наша практика производства молекулярно-генетических экспертиз показывает, что предложенные ранее вербальные характеристики кровного родства не удовлетворяют не только правоохранительные органы, которые требуют дополнительных экспертных разъяснений для понимания результатов исследований неспециалистами в области генетики, но и судебно-медицинских экспертов-танатологов. Это обусловлено, во-первых, тем, что формулировки оценки результатов без каких-либо пояснений переносятся в выводы заключения эксперта; во-вторых – буквальный перевод шкалы оценки значений коэффициента правдоподобия и процента вероятности кровного родства согласно Evett I.W., Weir B.S., не соответствует традиции применения понятий в русской экспертной практике. В связи с изложенным, мы предлагаем свою шкалу значений коэффициента правдоподобия и вербальных интерпретаций результатов молекулярно-генетических исследований (таблицы 3, 4), на основании которой формируются выводы эксперта.
4.2. Алгоритм оценки результатов
Порядок оценки результатов по предлагаемой шкале складывается из двух этапов. На первом этапе по четырем категориям производится первичная оценка данных по всему диапазону возможных отношений исследуемого субъекта к сравниваемой семейной группе или субъекту сравнения. То есть, производится определение соотношения гипотез: «родство есть» – «родства нет» (раздел 1 шкалы оценки результатов молекулярно-генетических исследований – табл. 3). На втором этапе, после принятия решения по крайним значениям доказательства гипотез, производится оценка степени доказательства гипотезы «родство есть» по четырехуровневой схеме в пределах значений ниже уровня «кровное родство практически доказано» (раздел 2 шкалы оценки результатов молекулярно-генетических исследований – табл. 4).
Раздел 1 шкалы оценки результатов молекулярно-генетических исследований
Значение коэффициента правдоподобия
Вероятностная объективная оценка (%)
Кровное родство исключается
Отсутствие совпадающих аллелей по 2-м и более локусам ДНК
Кровное родство не исключается
Нет возможности доказательства преимущества одной из гипотез.
Кровное родство вероятно
от 90,9 до 99,9999995
Для оценки принимается гипотеза – «родство есть».
Используются расчеты вероятности случайного совпадения генотипов в пределах свободного перемещения граждан по территории бывшего СССР, обусловленного необходимостью или возможностью поддержания исторически сложившихся родственных и других связей.
Кровное родство практически доказано
Гипотеза – «родство есть», практически доказана. Вероятность случайного совпадения генотипов настолько мала, что можно говорить об уникальной комбинации генетических признаков.
Раздел 2 шкалы оценки результатов молекулярно-генетических исследований
| Значение коэффициента правдоподобия | Вербальная оценка степени доказательства вероятности кровного родства | Вероятностная объективная оценка (%) |
|---|---|---|
В тех случаях, когда результат соответствует категориям оценки 1, 2, 4 раздела 1 шкалы …, то на этом этапе анализ заканчивается и результат оценивается в соответствии с предложенной в таблице формулировкой с изложением доказательства. Например:
Данная оценка результатов молекулярно-генетического исследования применима при условиях отсутствия каких-либо объективных данных или обстоятельств дела, ограничивающих круг субъектов, в котором может повториться профиль исследуемой ДНК. В других случаях, например:
Следует пояснить, что, исходя из конечной цели молекулярно-генетического исследования – доказательства одной из двух гипотез о кровном родстве исследуемых и сравниваемых субъектов, понятием «кровное родство вероятно» определяется интервал переменных значений степени доказательства гипотезы «родство есть». То есть, оно отражает не количественную сторону кровного родства, а качественную оценку исследования в виде установки на доказательство гипотезы – «родство есть». Другими словами это можно представить так, что при любых значениях коэффициента правдоподобия само по себе «кровное родство» не увеличивается и не уменьшается, а меняется лишь значение степени доказательства вывода о наличии кровного родства. Степень этого доказательства в основном зависит от частоты встречаемости аллелей и количества исследуемых локусов, то есть от методики исследования. Поэтому, используя современные тест-системы, определяя генотипы двух родителей, исследование дополнительных полиморфных генетических маркеров ядерной и митохондриальной ДНК, а также исходя из конкретных обстоятельств исследуемого события и анализа других доказательств (пол, возраст и др.), можно достигать крайних уровней доказательства гипотез, практически, во всех случаях.
При этом словесные формулировки оценки результатов не могут служить выводами, так как они являются концентрированным отражением результатов исследования на специальном научном языке генетиков, поэтому исследовательская часть заключения эксперта должна заканчиваться разделом «Оценка результатов». Аналогом такой оценки в судебно-медицинской экспертизе является диагноз, который пишется медицинскими понятиями и служит морфологической базой для построения выводов в заключениях экспертиз живых лиц и трупов. В судебной медицине медицинские данные трансформируются в выводы языком предельной ясности понятиями, суждениями, умозаключениями общеобразовательного уровня. Такое правило должно распространяться и на судебно-медицинскую молекулярно-генетическую экспертизу.
5. ЗАКЛЮЧЕНИЕ
похожие статьи
Особенности анализа генотипа лица мужского генетического пола без детекции «Y» при исследовании гена амелогенина / Потеряйкин Е.С., Якубович В.С., Игнатова С.В. // Избранные вопросы судебно-медицинской экспертизы. — Хабаровск, 2019. — №18. — С. 172-174.



