NUMA и что про него знает vSphere?
Я думаю, многие уже успели заглянуть и прочитать эту статью на английском в моем блоге, но для тех кому все таки комфортней читать на родном языке, нежели иностранном (как сказали бы на dirty.ru – на анти-монгольском), я перевожу очередную свою статью.
Вы уже наверняка знаете, что NUMA это неравномерный доступ к памяти. В настоящий момент эта технология представлена в процессорах Intel Nehalem и AMD Opteron. Честно говоря, я, как практикующий по большей части сетевик, всегда был уверен, что все процессоры равномерно борются за доступ к памяти между собой, однако в случае с NUMA процессорами мое представление сильно устарело.

Приблизительно так это выглядело до появления нового поколения процессеров.
В новой же архитектуре каждый процессорный сокет имеет прямой доступ только к определенным слотам памяти и образует NUMA узел. То есть при 4 процессорах и 64 Гбайт памяти у вас будет 4 NUMA узла, каждый с 16 Гбайт памяти.
Насколько я понял, новый подход к распределению доступа к памяти был изобретен в силу того, что современные сервера настолько напичканы процессорами и памятью, что становится технологически и экономически невыгодно обеспечивать доступ к памяти через единственную общую шину. Что в свою очередь может вести к соперничеству за полосу пропускания между процессорами, ну и к более низкой масштабируемости производительности самих серверов. Новый подход привносит 2 новых понятия – Локальная память и Удаленная память. В то время как к локальной памяти процессор обращается напрямую, то к Удаленной памяти ему приходится обращаться старым дедовским методом, через общую шину, что означает более высокую задержку. Это также означает, что для эффективного использования новой архитектуры наша ОС понимать, что она работает на NUMA узле и правильно управлять своими проложениями/процессами, иначе ОС просто рискует оказаться в ситуации, когда приложение исполняется на процессоре одного узла, в то время как его (приложения) адресное пространство памяти располагается на другом узле. Быстрый поиск показал, что NUMA архитектура поддерживается Майкрософт начиная с Windows 2003 и Vmware – как минимум с ESX Server 2.
Не уверен, что в GUI как то можно увидеть данные NUMA узла, но определенно это можно посмотреть в esxtop.
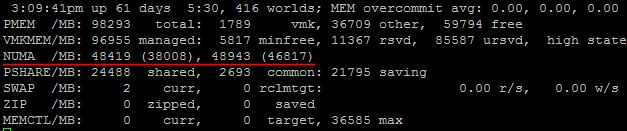
Итак, тут мы можем наблюдать, что в нашем сервере 2 NUMA узла, и что в каждом их них 48 Гбайт памяти. Вот этот документ говорит, что первое значение означает количество локальной памяти в NUMA узле, а второе, в скобочках – количество свободной памяти. Однако, пару раз на своих продакшн серверах я наблюдал второе значение выше, чем первое, и никакого объяснения этому найти не смог.
Итак, как только ESX сервер обнаруживает, что он работает на сервере с NUMA архитектурой, он незамедлительно включает NUMA планировщик, который в свою очередь заботится о виртуальных машинах и о том, чтобы все vCPU каждой машины находились в пределах одного NUMA узла. В предыдущих версиях ESX (до 4.1) для эффективной работы на NUMA системах максимальное количество vCPU виртуальной машины всегда ограничивалось количеством ядер на одном процессоре. Иначе NUMA планировщик просто игнорировал эту ВМ и vCPU равномерно распределялись поверх всех доступных ядер. Однако в ESX 4.1 была представлена новая технология, называемая Wide VM. Она позволяет нам назначать в ВМ большее количество vCPU, чем ядер на процессоре. Согласно Vmware документу планировщик разбивает нашу «широкую виртуальную машину» на несколько NUMA клиентов и затем уже каждый NUMA клиент обрабатывается по стандартной схеме, в пределах одного NUMA узла. Однако, память все таки будет разрозненной между выбранными NUMA узлами этой Wide VM, на которых работают vCPU виртуальной машины. Это происходит потому, что предсказать к какому участку памяти обратится тот или иной vCPU NUMA клиент практически невозможно. Несмотря на это, Wide VM все равно предоставляют существенно улучшенный механизм доступа к памяти по сравнению со стандартным «размазыванием» виртуальной машины поверх всех NUMA узлов.
Еще одна замечательная особенность NUMA планировщика это то, что он не только решает где расположить виртуальную машину при ее запуске, но и постоянно следит за ее соотношением локальной и удаленной памяти. И если это значение уходит ниже порога (по неподтвержденной инфо – 80%), то планировщик начинает мигрировать ВМ в другой NUMA узел. Более того ESX будет контролировать скорость миграции чтобы избежать излишней загруженности общей шины, через которую общаются все NUMA узлы.
Стоит также отметить, что при установке в памяти сервер вы должны уставновить память в правильные слоты, т.к. за распределение памяти между NUMA узлами отвечает не NUMA планировщик, а именно физическая архитектура сервера.
Ну и напоследок, немного полезной информации, которую вы можете подчерпнуть из esxtop.

Краткое описание значений:
NHN Номер NUMA узла
NMIG Количество миграций виртуальной машины между NUMA узлами
NMREM Количество удаленной памяти, используемой ВМ
NLMEM Количество локальной памяти, используемой ВМ
N&L Процентное соотношение между локальной и удаленной памятью
GST_ND(X) Количество выделенной памяти для ВМ на узле X
OVD_ND(X) Количество памяти потраченной на накладные расходы на узле X
Хотелось бы отметить, что как обычно вся эта статья всего лишь компиляция того, что мне показалось интересным из прочитанного за последнее время в блогах таких товарищей как Frank Denneman и Duncan Epping, а также официальных документов Vmware.
День из работы техотдела или что такое NUMA
NUMA — это короткое слово, которое периодически замечаешь то там, то тут. В настройках BIOS, в логах операционной системы и т.д. Понимаешь, что оно как-то связанно с многопроцессорными системами, но на что именно влияет и зачем нужно, — эти вопросы практически всегда остаются без ответа. В большинстве случаев, не бывает особой нужды детально разбираться в этих тонкостях работы компьютера. Как известно, человек — создание ленивое, а следовательно: без нужды ничего делать не будет. Работает — значит не трогай… пусть дальше работает. Это девиз многих системных администраторов, и до недавнего времени мы тоже этим от многих других не отличались. Естественно, мы старались что-то оптимизировать, более корректно настраивать многие компоненты операционной системы и серверов. Но мы не пытались оптимизировать абсолютно все. Не факт, что усилия, потраченные на оптимизацию, хоть как-то окупятся.
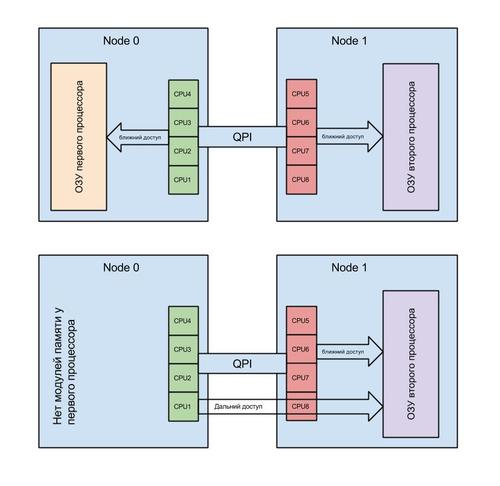
Это продолжалось до тех пор, пока мы не столкнулись со странным поведением сервера, которое было крайне сложно объяснить. У сервера периодически переставала работать дисковая подсистема, из системы просто исчезал RAID контроллер. Это делало сервер неработоспособным. После перезагрузки нормальная работа системы восстанавливалась. RAID контроллер снова появлялся и работал исправно, как будто ничего и не происходило. Замена RAID контроллера, установка его в другой слот PCI-X, а также замена материнской платы, процессоров, блоков питания, — ничего не давало результатов. Сервер продолжал работать нестабильно. Что мы только не делали — сервер продолжал падать с завидной регулярностью. От одного раза в день до нескольких раз за час. Спрогнозировать дату падения и объяснить, с чем оно связано, было крайне сложно. Наблюдая за графиками загрузки сервера, мы не понимали, в чем проблема. Проблемы появлялись и при маленькой нагрузке на процессор, и при большой. Ответ был найден случайно, в процессе перебора всего подряд. Причиной сбоев оказалось некорректное распределение оперативной памяти между процессорами. Я случайно, собирая информацию о системе, посмотрел на топологию NUMA. Оказалось, что основная масса процессов в системе выполняет дальний доступ к памяти. Это заставило меня обратить внимание на то, что поставщик, из расчета на апгрейд (модернизацию), вместо установки 6-и планок памяти, установил 3, но вдвое большего объема. Как следствие, планки были установлены только в слоты одного процессора. И, по воле случая, первый процессор в системе остался без планок памяти. Так случайный взгляд, брошенный на вещи, на которые мы никогда не обращали внимание, помог выявить проблему.
Так что же такое NUMA? Non-Uniform Memory Access — это «неравномерный доступ к памяти». Так гласит Википедия. Простым языком: это способ взаимодействия одного процессора с блоками памяти второго процессора. Это умное распределение памяти между процессами (условно — программами) в ОС. NUMA помогает распределить процессы в системе так, чтобы они получали области оперативной памяти, расположенные максимально близко к процессорам, на которых они работают. В такой ситуации, как у нас, программы (процессы), запущенные на процессоре без оперативной памяти, использовали так называемый “дальний доступ”. Другими словами: доступ осуществлялся через контроллер на другом процессоре. Все бы ничего и система linux давно умеет решать подобные проблемы. Априори программы (процессы) размещаются на процессоре с оперативной памятью. Но мы не учли одного фактора. А именно: систему виртуализации XEN. Она самостоятельно назначает соответствие виртуального процессора для виртуальной машины физическому (реальному) процессору в системе. Усугубляет ситуацию тот факт, что хост-система (управляющая) является такой же виртуальной машиной, как и другие. И только к ней подключены устройства, такие как: контроллер дисков, сетевая карта и т.д. По-умолчанию, любой виртуальный процессор может оказаться на любом физическом. Зачастую, в хост-системе первый виртуальный процессор соответствуют первому физическому процессору. И, поскольку на виртуальной машине с точки зрения NUMA все процессоры и вся память локальны, хост-система размещает на первом процессоре все прерывания и процессы для работы с устройствами. А если этот процессор не имеет подключенной оперативной памяти, то это не только снижает производительность системы, но и позволяет возникнуть аварийной ситуации. Плюс ко всему, этому первому физическому процессору могут быть назначены несколько виртуальных. А следовательно, за время (ресурсы) первого процессора будут конкурировать несколько виртуальных машин. Установка приоритета доступа к процессорному времени для хост-системы несколько улучшает ситуацию, но не решает проблему полностью. В процессе работы ввиду нехватки процессорного времени для хост-системы происходят сбои и шина pci переинициализируется. В какой-то момент превышается предел ожидания ответа, заложенный в драйвер RAID контроллера, и система констатирует факт его потери. Изюминкой ситуации является тот факт, что проблема появляется только при определенной нагрузке. Как только мы убираем все виртуальные машины с этого сервера, он начинает стабильно работать.
Решением оказалось принудительное перераспределение процессоров между виртуальными машинами. Так, чтобы первый виртуальный процессор на хост-системе был на физическом процессоре, к которому подключена оперативная память. К тому же мы выделили одно физическое ядро процессора с памятью эксклюзивно для хост-системы. Это позволило избежать конкуренции с другими виртуальными машинами. И вуаля! Система уже более месяца работает стабильно. Но это не все! Также существенно увеличилась скорость работы с дисковой подсистемой. Это решение не ново и часто описывается на многих специализированных ресурсах, но в программных продуктах, используемых для автоматизации VPS-хостинга, оно почему-то не учитывается в принципе. На данный момент мы более не покупаем системы без минимального набора оперативной памяти для всех процессоров. Также мы провели эксперимент с системой, у которой был полный комплект памяти. Выделили одно ядро физического процессора для хост-системы и получили прирост скорости работы дисковой подсистемы. Теперь мы работаем над тем, чтобы автоматизировать подобные настройки на всех наших серверах. Это позволит, не меняя аппаратного обеспечения, повысить производительность дисковой подсистемы на наших серверах.
sidadm
записки SAP Basis консультанта
Полезное
вторник, 13 июля 2021 г.
VMware и NUMA: выбор правильного размера памяти VM
Современные серверные решения на базе архитектуры x86, которые сейчас используются почти во всех программно-аппаратных комплексах, имеют некоторые нюансы. Многопроцессорные сервера, имеющие на материнской плате 2, 4 или даже 8 процессорных сокетов, являются по сути NUMA-архитектурой. NUMA (Non-Uniform Memory Architecture) означает, что каждый процессорный сокет имеет свой пул локальных модулей оперативной памяти и такая связка называется узлом NUMA (рис. 1).
 |
| Рис. 1. UMA и NUMA архитектуры. |
Все процессорные ядра и вся оперативная память объединены в одну систему, но обращение процессора к своим (локальным) модулям памяти происходит с большей скоростью (или меньшими задержками), чем к памяти соседнего процессора.
Все современные операционные системы и программные решения более высокого уровня (например, виртуальный гипервизор или СУБД) понимают особенности этой архитектуры. В идеале, это понимание позволяет большинство операций выполнять с памятью локального процессора, не ходя в «дальние края» за памятью соседа.
vSphere от VMware тоже прекрасно разбирается в NUMA. При конфигурировании виртуальной машины (если вы не активируете опцию «Enable CPU Hot Add») и при её работе гипервизор будет размещать виртуальные процессорные ядра (vCPU) и память виртуальной машины в один узел NUMA. Причём, эта функция работает по умолчанию, ничего отдельно настраивать не надо.
Хочу на своём примере показать недостаточно корректную настройку размера виртуальных машин, с учётом NUMA архитектуры. На проекте, про который хочу рассказать, были сервера двух типов:
Понимая, всю ситуацию с NUMA архитектурой я разместил на серверах первого типа виртуальные машины с характеристиками:
Но после прокачки своих знаний по VMware, мне открылось, что я совершил ошибку при конфигурации объёмов памяти.
 |
| Рис. 2. Основной экран утилиты esxtop. |
 |
| Рис. 3. Активация просмотра статистики по NUMA узлам. |
После этого на экране появится несколько важных полей:
Последний параметр помогает проанализировать итог работы виртуальной машины на NUMA узлах. Если он равен 100%, значит производительность оптимальна. Если же ниже 100%, значит не всегда в процессе работы на реальных процессорных ядрах для текущей виртуальной машины идёт попадание в память локального узла NUMA.
По моей ситуации. Первые две большие виртуальные машины не всегда попадают в память локального NUMA узла (рис. 4 и 5). Напомню, что обе машины работают на серверах с размером узла NUMA = 16 ядер (с учётом HT) + 96 Гб.
 |
| Рис. 4. Статистика по NUMA виртуальной машины 8 vCPU + 96 Гб. |
 |
| Рис. 5. Статистика по NUMA виртуальной машины 16 vCPU + 192 Гб. |
«Небольшие» виртуальные машины, работающие на серверах второго типа (с размером узла NUMA = 16 ядер (с учётом HT) + 128 Гб памяти), отлично умещаются в локальных NUMA узлах (рис. 6). Забора «чужой» памяти нет, всё работает оптимально.
 |
| Рис. 6. Статистика по NUMA виртуальной машины, работающей на сервере второго типа. |
Если у меня будет возможность, то я переконфигурирую данные виртуальные машины, которые не оптимально попадают в узлы NUMA. И потом поделюсь с вами результатами статистики.
Update: результаты оптимизации можно найти в этом посте.
Русские Блоги
Архитектура NUMA высокопроизводительной виртуальной машины OpenStack Nova
оглавление
Напиши спереди
Я был слишком занят в последнее время. Я слишком ленив, чтобы рисовать картинки. Большинство картинок в статье из Интернета. Спасибо создателям (к сожалению, я не могу найти источник).
Архитектура вычислительной платформы
SMP симметричная многопроцессорная структура
SMP (Sysmmetric Multi-Processor, симметричный мультипроцессор)Как следует из названия, SMP состоит из нескольких процессоров с симметричными отношениями. Так называемая симметрия относится к горизонтальному зеркальному отображению между процессорами, и нет различия между главным и подчиненным. С появлением SMP компьютер больше не состоит из одного процессора.
Типичными характеристиками SMP являются«Несколько процессоров совместно используют централизованную память», И интервал времени для каждого процессора для доступа к памяти одинаков, так что рабочая нагрузка может быть равномерно распределена по всем доступным процессорам, что значительно повышает производительность обработки данных всей системы.

Хотя SMP имеет несколько процессоров, поскольку существует только одна общая централизованная память, SMP может запускать только одну копию (экземпляр) операционной системы и системы баз данных и при этом сохраняет автономные характеристики. В то же время SMP также потребуется несколько процессоров для обеспечения согласованности данных в общей памяти. Если несколько процессоров запрашивают доступ к совместно используемым ресурсам одновременно, для решения проблемы конкуренции за ресурсы необходим механизм блокировки, реализованный программным или аппаратным обеспечением. Поэтому SMP также называется UMA (Uniform Memory Access). Так называемая согласованность относится к:
Очевидно, что эта архитектура не предназначена для обеспечения хорошей масштабируемости числа процессоров, поскольку конкуренция за ресурсы общего хранилища всегда существует, и наилучшее использование процессора может оставаться только от 2 до 4. В совокупности архитектура SMP широко применяется в области ПК и мобильных устройств и может значительно улучшить производительность параллельных вычислений. Но SMP не подходит для очень масштабных серверных сценариев, таких как облачные вычисления.

NUMA неоднородная структура доступа к памяти
В современных компьютерных системах скорость обработки процессора превысила скорость чтения и записи основной памяти, а узкое место, ограничивающее производительность компьютера, переместилось на пропускную способность памяти. SMP Поскольку конструкция централизованной разделяемой памяти ограничивает частоту доступа процессора к памяти, процессор часто может быть голоден к доступу к данным.
NUMA (неоднородный доступ к памяти, неоднородный доступ к памяти)Идея проекта состоит в том, чтобы разделить процессор и память на разные узлы (NUMA Node), и все они имеют почти равные ресурсы. Внутри узла NUMA он будет обращаться к внутренней локальной памяти через собственную шину хранения, а все узлы NUMA могут получать доступ к удаленной памяти других узлов через общую шину на материнской плате.

Очевидно, что время, затрачиваемое процессором на доступ к локальной памяти и удаленной памяти, не совпадает, отсюда и название неоднородного доступа к памяти NUMA. А поскольку разделение узлов не обеспечивает истинной изоляции хранилища, NUMA также сохраняет только копию операционной системы и системы баз данных.

NUMA「МногоузловойСтруктура структуры SMP может в определенной степени решить проблему низкой пропускной способности хранилища SMP. Если имеется система с 4 узлами NUMA, каждый узел NUMA имеет пропускную способность хранения 1 ГБ / с внутри, а внешняя общая шина также имеет пропускную способность 1 ГБ / с. В идеальном случае, если все процессоры всегда имеют доступ к локальной памяти, тогда система имеет пропускную способность хранилища 4 ГБ / с. В настоящее время каждый узел можно приблизительно рассматривать как SMP (это предположение для простоты понимания, Не совсем правильно), наоборот, в наиболее неудовлетворительном случае, если все процессоры всегда имеют доступ к удаленной памяти, тогда система может иметь пропускную способность памяти только 1 ГБ / с.
Кроме того, использование внешней совместно используемой шины может вызвать ненормальную синхронизацию кэша между узлами NUMA, что серьезно повлияет на производительность нагрузок, интенсивно использующих память. Когда критически важна производительность ввода-вывода, потеря ресурсов кэша на общей шине приведет к резкому падению производительности устройств, подключенных к удаленной шине PCIe (обмен данными между различными узлами NUMA).
Благодаря этой функции приложения, разработанные на основе NUMA, должны максимально избегать удаленного доступа к памяти между узлами. Поскольку доступ к памяти между узлами не только медленный по скорости связи, но также может потребоваться согласованность данных в памяти и кеше между различными узлами. Переключение между несколькими потоками между различными узлами является дорогостоящим.
Хотя NUMA обладает лучшей масштабируемостью процессора, чем SMP, он не обеспечивает полной изоляции основной памяти. Поэтому NUMA далека от достижения уровня неограниченного расширения и может поддерживать не более сотен процессоров. Это компромисс для достижения более высокой производительности параллелизма: один узел может быть не в состоянии полностью удовлетворить требования множественного параллелизма, и переключение потоков между множеством узлов является компромиссным решением. Такой подход позволяет NUMA иметь определенную степень масштабируемости и больше подходит для серверных приложений.
Структура массивно-параллельной обработки MPP
MPP (Massive Parallel Processing, массовая параллельная обработка)Поскольку ограничение масштабируемости NUMA состоит в том, что изоляция ресурсов (например, памяти, модулей межсоединений) не полностью реализована, решение MPP состоит в предоставлении полностью независимого ресурса для процессора.

MPP имеет несколько действительно независимых модулей SMP. Каждый модуль SMP является эксклюзивным и может получать доступ только к своей локальной памяти, вводу-выводу и другим ресурсам. Блоки SMP подключаются через сеть межузловых соединений (перераспределение данных, перераспределение данных) Это полностью разделяемая (Share Nothing) структура вычислительной платформы CPU.

Типичной особенностью MPP является«Несколько блоков SMP, без разделения между блоками», Кроме того, структура MPP имеет следующие характеристики:
Благодаря функции полной изоляции ресурсов масштабируемость MPP является наилучшей, теоретически ее расширение не ограничено. Современная технология позволяет реализовать соединение 512 узлов и тысяч процессоров, которые в основном используются в мэйнфреймах.
NUMA в Linux
Основная концепция объекта

(Одна розетка 4 ядра)
Сдерживающие отношения: NUMA Node > Socket > Core > Thread

EXAMPLEНа приведенном выше рисунке показана топология NUMA. Это означает, что сервер имеет 2 узла numa, каждый узел содержит сокет, каждый сокет содержит 6 ядер, а каждое ядро разделено на два потока, поэтому общий процессор сервера = 2 * 1 * 6 * 2 = 24 шт.
Стратегия планирования NUMA
Каждый процесс или поток Linux продолжит политику NUMA родительского процесса и назначит ей приоритет в узле NUMA. Конечно, если политика NUMA позволяет, процесс также может вызывать ресурсы на других узлах.
Существует два типа стратегий выделения процессоров NUMA:
Стратегия выделения памяти NUMA имеет следующие 4 типа:
Получить топологию NUMA хоста
Скрипт bash:
OUTPUT:
Сценарий Python, официально предоставленный DPDK:
NUMA близость, достигнутая Nova
До версии Icehouse libvirt.xml, определенный Nova, не учитывал ситуацию с Host NUMA. В результате Libvirt по умолчанию может получать ресурсы ЦП / памяти через узлы NUMA, что приводит к снижению производительности гостя. Openstack добавляет функцию NUMA в версию Juno. Пользователи могут связать vCPU / память гостя с узлом хоста NUMA для повышения производительности гостя.
Концепция объекта NUMA, определенная Nova
В дополнение к базовым концепциям NUMA, упомянутым выше, Nova также настраивает некоторые концепции объектов:
NOTE 1Определение vCPU и pCPU несколько запутанно и просто для понимания: виртуальная машина на самом деле является процессом хост-машины, а ЦП виртуальной машины на самом деле является специальным потоком в процессе хост-машины. Понятие pCPU и vCPU введено, чтобы позволить логике верхнего уровня скрыть сложность топологии NUMA машины.
NOTE 2: Внедрение объекта «Близкие по потоку потоки» должно поддерживать функцию физической привязки ЦП независимо от того, включена ли на сервере гиперпоточность или нет.
Фон для достижения близости NUMA
Лицензия на выпуск операционной системы (Licensing)
В соответствии с различными лицензиями на выпуск операционной системы максимальное количество сокетов, которые может поддерживать операционная система, может быть строго ограничено, а количество виртуальных машин, которые могут быть запущены на сервере, также ограничено. Следовательно, в настоящее время следует более предвзято использовать ядро в качестве vCPU вместо сокета.
Из-за влияния лицензии пользователям рекомендуется выбирать наилучшую топологию ЦП для запуска образа при загрузке изображения в Glance. Администратор облачной платформы также может изменить значение топологии ЦП по умолчанию, чтобы пользователи не превышали лимит лицензии. Другими словами, для виртуальной машины с 4 vCPU, если используемое значение по умолчанию ограничивает максимальный сокет до 2, вы можете установить его ядро равным 2. (При условии, что количество сокетов не превышает ограничение, виртуальная машина также может достигать 4 ядра. эффект).
NOTEАдминистраторы OpenStack должны соблюдать требования лицензирования операционной системы и ограничивать топологию ЦП, используемую виртуальными машинами (например, max_sockets == 2). Установка параметров топологии ЦП по умолчанию гарантирует, что образ GuestOS может соответствовать лицензии, не требуя от каждого пользователя индивидуальной настройки свойств изображения.
Влияние топологии процессора на производительность
Топология процессора хоста оказывает большое влияние на его собственную производительность (производительность).
Одноядерная одноядерная топология (одноядерная структура): Сокет только интегрирует ядро. Для многопоточных программ права на выполнение ЦП в основном получены с помощью ротации временных интервалов, фактически они выполняются последовательно и не выполняются параллельно. 
Одноядерная многоядерная топология (многоядерная структура): Сокет объединяет несколько горизонтально симметричных (зеркальных) ядер, а ядра взаимодействуют через внутреннюю шину данных ЦП. Для многопоточных программ реальное параллельное выполнение может быть достигнуто через несколько ядер. Однако для программ с числом одновременных потоков или числом потоков больше, чем число ядер, многоядерная структура имеет проблему переключения потоков (контекста). Это принесет некоторые накладные расходы, но, к счастью, используется внутренняя шина данных ЦП, поэтому накладные расходы будут относительно низкими. Кроме того, поскольку несколько ядер зеркально отражены по горизонтали, каждое ядро имеет свой собственный кэш.В некоторых сценариях, где требуются общие данные (общие данные, вероятно, будут кэшироваться), существует согласованный многоядерный данные кэша. Сексуальные проблемы, это также принесет некоторые накладные расходы. 
Одноядерная топология с несколькими сокетами: Связь между несколькими сокетами осуществляется через шину на материнской плате и интегрирована в единую вычислительную платформу. Каждый сокет имеет независимую внутреннюю шину данных и кэш. Для многопоточных программ параллельное выполнение может быть достигнуто через несколько сокетов. В отличие от многоядерной топологии с одним сокетом, переключение потоков в одноядерной топологии с несколькими сокетами и обмен данными между сокетами используют внешнюю шину, поэтому издержки будут намного выше, а задержка будет больше, чем при использовании внутренней шины данных ЦП. Конечно, в сценариях, где используются общие данные, также существует проблема согласованности кэша между несколькими сокетами. Узкое место в производительности топологии с несколькими сокетами заключается в стоимости обмена данными ввода / вывода между сокетами. 
Топология с гиперпоточностью (Hyper-Threading)Виртуализировать ядро в несколько потоков (логических процессоров) и понять, что ядро также может выполнять несколько потоков параллельно. Поток имеет свои собственные регистры и логику прерываний, но исполнительный блок (логический операционный блок ALU) и кэш-память совместно используются потоками, поэтому повышение производительности относительно ограничено, но оно также очень экстремально.
Многопоточная многоядерная гиперпоточная топология: Существует несколько сокетов, каждый сокет содержит несколько ядер, а каждое ядро имеет несколько потоков. Он является мастером вышеупомянутых типов топологии, имеет лучшую производительность и самые передовые технологии и обычно используется в серверных продуктах корпоративного уровня, таких как системы вычислительных платформ MPP и NUMA.
NOTE 1: Многопоточная «многоядерная одноядерная топология». Сокеты должны взаимодействовать через внешнюю шину для совместной работы. Общие данные между потоками, выполняющимися на разных сокетах, могут храниться в разных сокетах одновременно, поэтому необходимо обеспечить данные разных кэшей. консистенция. Существуют такие проблемы, как высокая нагрузка на связь, высокая нагрузка на переключение потоков, сложность поддержания согласованности данных в кэш-памяти, большая площадь для нескольких сокетов и сложная интегрированная технология подключения.
NOTE 2: Многопоточность «Single Socket Multi-Core Topology», каждое ядро обрабатывает один поток и поддерживает параллелизм. Он обладает преимуществами небольших накладных расходов на связь между несколькими ядрами и небольшим пространством Socket. Однако, когда необходимо запустить несколько «больших программ» (одна программа может заполнить память, кэш-память и ядро), это эквивалентно нескольким крупным программам, которым необходимо использовать ЦП посредством разделения времени. В это время потребление контекстной (инструкция, замена данных) переключения между программами будет огромным. Следовательно, «многоядерная топология с одним сокетом» станет очень неэффективной в многозадачной среде с высокой степенью параллелизма и высокой оперативной памятью (большие программы монополизируют Socket).
Таким образом, для сценариев небольших приложений рекомендуется использовать «одноядерную многоядерную топологию», такую как персональный ПК Dell T3600 (одноядерный процессор 6, поддержка гиперпоточности поддерживает виртуализацию из 12 логических ядер); Для сценариев (например, на стороне сервера облачных вычислений) рекомендуется использовать комбинацию «Multi Socket Single Core» или даже «Multi Socket Multi Core Hyper-Threading» для назначения каждой программы одному ЦП и назначения каждого потока программы одному ЦП. ядро.
Влияние архитектуры процессора на производительность

Проблемы с видимостью памятиЭта проблема не возникает в случае одного процессора или одного потока. Но в многопоточной среде, поскольку потоки будут выделяться для выполнения разными ядрами, Core1 и Core2 могут одновременно загружать значение расположения в основной памяти в свой кэш первого уровня, а Core1 изменяет После владения значением в кэше первого уровня, оно не обновляет соответствующее значение в основной памяти. Таким образом, для Core2 Core1 никогда не увидит изменение значения, что приводит к невозможности гарантировать безопасность параллелизма.
Проблемы согласованности кэша: Если Core1 и Core2 одновременно загружают значение в основной памяти в свой кэш первого уровня, Core1 изменит значение и сделает недействительным значение в Core2 через шину BUS. После того, как Core2 обнаружит, что значение в кэше первого уровня недопустимо, оно получит последнее значение из основной памяти через шину BUS. Однако полоса пропускания связи шины является фиксированной, и синхронизация данных кэша первого уровня каждого ЦП через шину будет генерировать большой объем трафика, и шина стала узким местом производительности. Вы можете уменьшить трафик согласованности кэша, уменьшив конкуренцию за синхронизацию данных.
Влияние гиперпоточности на производительность
В настоящее время многие приложения, такие как Web App, в основном используют многопользовательский дизайн.С помощью Hyper-Threading, два Workers планируют разные потоки под одним и тем же ядром, поскольку потоки совместно используют Cache и TLB (Translation Lookaside Buffer), это может значительно снизить накладные расходы на переключение потоков Workers., Кроме того, когда рабочий не занят, Hyper-Threading позволяет другим рабочим сначала использовать физические вычислительные ресурсы, чтобы улучшить общую пропускную способность ядра.

Как видно из приведенного выше рисунка, в сценарии, где применяется технология HT, ситуация простоя исполнительного блока процессора эффективно снижается, и два потока Thread 1 и Thread 2 подвергаются перекрестной обработке.
Однако из-за конкуренции между потоками за физические ресурсы выполнения ядра задержка выполнения одного потока соответственно возрастет, и скорость отклика будет не такой хорошей, как раньше. Для задач с интенсивным использованием ЦП, когда существует конкуренция с гиперпоточностью, вычислительная мощность гиперпоточности составляет около 60% физического ядра (неофициальные данные).

NOTE:
Возвращаясь к сценарию приложения виртуальной машины, когда мы запускаем две виртуальные машины 1 vCPU на хосте vSphere ESXi, привязываемся к двум потокам ядра, выполняем задачи компиляции с высокой вычислительной мощностью внутри виртуальной машины и обеспечиваем Внутренняя загрузка ЦП виртуальной машины составляет около 50%. На хосте ESXi коэффициент использования двух потоков составляет около 45%, но загрузка ядра достигла 80%.Можно видеть, что проблема конкуренции с гиперпоточностью вызовет серьезную потерю производительности виртуальных машин, работающих с приложениями, требующими большого объема вычислений.
Поэтому следует отметить, что если у пользователей предъявляются высокие требования к производительности для виртуальных машин, то виртуальный процессор виртуальной машины не должен запускаться в потоке, а должен запускаться в сокете или ядре. Для вычислительного узла с включенной Hyper-Threading должен быть предусмотрен механизм для фильтрации или абстрагирования потоков в «ядро», что означает введение потока Siblings.
NUMA Topology
Современные серверы в основном поддерживают топологию NUMA.Как уже упоминалось выше, основными факторами, влияющими на применение архитектуры NUMA, являются высокая пропускная способность доступа к хранилищу, эффективная эффективность кэширования и гибкая схема размещения устройств ввода / вывода PCIe NUMA. Тем не менее, поскольку межузловой удаленный доступ к памяти NUMA имеет не только высокую задержку, низкую пропускную способность и высокое потребление, он также может потребовать решения проблем согласованности данных. Следовательно, неправильная компоновка виртуального ЦП виртуальной машины и памяти на узле NUMA приведет к серьезной трате ресурсов хоста, что приведет к потере любых преимуществ, связанных с памятью и процессорами.Поэтому стандартная стратегия заключается в том, чтобы максимально ограничить виртуальную машину одним узлом NUMA.。
Guest NUMA Topology
Лучше всего ограничить vCPU / Mem виртуальной машины одним узлом NUMA, но что, если количество vCPU и памяти, выделенных для виртуальной машины, превышает ресурсы узла NUMA? В настоящее время должна быть разработана подходящая стратегия для виртуальных машин с большими требованиями к ресурсам, для чего также предлагается концепция топологии гостевой NUMA.
Эти политики могут запрещать создание виртуальных машин за пределами топологии одного узла NUMA или могут позволять виртуальным машинам работать на нескольких узлах NUMA. И когда виртуальная машина мигрирует, эти политики могут быть изменены. Другими словами, когда хост (вычислительный узел) поддерживается, субоптимальная топология NUMA выбирается для временного снижения производительности. Разумеется, проблема топологии NUMA также должна учитывать конкретные сценарии использования виртуальных машин, например, развертывание виртуальных машин NFV приведет к строгой топологии NUMA.
Если виртуальная машина имеет несколько гостевых узлов NUMA, для того чтобы операционная система максимально использовала свои выделенные ресурсы, топология NUMA хоста должна быть представлена виртуальной машине. Позвольте Узлу NUMA Гостевой виртуальной машины связываться с Узлом NUMA Узла хоста. Это может сопоставить большой блок памяти виртуальной машины с памятью хоста и установить соответствие между vCPU и pCPU.
Гостевая топология NUMA фактически разделяет виртуальную машину с большими требованиями к ресурсам на несколько виртуальных машин с небольшими требованиями к ресурсам и связывает несколько гостевых узлов NUMA с различными узлами хоста NUMA. Это связано с тем, что рабочая нагрузка, выполняемая внутри виртуальной машины, также будет соответствовать принципу узла NUMA.Наконечным результатом является то, что рабочая нагрузка виртуальной машины по-прежнему эффективно ограничена узлом узла NUMA. Другими словами, если виртуальная машина имеет 4 виртуальных ЦП и должна охватывать два узла NUMA узла, vCPU 0/1 связан с узлом 1 узла NUMA, а vCPU 2/3 связан с узлом 2 узла NUMA. Затем приложение БД в виртуальной машине назначается для vCPU 0/1, а веб-приложение назначается для vCPU 2/3. Таким образом, потоки приложения БД и веб-приложения всегда ограничиваются одним и тем же узлом узла NUMA. Однако топология гостевой NUMA не обязывает vCPU быть привязанным к конкретному pCPU в соответствующем узле NUMA узла, что может быть неявно выполнено планировщиком операционной системы. Однако, если на хост-машине включена поддержка гиперпоточности, необходимо предоставить виртуальной машине функцию гиперпоточности и связать отношения между vCPU и pCPU в узле NUMA. В противном случае vCPU будет назначен потоку Siblings. Из-за конкуренции с гиперпоточностью производительность намного хуже, чем назначение vCPU для Socket или Core.
NOTE: Если требование Guest vCPU / Mem превышает один узел NUAM узла, то топология гостевого NUMA должна быть разделена на несколько узлов NUMA гостя и сопоставлена с разными узлами NUMA узла соответственно.
Применить сходство NUMA в Nova для создания высокопроизводительных виртуальных машин
Принцип близости NUMA: Все гостевые vCPU / Mems размещены на одном и том же узле NUMA, а локальная память узла NUMA полностью используется, чтобы избежать межузлового доступа к удаленной памяти.
Два способа настройки топологии Guest NUMA:
NOTE: При выборе метода автоматической настройки рекомендуется использовать его вместе hw:numa_mempolicy Атрибут указывает стратегию доступа к Mem для NUMA. Существует два варианта строгого доступа к локальной памяти и свободного предпочтения, которые могут минимизировать сложность параметров конфигурации. И для некоторых проблем архитектуры NUMA для определенных рабочих нагрузок, таких как проблемы «безумия подкачки» MySQL, возможно, предпочтительным будет хороший выбор.
Нова Планировщик будет следить за параметрами hw:numa_nodes Чтобы решить, как сопоставить гостевой узел NUMA. Если этот параметр не задан, то планировщик будет свободно решать, где запускать виртуальную машину, не беспокоясь о том, может ли один узел NUMA соответствовать конфигурации vCPU / Mem в варианте виртуальной машины, но он все равно будет отдавать приоритет выбору узла NUMA. Вычислительный узел ситуации.
NOTE 1: Только когда установлено hw:numa_nodes Задняя, hw:numa_cpus.N с участием hw:numa_mem.N Вступит в силу. Только когда гостевые узлы NUMA имеют асимметричный доступ к vCPU / Mem (количество vCPU и размер Mem между гостевыми NUMA узлами не отражаются), эти параметры необходимо устанавливать.
WARNING:в случае hw:numa_cpus.N с участием hw:numa_mem.N Если значение параметра превышает доступные CPU / Mem самой виртуальной машины, возникает исключение.
EXAMPLEЗадайте для виртуальной машины 4 виртуальных ЦП, 4096 МБ памяти и установите для топологии Guest NUMA значение 2 гостевого узла NUMA:
ПРИМЕЧАНИЕ: numa_cpus указывает серийный номер vCPU, а не pCPU.
Когда виртуальная машина, созданная с использованием этого варианта, используется, драйвер Libvirt наконец завершает сопоставление гостевого узла NUMA с узлом узла NUMA.
В дополнение к настройке топологии Guest NUMA с помощью дополнительных спецификаций Flavor ее также можно настроить с помощью метаданных изображения. например
Обратите внимание, что когда ограничение NUMA зеркала конфликтует с ограничением NUMA Аромата, Аромат имеет преимущественную силу.
NOTE 1: Хост KVM предоставляет подробную информацию о топологии хоста NUMA (например, количество узлов NUMA, общая и свободная память узлов NUMA, общее и свободное ЦП узлов NUMA), но другие платформы операционной системы гипервизора могут не предоставлять эту информацию. Например, VMware может получить неполную информацию о топологии только через vSphere WS API. Таким образом, KVM обладает наивысшей степенью совместимости с функциями соответствия NUMA.
NOTE 2: ResourceTracker службы nova-compute регулярно собирает информацию о топологии хоста NUMA хоста через Hyper Driver.



